Recomendações
Berkeley Initiative for Transparency in the Social Sciences (BITSS) – 2016 meeting
Ontem e hoje houve a reunião da Berkeley Initiative for Transparency in the Social Sciences (BITSS). Além de anunciados os vencedores do último Leamer-Rosenthal Prizes, houve várias apresentações interessantes sobre métodos quantitativos em ciências sociais.
Os dois dias foram filmados e estão disponíveis no Youtube.
Dia 1:
Dia 2:
Computer age statistical inference e The undoing project
Segue minha sugestão de leitura para as férias de final de ano: um livro de estatística e outro de psicologia/economia comportamental.

Para falar a verdade, ainda não os li, mas já recomendo.
O primeiro livro é do Michael Lewis, sem dúvida um dos melhores cronistas da atualidade (entre outros ótimos livros: Flash Boys, Moneyball, The Big Short). Lewis conta a história da vida e amizade dos dois psicólogos israelenses que começaram a revolução da economia comportamental:Daniel Kahneman e Amos Tversky. Para quem ainda não conhece o trabalho da dupla, vale a pena recomendar de novo o já clássico Thiking, Fast and Slow.
O segundo livro é o mais novo lançamento dos estatísticos Bradley Efron e Trevor Hastie. Os dois fazem um tour histórico e técnico pela revolução computacional dos últimos 60 anos da estatística. Para quem está começando na área, Efron é mais conhecido por seu trabalho no bootstrap; Trevor (junto com Tibshirani), por seus trabalhos em GAMs e modelos esparsos entre outros. Trevor também é co-autor dos já famosos Elements of Statistical Learning e sua recente versão baby An introduction to Statistical Learning — ambos com versões gratuitas na internet (aqui e aqui).
Elon Musk’s Big Fucking Rocket

Economistas como engenheiros? Ou, leia Who Gets What — and Why
Viajar faz bem, nem que seja para nos forçar a ler na sala de espera. No caminho para Los Angeles finalmente tive tempo para terminar o livro do Alvin Roth Who Gets What – and Why. Confesso que por alguma razão — que não sei bem precisar, talvez pela pretensão do título — estava receoso. Mas como admiro o trabalho do Roth não poderia deixar de ler. Ainda bem. Esse é, sem dúvida, um dos melhores livros de economia (para o público geral) publicados recentemente.
Quando Alvin Roth ganhou o Nobel (ok, o Prêmio dado pelo Banco Central Sueco em memória de Alfred Nobel) os temas “desenho de mercados” e “economistas como engenheiros” vieram à tona e vimos muita coisa absurda escrita por aí — isso para dizer o mínimo. Não vou compartilhar os links para poupar essas pessoas que talvez deixaram-se levar mais por preconceitos e velhos dogmas do que pela razão. Criticaram provavelmente sem conhecer a literatura e talvez hoje tenham noção do que escreveram.
Mas, na verdade, esse tipo de reação não era inesperado. A ideia de uma economia parecida com uma “engenharia” pode parecer aviltante para muitos colegas, sejam liberais ou intervencionistas. Ora, afinal de contas, a economia é uma ciência social, não é mesmo!? Como podem economistas agirem como engenheiros? O problema é que muitos economistas/cientistas sociais estão acostumados a discutirem de maneira solta e informal pretensas “grandes perguntas” e interpretam qualquer assertiva dentro desse contexto. Quando você lida com questões do naipe “o planejamento estatal é bom ou ruim para a economia?” pensar em economistas como engenheiros certamente vai acender um alerta.
Mas não se trata disso. A ideia aqui é simplesmente resolver problemas reais e prementes presentes em “mercados” (no sentido amplo do termo), seja na esfera pública ou privada — daí o “engenheiro”. Suponha que você tenha uma empresa como o Google e queira saber a melhor forma de vender espaços para os anúncios. Ou que você tenha uma empresa como o eBay e queira saber a melhor forma de fazer com que compradores e vendedores saibam quem tem uma boa reputação de verdade. Ou, ainda, que você trabalhe para o governo e queira reformular o sistema que distribui alunos entre as escolas públicas. Como abordar essas questões?
A coisa não para aí — leilões de espectro, regras para negociações nas bolsas de valores, mecanismos para doações de rins, alocação de médicos/advogados recém-formados no mercado de trabalho… todos problemas importantes e reais do dia-a-dia com uma alta demanda por pessoas com a capacidade analítica de solucioná-los. E nisso a economia pode ajudar bastante (principalmente teoria dos jogos). O Vale do Silício, por exemplo, tem espaço para profissionais com essa formação.
A maioria dos economistas não vai trabalhar diretamente com “as grandes questões” e um nicho de atuação importante e crescente do economista é entender melhor como mercados funcionam, como e por que alguns mercados funcionam melhor do que outros, e como podemos atuar para resolver problemas reais desses mercados. O livro do Roth é um ótimo lugar para começar a pensar sobre esse assunto.

Inferência causal e Big Data: Sackler Big Data Colloquium
Uma série de palestras interessantes do Sackler Big Data Colloquium:
Hal Varian: Causal Inference, Econometrics, and Big Data
***
Leo Bottou: Causal Reasoning and Learning Systems
***
David Madigan: Honest Inference From Observational Database Studies
***
Susan Athey: Estimating Heterogeneous Treatment Effects Using Machine Learning in Observational Studies
Impactos de Contágio do Setor Real no Sistema Financeiro
O novo Relatório de Estabilidade Financeira (REF) do Banco Central do Brasil foi publicado ontem. Dentre várias informações interessantes, neste relatório foi publicado um boxe que discute a mensuração de impactos de contágio do setor real da economia no sistema financeiro.
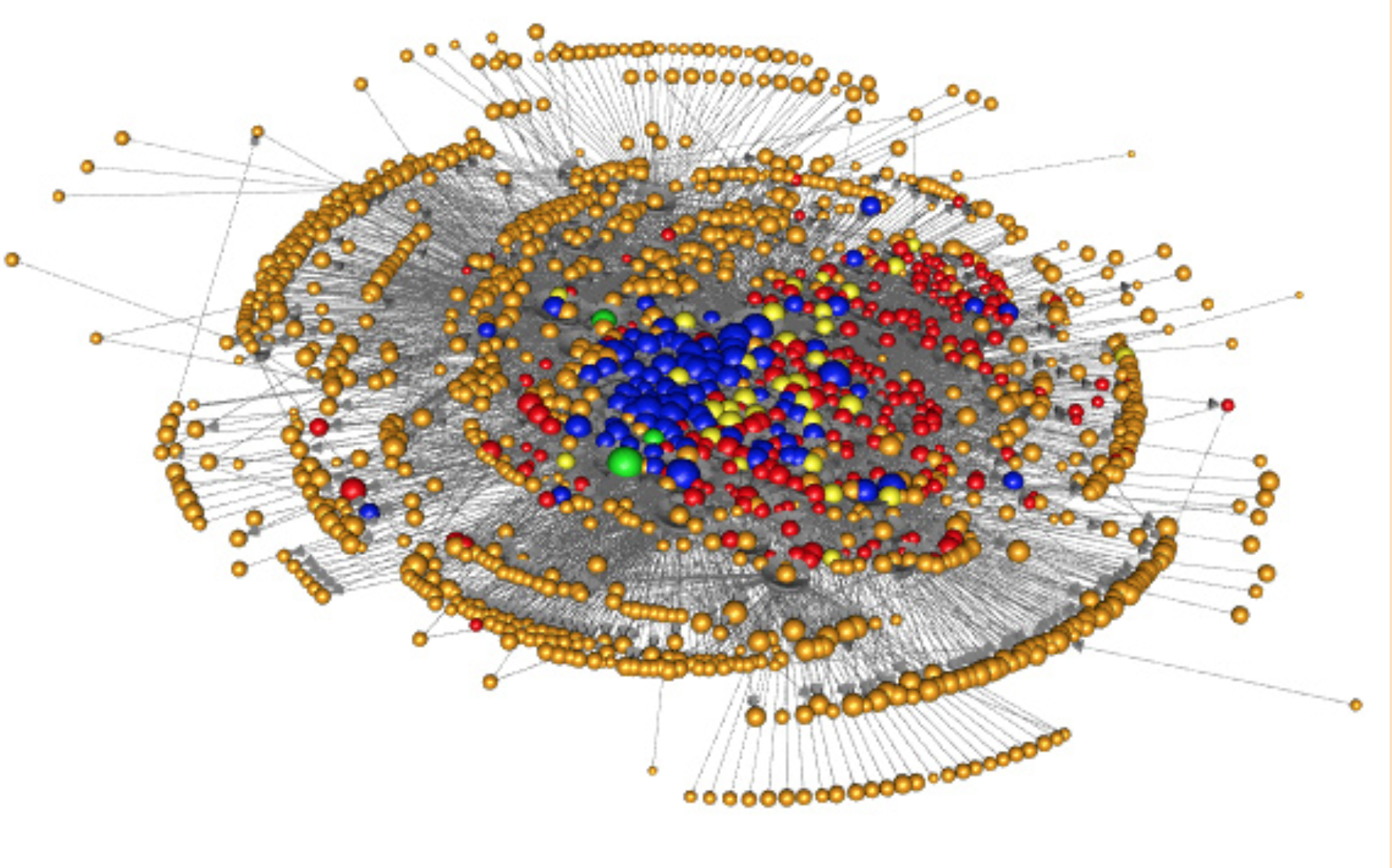
Resumidamente, a partir de uma rede de conexões do setor real, o BCB simula um processo de contágio e verifica os possíveis afetados bem como seus empregados. Com esses dados em mão, o BCB mapeia as exposições do SFN a essas empresas e funcionários e, em seguida, simula um segundo processo de contágio no setor financeiro.
A rede do setor real (representada abaixo) foi montada a partir dos dados de TED entre as empresas. Na figura abaixo, “cada esfera representa um grupo econômico. O tamanho delas é proporcional à sua participação no fluxo de transferências do SPB. As cores das arestas refletem a importância do fluxo de TED para a empresa recebedora – quanto mais vermelho, maior a importância e maiores as chances de contágio. Nem todos os grupos estão representados.” (BCB, 2015)

Já a rede do setor financeiro é montada a partir das exposições que os conglomerados financeiros possuem entre si. Na figura abaixo, “as esferas azuis referem-se aos Bancos Múltiplos e Comerciais, as verdes, aos Bancos de Desenvolvimento, as vermelhas, aos Bancos de Investimento, as laranjas, às Cooperativas de Crédito e Financeiras, e as amarelas, às Corretoras e empresas de leasing.” (BCB, 2015)
 Vale a pena tirar um tempo e conferir o REF!
Vale a pena tirar um tempo e conferir o REF!
Foda-se a nuance, entrevista com Alvin Roth, erro de medida no desemprego e Machine Learning no Airbnb.
Algumas leituras e vídeos interessantes
– Kieran Healy mandando um fuck nuance. (Abstract: Seriously, fuck it).
– Entrevista de Alvin Roth no Google:
– Sobre a acurácia das variáveis econômicas: quanto é o desemprego da China? Nessa linha, qual é a medida adequada para “desemprego”? Veja uma discussão interessante para o caso dos EUA no Econbrowser.
– Como o Airbnb usa Machine Learning?
Replicação de 100 estudos de psicologia: efeitos reduzidos pela metade, apenas 47% com magnitudes dentro do intervalo de confiança
O pessoal do Open Science Framework acabou de concluir um trabalho hercúleo: durante mais de 3 anos, juntaram 270 colaboradores para realizar 100 replicações de 98 artigos de psicologia. Todos os materiais do projeto, para cada replicação, encontram-se disponíveis no site, inclusive os códigos em R!
E quais os resultados? Os efeitos replicados tiveram a magnitude estimada reduzida pela metade quando comparados com os efeitos originais. Apenas 36% das replicações alcançaram “significância” estatística (p-valor menor do que 5%) e apenas 47% dos efeitos originais ficaram dentro do intervalo de confiança de 95% das replicações. Supondo que não exista viés de seleção nos estudos originais (o que é difícil de acreditar, considerando os resultados acima), uma meta análise combinando os resultados indica apenas 68% dos efeitos como “significantes”.
Essa é uma iniciativa fantástica, é ciência como deve ser feita. E que venham mais replicações, para termos estimativas mais precisas, sem viés de publicação, do tamanho e da incerteza ao redor desses efeitos.
PS: Em economia, provavelmente nossa situação é ainda pior: a maior parte de nossos estudos é baseada em dados observacionais.

