Vocês já devem ter visto as seguintes fórmulas para a felicidade: 1) Felicidade=Realidade/Expectativa e 2) Felicidade=Realidade-Expectativa.
Essas fórmulas foram amplamente divulgadas e fazem parte do discurso do dia-a-dia. Intuitivamente, elas parecem fazer sentido, pois, quanto maior a expectativa que você tem com relação a algo, e quanto mais esta expectativa se afasta da realidade, maiores a chances de você se decepcionar e ficar infeliz. Entretanto, estas fórmulas implicam mais do que isso e, aparentemente, elas foram aceitas de forma passiva e nunca colocadas à prova ou discutidas criticamente pela sociedade. Vejamos. Chamemos Felicidade de “F”, Realidade de “R” e Expectativa de “E”. Assim, nossas fórmulas seriam:  e
e 
Para verificar se elas fazem sentido, confrontemos com nossa experiência. Imagine que você seja muito pobre. Ganhar uma casa própria aumentaria em muito sua felicidade, certo? Por outro lado, se você fosse extremamente rico, uma casa a mais não afetaria em mesma magnitude sua felicidade. Se você concorda com este fato, as equações acima não estão adequadas, pois ambas são lineares em R. Isto é, elas ferem o princípio que acabamos de descrever de que, quanto mais riqueza você tem – quanto melhor sua realidade – menos felicidade a riqueza adicional te proporciona. A função número 2 também fere o mesmo princípio para as expectativas, pois implica que um aumento de expectativas tem sempre o mesmo impacto (negativo) sobre a felicidade.
A função 1 é um tanto peculiar em outros aspectos. Em primeiro lugar, note que para ela fazer sentido temos que ter 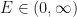 e
e 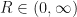 e isto nunca é explicitado nos memes do Facebook. Além de o ponto zero causar uma descontinuidade, veja que se permitirmos E negativo junto a um R positivo (ou vice-versa), isto feriria o senso-comum de que quanto pior a expectativa frente à realidade, mais feliz a pessoa é. Além disso, a derivada de 1) em relação a E é igual a
e isto nunca é explicitado nos memes do Facebook. Além de o ponto zero causar uma descontinuidade, veja que se permitirmos E negativo junto a um R positivo (ou vice-versa), isto feriria o senso-comum de que quanto pior a expectativa frente à realidade, mais feliz a pessoa é. Além disso, a derivada de 1) em relação a E é igual a  – isso significa que a desutilidade da expectativa depende da realidade. Mais especificamente, quanto melhor a realidade, pior o impacto de um aumento de expectativa. Suponha que você tinha uma expectativa de ganhar uma oferta de salário de R$1.000,00 e, por algum motivo, esta expectativa aumenta para R$2.000,00. Quanta tristeza este aumento de expectativa pode gerar? Se a realidade for uma proposta de R$500,00, nossa fórmula diz que a sua mudança de expectativa reduziu sua felicidade em 0.25. Já se a realidade for uma proposta de R$800,00, a equação diz que sua mudança de expectativa reduziu sua felicidade em maior magnitude, 0.4. Isto te parece plausível? Para mim, não.
– isso significa que a desutilidade da expectativa depende da realidade. Mais especificamente, quanto melhor a realidade, pior o impacto de um aumento de expectativa. Suponha que você tinha uma expectativa de ganhar uma oferta de salário de R$1.000,00 e, por algum motivo, esta expectativa aumenta para R$2.000,00. Quanta tristeza este aumento de expectativa pode gerar? Se a realidade for uma proposta de R$500,00, nossa fórmula diz que a sua mudança de expectativa reduziu sua felicidade em 0.25. Já se a realidade for uma proposta de R$800,00, a equação diz que sua mudança de expectativa reduziu sua felicidade em maior magnitude, 0.4. Isto te parece plausível? Para mim, não.
Deste modo, essas equações de internet são falaciosas e você deveria parar de compartilhar os memes que as contém. Mas, reconheço, essa recomendação será inócua sem uma fórmula nova que substitua as que rejeitamos. Assim, proponho uma, conforme abaixo. Deixo para o leitor o escrutínio da sugestão.
 , ,
, ,
E já vem com o mene pronto.

De antemão peço desculpas aos meus co-autores por ter perdido tempo nisso, mas as vezes a vontade de procrastinar fala mais alto.
0.000000
0.000000