Quando você deve confiar em suas previsões? Como um amigo meu já disse, a resposta para essa questão é fácil: nunca (ou quase nunca).
Mas, brincadeiras à parte, para este post fazer sentido, vou reformular a pergunta: quando você deve desconfiar ainda mais das previsões do seu modelo?
Há várias situações em que isso ocorre, ilustremos aqui uma delas.
***
Imagine que você tenha as seguintes observações de x e y.
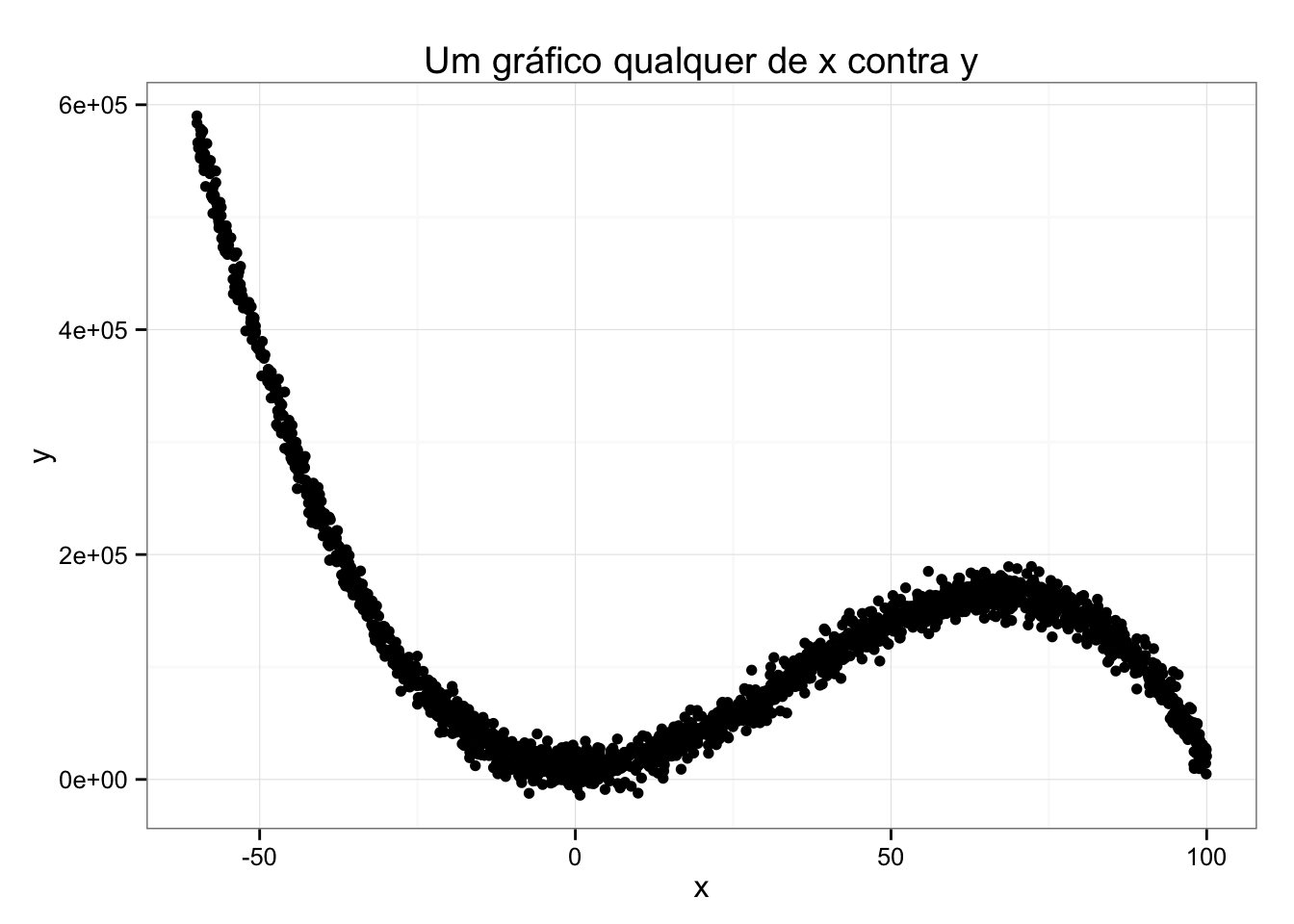
Para modelar os dados acima, vamos usar uma técnica de machine learning chamada Suport Vector Machine com um núcleo radial. Se você nunca ouviu falar disso, você pode pensar na técnica, basicamente, como uma forma genérica de aproximar funções.
Será que nosso modelo vai fazer um bom trabalho?
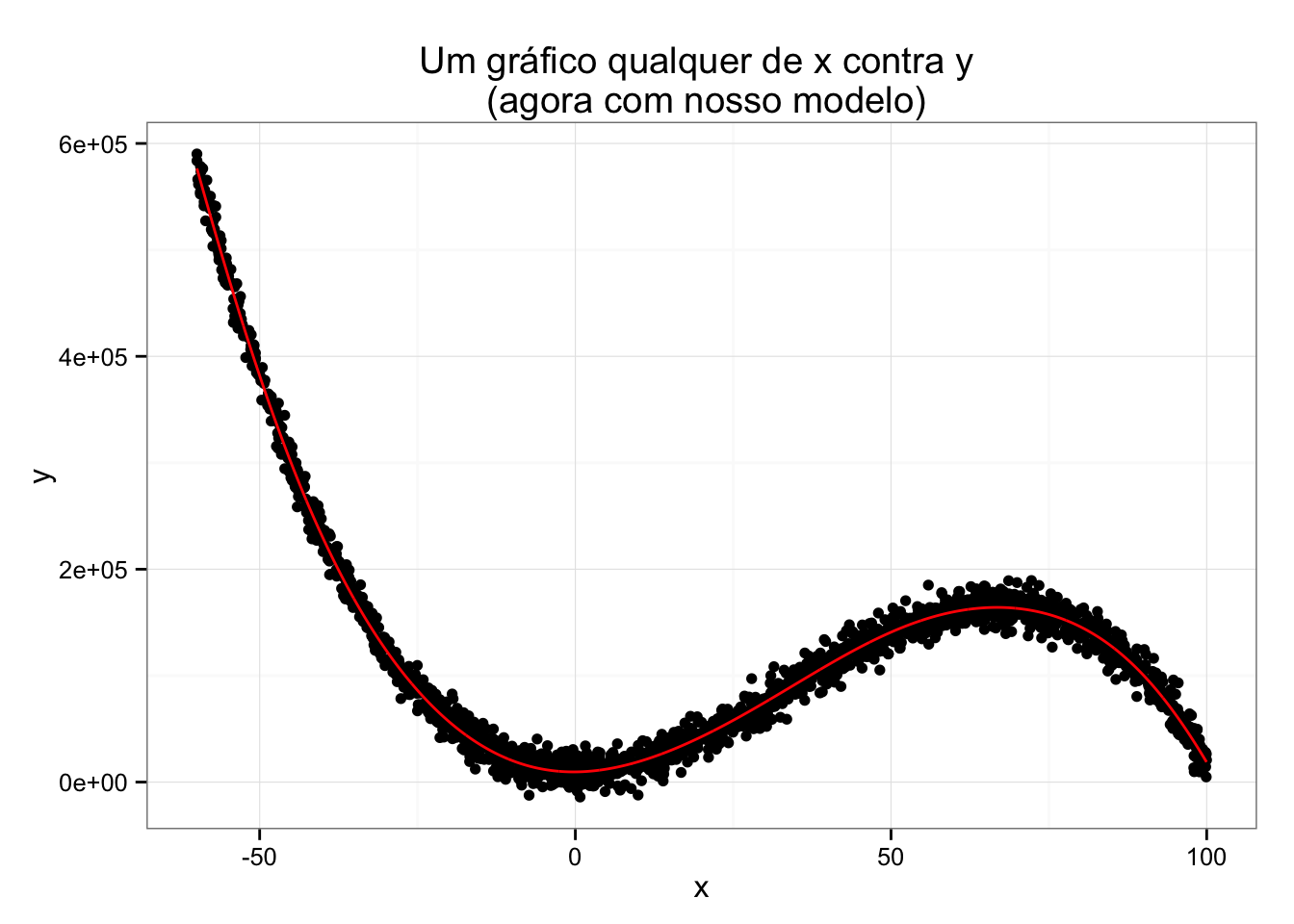
Pelo gráfico, é fácil ver que nossa aproximação ficou bem ajustada! Para ser mais exato, temos um R2 de 0.992 estimado por cross validation (que é uma estimativa do ajuste fora da amostra – e é isso o que importa, você não quer saber o quão bem você fez overfitting dos dados!).
Agora suponha que tenhamos algumas observações novas, isto é, observações nunca vistas antes. Só que essas observações novas serão de dois “tipos”, que aqui criativamente chamaremos de tipo 1 e tipo 2. Enquanto a primeira está dentro de um intervalo de x que observamos ao “treinar” nosso modelo, a segunda está em intervalos muito diferentes.
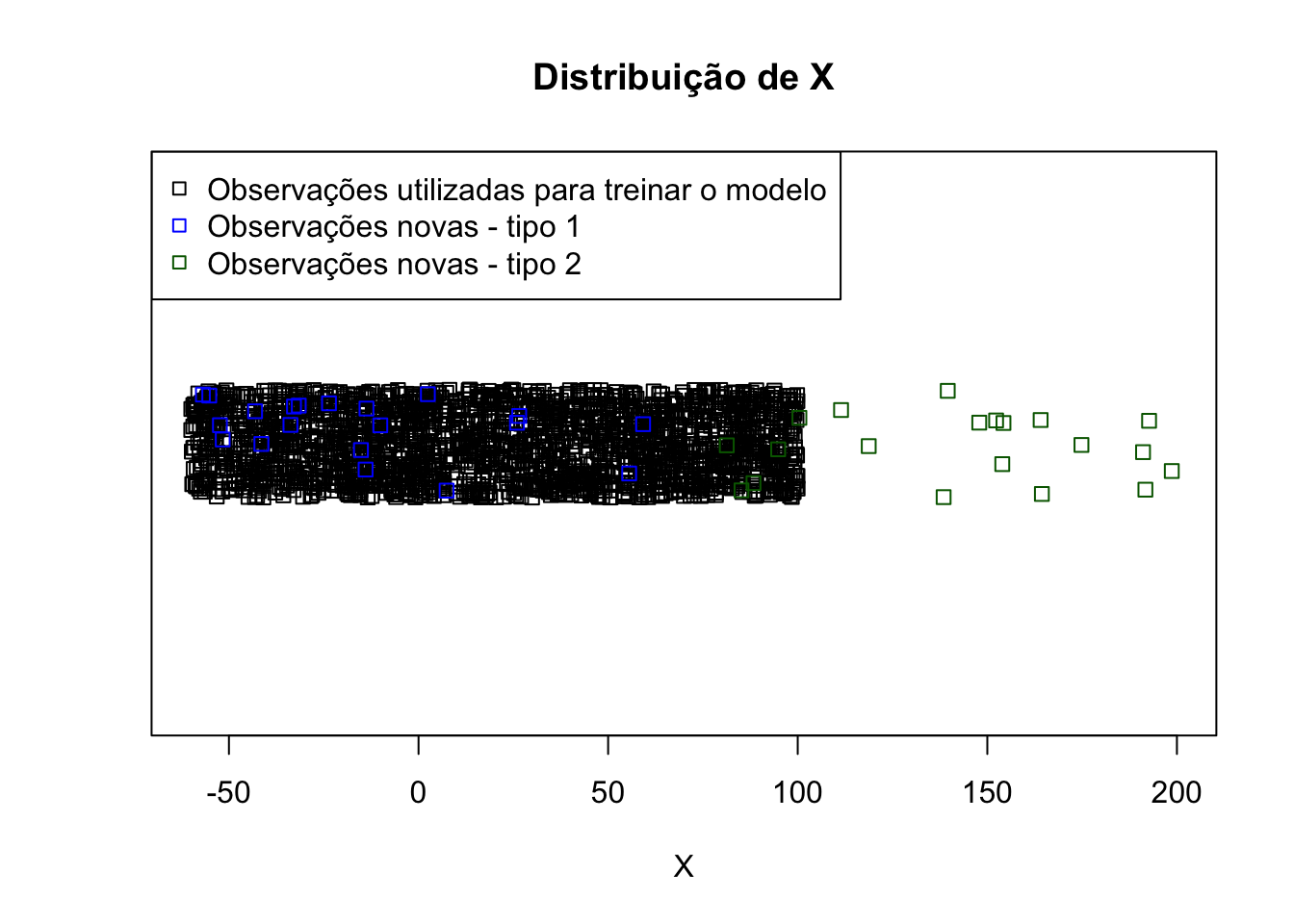
Qual tipo de observação você acha que teremos mais dificuldades de prever, a de tipo 1 ou tipo 2? Você já deve ter percebido onde queremos chegar.
Vejamos, portanto, como nosso modelo se sai agora:
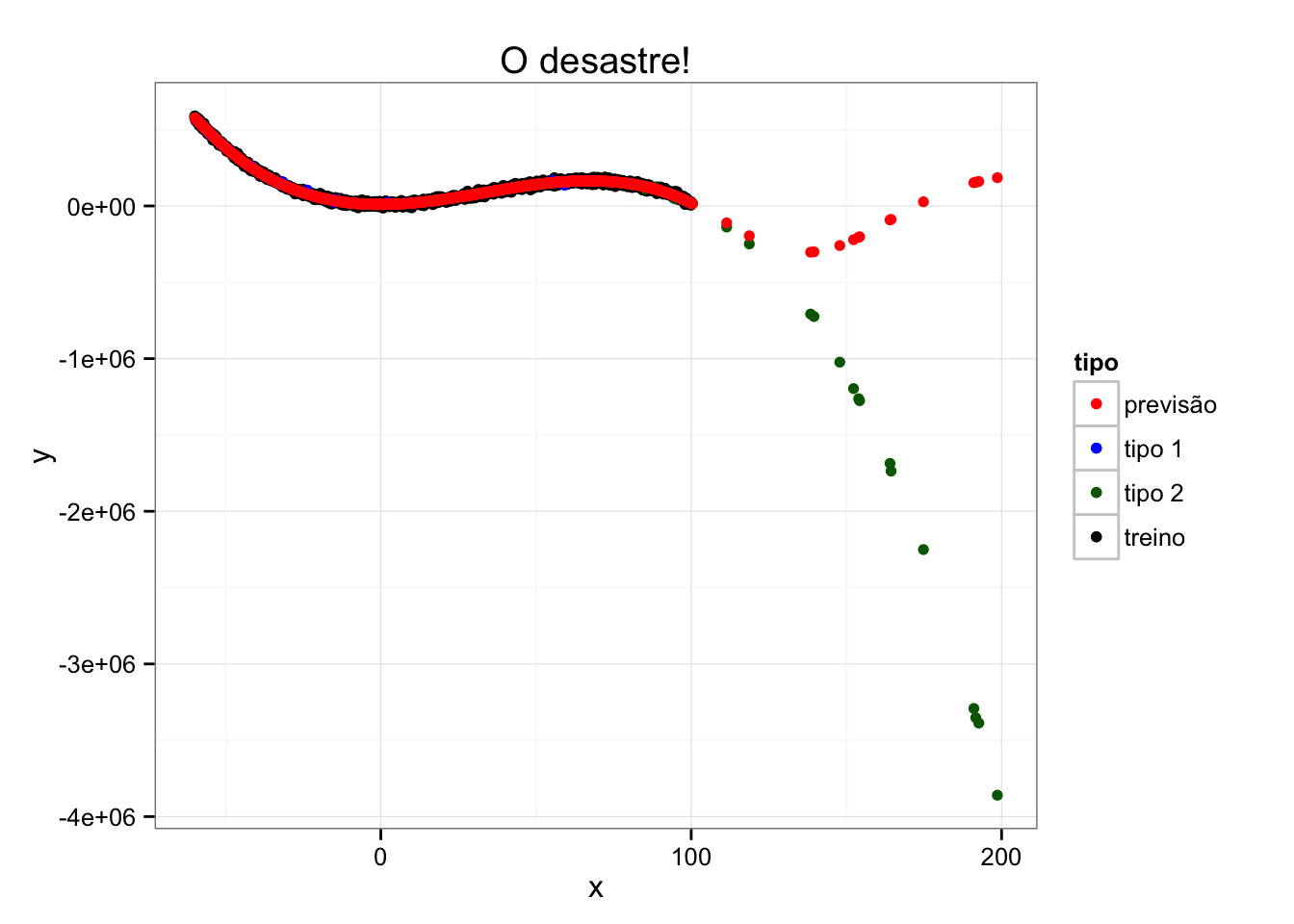
Note que nas observações “similares” (tipo 1) o modelo foi excelente, mas nas observações “diferentes” (tipo 2) nós erramos – e erramos muito. Este é um problema de extrapolação.
Neste caso, unidimensional, foi fácil perceber que uma parte dos dados que gostaríamos de prever era bastante diferente dos dados que usamos para modelar. Mas, na vida real, essa distinção pode se tornar bastante difícil. Uma complicação simples é termos mais variáveis. Imagine um caso com mais de 20 variáveis explicativas – note que já não seria trivial determinar se novas observações são similares ou não às observadas!
Quer aprofundar mais um pouco no assunto? Há uma discussão legal no livro do Max Kuhn, que já mencionamos aqui no blog.

Conserta o título dos gráficos. 🙂
CurtirCurtir
Valeu, nem tinha reparado!
CurtirCurtido por 1 pessoa
É possível acessar o script?
CurtirCurtir
Para gerar o “tipo 2” você usou o mesmo processo gerador do dados “dentro da amostra”?
Se a resposta é não (e o processo gerador do tipo 1 é o mesmo dos dados dentro da amostra) então o modelo é excelente.
Nesse caso, embora você tenha colocado as duas coisas juntas no mesmo gráfico eles são processos diferentes e o que importa é que você está estimando certo o processo interessante.
Se o processo gerador é o mesmo para ambos, então o seu ponto foi bem colocado..
CurtirCurtir
Só um adendo. Eu falei “estimando certo o processo interessante” mas o mais adequado é dizer que o seu forecast é adequado.
CurtirCurtir
Isso Lyra, o processo gerador dos dados é o mesmo nos dois casos (tipo 1 e tipo 2).
CurtirCurtir