Machine Learning
Tesla and self driving cars
Detectando reviews falsos na Amazon
Agora que comecei a usar mais a Amazon no dia-a-dia (usava basicamente para livros e eletrônicos) percebi a quantidade assustadora de reviews falsos que existem por lá. Isso naturalmente levou a outra pergunta: que tal usar análise de dados para filtrar os reviews falsos dos verdadeiros?
Pois bem, como quase toda a idéia que temos, alguém já a implementou. Então se você ainda não conhece, vai aqui a dica do fakespot. Usando técnicas de processamento de linguagem natural e machine learning, o site tenta identificar quais e quantos reviews são realmente autênticos. O serviço poderia ser melhor executado, mas tem funcionado bem nos casos que testei.
Visualizando um modelo de Redes Neurais

Previsões para o impeachment 2
Neale diz que as chances de passar são de 96% (dados de hoje):

No final do ano passado, as estimativas estavam em 0%.
Já Guilherme, Marcelo e Eduardo dizem que as chances são de praticamente 100% (dados de hoje):

E as simulações do Regis mostram resultado semelhante (com ausência de 0%, dados de hoje) . Com 10% de ausência, por outro lado, o resultado se inverte:
 Há outras previsões por aí?
Há outras previsões por aí?
PS: claro, há também as previsões do Vidente Carlinhos (feitas ano passado). Além do impeachment, aparentemente 2016 será um ano difícil para Ivete Sangalo. E Álvaro Dias será presidente, em 2018, pela Rede. Mas Carlinhos não tem lá um bom histórico.
Inferência causal e Big Data: Sackler Big Data Colloquium
Uma série de palestras interessantes do Sackler Big Data Colloquium:
Hal Varian: Causal Inference, Econometrics, and Big Data
***
Leo Bottou: Causal Reasoning and Learning Systems
***
David Madigan: Honest Inference From Observational Database Studies
***
Susan Athey: Estimating Heterogeneous Treatment Effects Using Machine Learning in Observational Studies
Uma introdução visual ao aprendizado de máquinas (Machine Learning)

Quando confiar nas suas previsões?
Quando você deve confiar em suas previsões? Como um amigo meu já disse, a resposta para essa questão é fácil: nunca (ou quase nunca).
Mas, brincadeiras à parte, para este post fazer sentido, vou reformular a pergunta: quando você deve desconfiar ainda mais das previsões do seu modelo?
Há várias situações em que isso ocorre, ilustremos aqui uma delas.
***
Imagine que você tenha as seguintes observações de x e y.
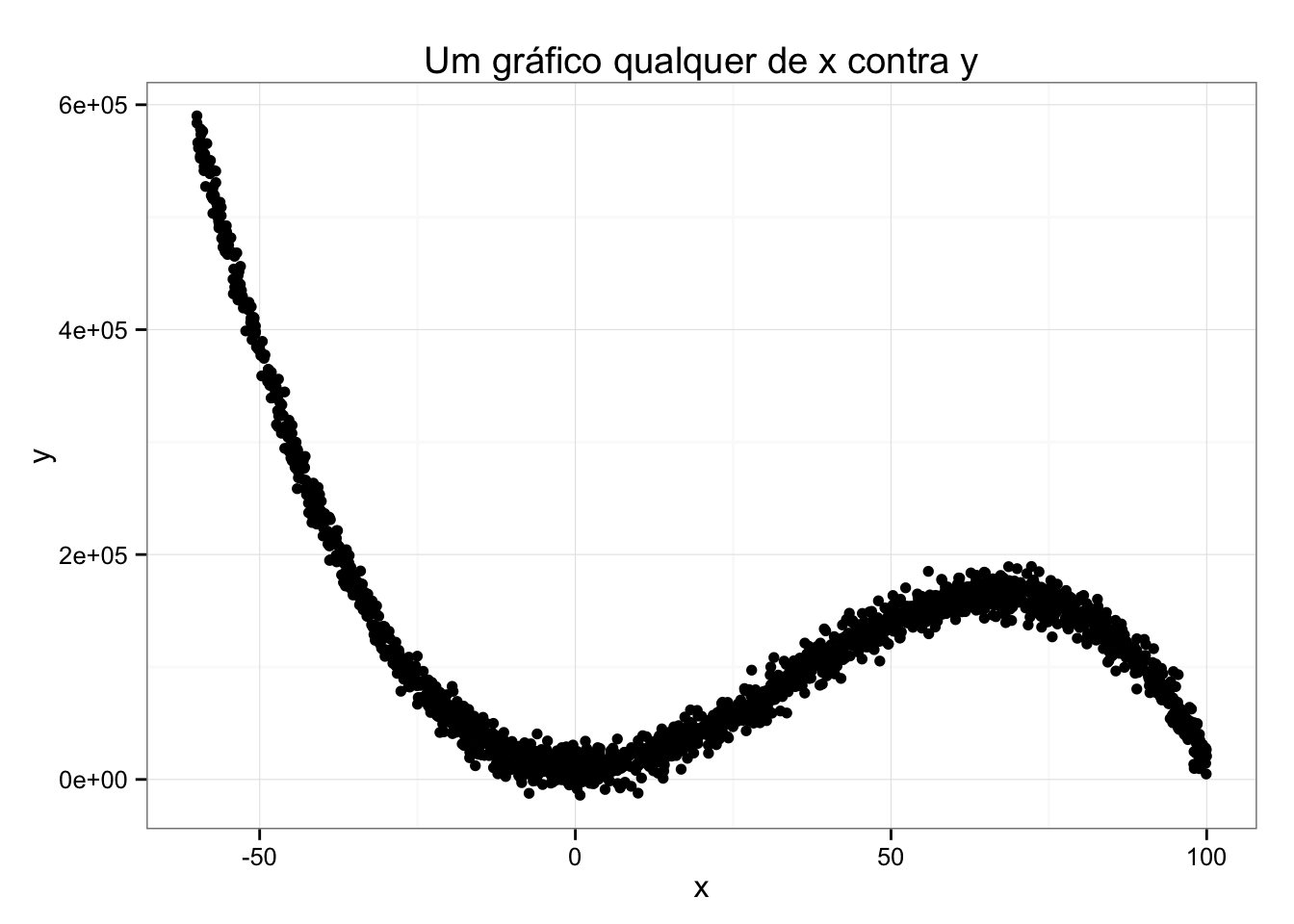
Para modelar os dados acima, vamos usar uma técnica de machine learning chamada Suport Vector Machine com um núcleo radial. Se você nunca ouviu falar disso, você pode pensar na técnica, basicamente, como uma forma genérica de aproximar funções.
Será que nosso modelo vai fazer um bom trabalho?
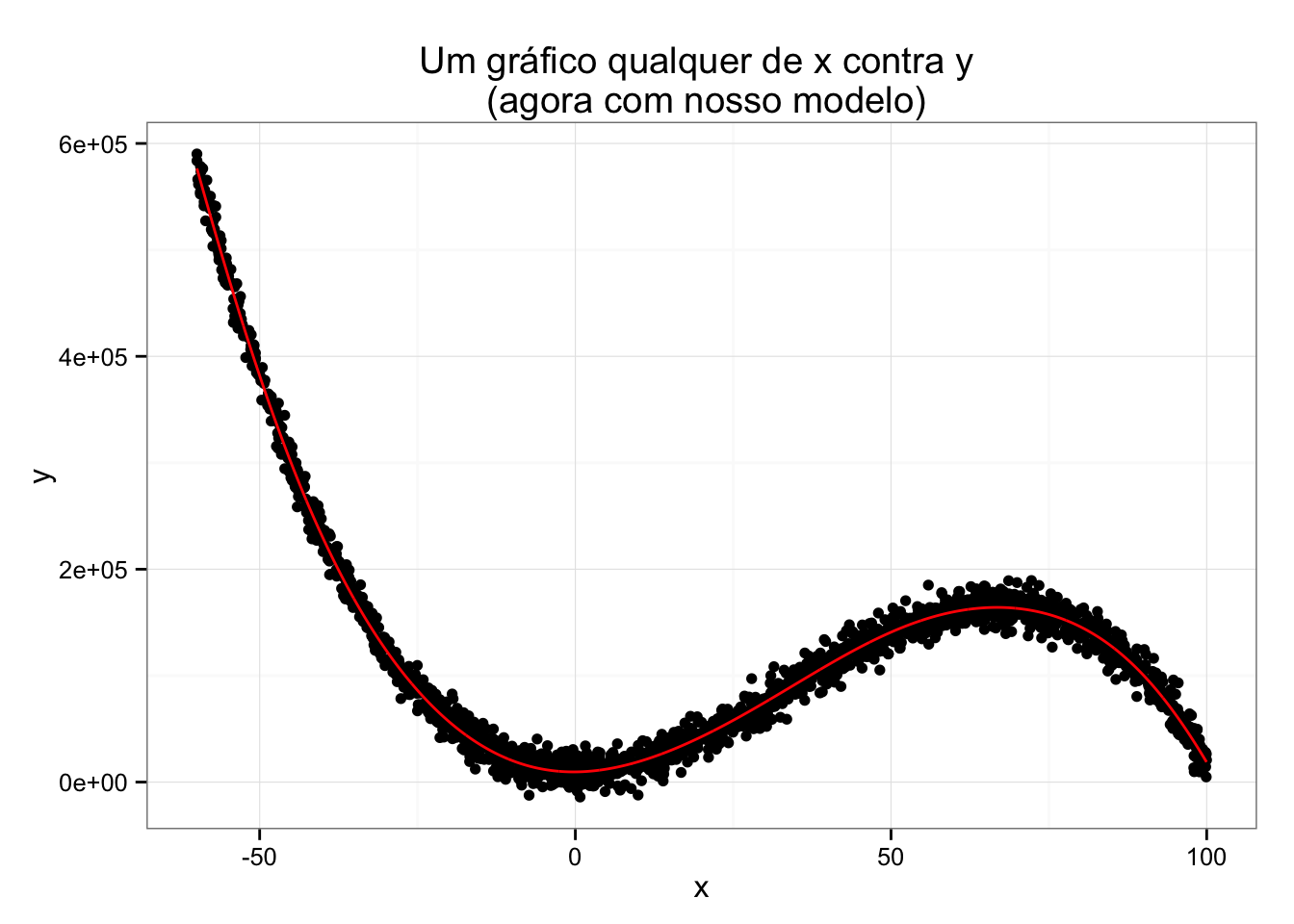
Pelo gráfico, é fácil ver que nossa aproximação ficou bem ajustada! Para ser mais exato, temos um R2 de 0.992 estimado por cross validation (que é uma estimativa do ajuste fora da amostra – e é isso o que importa, você não quer saber o quão bem você fez overfitting dos dados!).
Agora suponha que tenhamos algumas observações novas, isto é, observações nunca vistas antes. Só que essas observações novas serão de dois “tipos”, que aqui criativamente chamaremos de tipo 1 e tipo 2. Enquanto a primeira está dentro de um intervalo de x que observamos ao “treinar” nosso modelo, a segunda está em intervalos muito diferentes.
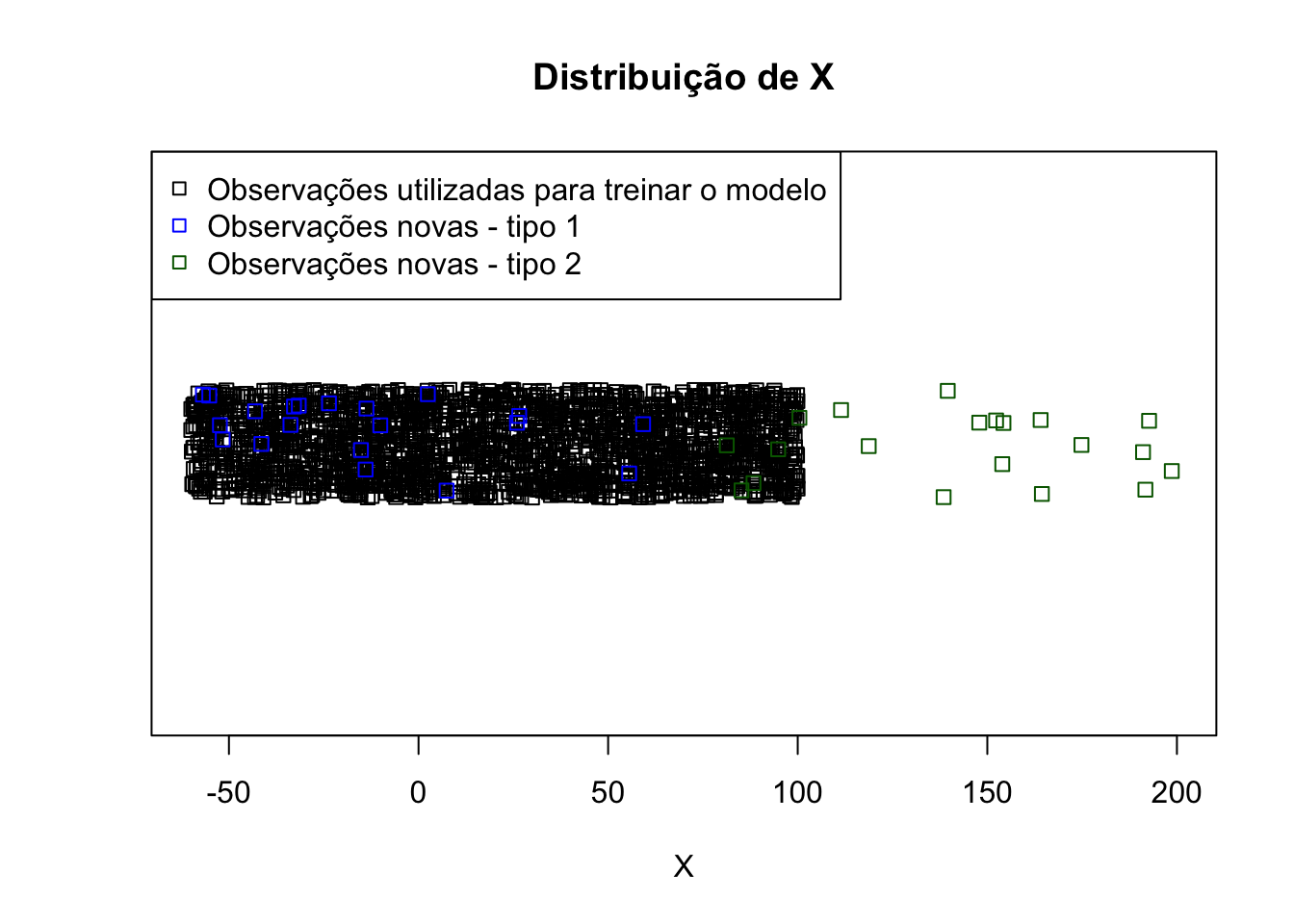
Qual tipo de observação você acha que teremos mais dificuldades de prever, a de tipo 1 ou tipo 2? Você já deve ter percebido onde queremos chegar.
Vejamos, portanto, como nosso modelo se sai agora:
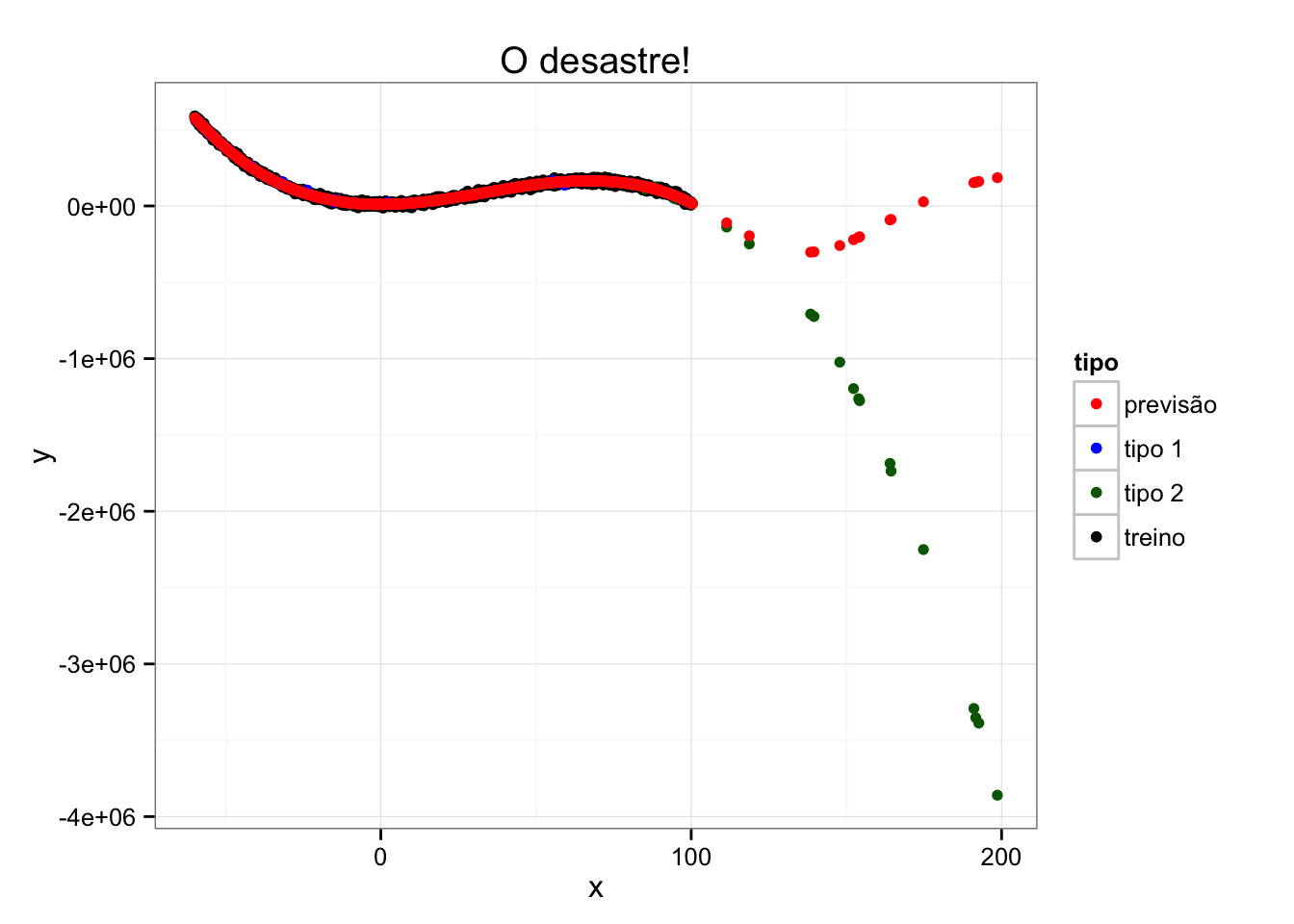
Note que nas observações “similares” (tipo 1) o modelo foi excelente, mas nas observações “diferentes” (tipo 2) nós erramos – e erramos muito. Este é um problema de extrapolação.
Neste caso, unidimensional, foi fácil perceber que uma parte dos dados que gostaríamos de prever era bastante diferente dos dados que usamos para modelar. Mas, na vida real, essa distinção pode se tornar bastante difícil. Uma complicação simples é termos mais variáveis. Imagine um caso com mais de 20 variáveis explicativas – note que já não seria trivial determinar se novas observações são similares ou não às observadas!
Quer aprofundar mais um pouco no assunto? Há uma discussão legal no livro do Max Kuhn, que já mencionamos aqui no blog.
