A crise de replicabilidade obriga Kahneman a rever sua posição. Algo louvável diante de tantos pesquisadores que insistem em continuar no erro:

PS: isso é um comentário do Daniel Kahneman neese post aqui.
A crise de replicabilidade obriga Kahneman a rever sua posição. Algo louvável diante de tantos pesquisadores que insistem em continuar no erro:
PS: isso é um comentário do Daniel Kahneman neese post aqui.
Segue minha sugestão de leitura para as férias de final de ano: um livro de estatística e outro de psicologia/economia comportamental.

Para falar a verdade, ainda não os li, mas já recomendo.
O primeiro livro é do Michael Lewis, sem dúvida um dos melhores cronistas da atualidade (entre outros ótimos livros: Flash Boys, Moneyball, The Big Short). Lewis conta a história da vida e amizade dos dois psicólogos israelenses que começaram a revolução da economia comportamental:Daniel Kahneman e Amos Tversky. Para quem ainda não conhece o trabalho da dupla, vale a pena recomendar de novo o já clássico Thiking, Fast and Slow.
O segundo livro é o mais novo lançamento dos estatísticos Bradley Efron e Trevor Hastie. Os dois fazem um tour histórico e técnico pela revolução computacional dos últimos 60 anos da estatística. Para quem está começando na área, Efron é mais conhecido por seu trabalho no bootstrap; Trevor (junto com Tibshirani), por seus trabalhos em GAMs e modelos esparsos entre outros. Trevor também é co-autor dos já famosos Elements of Statistical Learning e sua recente versão baby An introduction to Statistical Learning — ambos com versões gratuitas na internet (aqui e aqui).
Hoje descobri que é possível fazer o download de todo seu histórico de buscas no Google. TODO seu histórico de TUDO o que você busca no Google. Já que a opção está disponível, por que não dar uma olhada nos dados?
Por alguma razão meu histórico só vai até 2014 — acredito que tenha deletado o histórico anterior — então no meu caso temos apenas dois anos de dados para analisar (não vou considerar 2016 aqui pois o ano ainda não terminou). Além disso, esses dados certamente não contemplam tudo o que pesquisei na internet neste período, porque: (i) além do Google eu uso o DuckDuckGo; e, (ii) muitas vezes não estou logado quando faço pesquisas no próprio Google.
Feitas as ressalvas anteriores, a primeira coisa que tentei montar foi uma nuvem com as palavras mais utilizadas nas buscas. Em 2014 e 2015, segundo o registro do google, fiz aproximadamente 19 mil buscas, utilizando aproximadamente 69 mil palavras-chave. Após remover algumas “stopwords” em inglês e português — isto é, preposições, artigos etc — fiz uma nuvem com aquelas palavras que representam cerca de 20% da frequência total, e o resultado foi o seguinte:

Não tem muita surpresa aí. Previsivelmente, “R” foi a palavra chave mais utilizada, seguida de “package”, “statistics”, “Mac”, “Data”, “Los Angeles”, “UCLA” entre outras.
Após verificar as palavras mais utilizadas, procurei ver se encontrava alguns padrões nos meus hábitos de busca. Primeiramente, calculei a média de buscas por dia da semana. Nesses dois anos, as buscas parecem ter alcançado seu pico de segunda a quarta:
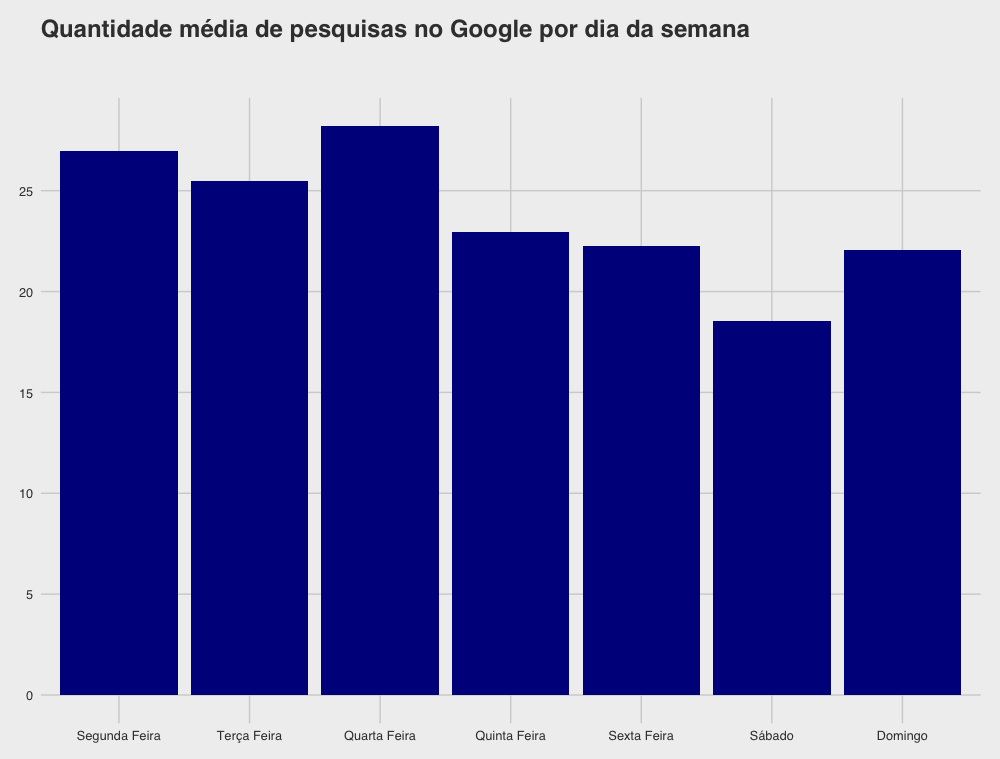
Em seguida calculei a média por hora. Tirando a madrugada e o início da manhã, não parece existir diferença significativa entre os horários. Há, contudo, um problema com essa informação: elas estão no horário brasileiro. Como estive fora do país em certas datas, isso distorce o horário original de algumas pesquisas — e ainda não descobri como consertar esse problema de maneira automática.
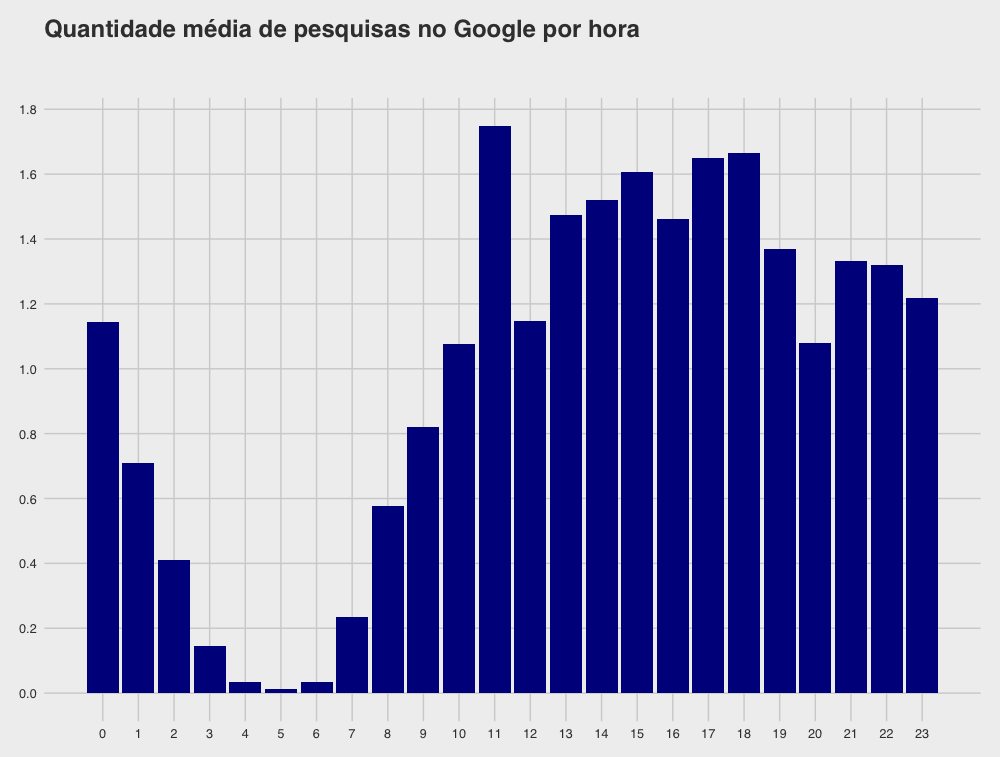
Essa questão das viagens para fora do país suscitou outra pergunta: o total de buscas no Google Maps altera quando estou viajando? A princípio, diria que sim, e é isso o que o gráfico a seguir mostra, com algumas viagens destacadas:

Isto é, pelo menos neste caso, é muito fácil identificar viagens utilizando apenas a série histórica do total de buscas do Google Maps.
Para finalizar, montei um gráfico com a média de pesquisas por hora, separados por dia da semana e ano, mas não parece ter havido mudança relevante entre os padrões de 2014 e 2015.

Quer analisar seus dados também?
Para fazer o download dos dados, basta seguir essas instruções. Os dados virão em um arquivo zip com vários arquivos no formato JSON. Para tratá-los, você pode se basear no script de R que coloquei aqui.
PS: É um pouco assustador perceber que, com análises bastante simples de dados de busca, já é possível inferir bastante coisa sobre os hábitos de uma pessoa.
Fazia algum tempo que não descobria um blog tão bom quanto o Data Colada!
Em especial destaco esse post que discute a falha na replicação de um estudo famoso sobre posições corporais e níveis de testosterona e cortisol (o vídeo do TED sobre o estudo tem mais de 26 milhões de exibições):

Detalhe que ao final do post há comentários dos autores tanto do artigo original, quanto da réplica. E o post também discute o uso de curvas de p-valor para esse caso (há um web-app para construir as curvas de p-valor). Muito bacana.
Flávia Ávila me avisou do site Economia Comportamental, que busca difundir a área no Brasil, e reune informações sobre cursos, vídeos, grupos de pesquisa entre outras coisas interessantes. A página também tem um blog e já conta com diversos colaboradores.
A iniciativa é louvável, pois esta é uma área de pesquisa que ainda está carente de divulgação e publicações no país. Àqueles que publicam sobre o tema por aqui, sugiro entrar em contato com a Flávia para divulgar o trabalho. E para quem tem interesse no tema, vale a pena fazer uma visita!
Alguns links interessantes
1. No final do ano, saíram os microdados da Pesquisa Nacional de Saúde.
2. Também saiu a Pesquisa Brasileira de Mídia 2015.
3. Quanto o comportamento dos outros te influencia?
Pedro Gardete, professor de Stanford, fez a seguinte pergunta: se um passageiro que você não conhece, sentado ao seu lado, compra algo, o quanto isto aumenta probabilidade de você comprar também? Como ele possuía dados das reservas dos vôos, além de excluir amigos que voavam juntos, pôde controlar outros fatores. Foram analisadas 65.525 transações, em 1.966 vôos, totalizando mais de 257 mil passageiros.
4. Para finalizar, um cartoon. Mais uma boa do SMBC:

Parece que Sérgio Almeida e Mauro Rodrigues, do Economistas X, estão com um paper bacana no forno: coletar os próprios dados não é tarefa fácil, confiram no post algumas das agruras pelas quais os dois passaram!
PS: sou partidário da idéia de que a coleta de dados interessantes vale um paper por si só. E, claro, que os dados sejam abertos ao público!
Peter Singer, Paul Bloom e Dan Ariely irão discutir agora, ao vivo, suas pesquisas sobre desonestidade, moralidade e ética.
O time de análise de dados do Facebook fez uma série de 6 posts sobre o valentine’s day (dia dos namorados) nos Estados Unidos.
Recomendo fortemente a leitura de todos. O posts tratam dos seguintes temas:

Os dados confirmam aquilo que você já percebia: casais recém formados postam sobre unicórnios vomitando arco-iris e o efeito pode durar muito, muito tempo (destaque para o gráfico feito com ggplot2).
O Facebook é, muito provavelmente, a organização com a maior base de dados sobre informações pessoais do mundo. O potencial disso é inimaginável. No final do ano passado, eles contrataram o professor da NYU Yann LeCun para liderar o departamento de inteligência articial da empresa – parece que ainda há muita coisa interessante por esperar.
Mais sobre análise de dados do Facebook neste blog, aqui (analise seus próprios dados) e aqui (descubra características da pessoa – como a orientação sexual – com base no que ela curte).

