Paper do Pedro Souza e Marcelo Medeiros e apresentação do Marcelo Medeiros na UERJ:
Erros
Mancada da ANPEC
Parece que a ANPEC vacilou feio. Já foram divulgados os “resultados” da seleção deste ano, mas houve “um número significativo de erros na leitura dos cartões dos candidatos “. Os resultados corrigidos devem sair nesta segunda . Muitos alunos estão indignados com a situação e o Prosa Econômica começou um manifesto que já conta com mais de 100 assinaturas.
Pesquisas eleitorais: Veritá ou DataFolha? Sobre metodologia e margens de erro.
As eleições têm trazido ao público um debate importante sobre estatística e incerteza. Em um dia, o Datafolha indica 52% dos votos para a Dilma. No dia seguinte, o Instituto Veritá contabiliza 53% do votos para Aécio. Como conciliar isso com as pequenas margens de erro sugeridas pelas pesquisas?
O problema é que, em geral, as margens de erro das pesquisas são divulgadas como se tivessem sido feitas por amostragem aleatória simples. Mas, na verdade, as pesquisas têm um processo de amostragem mais complexo, sujeito a outros tipos de erros. Um texto legal sobre o assunto é este, do Rogério.
E para complicar ainda mais, os institutos usam métodos diferentes. Por exemplo, olhando as últimas duas pesquisas presidenciais, aparentemente a pesquisa do Instituto Veritá foi uma Amostragem Probabilística por Cotas com entrevistas por domicílios (e também com o uso de ponto de fluxo onde a entrevista domiciliar não fosse possível – vide aqui); e, a do DataFolha, uma Amostragem por Cotas com entrevistas por ponto de fluxo (vide aqui).
Esses métodos, apesar de terem nomes semelhantes, segundo Neale El-Dash não são tão semelhantes assim:
Outro problema é que o documento divulgado no TSE é muitas vezes pouco claro com relação a certos detalhes da metodologia. Se você se interessa pelo tema, deixo também os links para outros dois posts interessantes do Neale: este e este.
Solucionando crimes com matemática e estatística
Enquanto Breaking Bad não volta, comecei a assistir ao seriado Numb3rs, cujo enredo trata do uso da matemática e da estatística na solução de crimes. Confesso que, a princípio, estava receoso. Na maior parte das vezes, filmes e seriados que tratam desses temas costumam, ou mistificar a matemática, ou conter erros crassos.
Todavia, o primeiro episódio da série abordou uma equação para tentar identificar a provável residência de um criminoso, sendo que: (i) os diálogos dos personagens e as explicações faziam sentido; e, algo mais surpreendente, (ii) as equações de background, apesar de não explicadas, pareciam fazer sentido. Desconfiei. Será que era baseado em um caso real?
E era. Bastou pesquisar um pouco no Google para encontrar a história do policial que virou criminologista, Kim Rossmo, em que o episódio foi baseado. E inclusive, encontrar também um livro para leigos, de leitura agradável, que aborda alguns dos temas de matemática por trás do seriado: The Numbers behind Numb3rs.
A primeira equação que Rossmo criou tinha a seguinte cara:
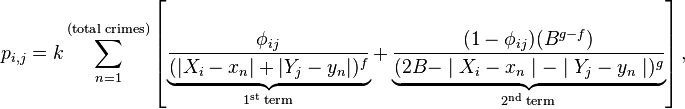
A intuição por trás da equação pode ser resumida desta forma: o criminoso não gosta de cometer crimes perto da própria residência, pois isso tornaria muito fácil sua identificação; assim, dentro de uma certa zona B, a probabilidade de o criminoso residir em um certo local é menor quanto mais próximo este estiver do crime (esse é o segundo termo da equação). Entretanto, a partir de certo ponto, começa a ser custoso ao criminoso ir mais longe para cometer o crime – assim, a partir dali, a situação se inverte, e locais longe do crime passam a ser menos prováveis (esse é o primeiro termo da equação). Em outras palavras, você tenta calcular a probabilidade de um criminoso morar na coordenada (Xi , Xj), com base na distância desta com as demais coordenadas dos crimes (xn, yn), levando em conta o fato de a residência estar ou não em B. Os parâmetros da equação são estimados de modo a otimizar o modelo com base nos dados de casos passados.
Por mais simples que seja, a equação funcionou muito bem e Kim Rossmo prosseguiu com seus estudos em criminologia. Evidentemente que, como em qualquer modelo, há casos em que a equação falha miseravelmente, como em situações em que os criminosos mudam de residência o tempo inteiro – mas isso não é um problema da equação em si, pois o trabalho de quem a utiliza é justamente identificar se a situação é, ou não, adequada para tanto. Acho que este exemplo ilustra muito bem como sacadas simples e bem aplicadas podem ser muito poderosas!
PS: O tema me interessou bastante e o livro de Rossmo, Geographic Profiling, entrou para a (crescente) wishlist da Amazon.
Déficits causam câncer
Reinhart e Rogoff perderam muito tempo com os argumentos errados. Vejam o gráfico:

Brincadeiras à parte, gostei da carta dos autores a Krugman e do post do Hamilton.
Já DeLong argumenta que, se os autores dizem que a idéia geral do artigo não se altera radicalmente por causa dos erros, por outro lado, isso não muda o fato de o argumento ter sido fraco desde o princípio (não que eu concorde com DeLong, mas o ponto é mais do que pertinente):
The third thing to note is how small the correlation is. Suppose that we consider a multiplier of 1.5 and a marginal tax share of 1/3. Suppose the growth-depressing effect lasts for 10 years. Suppose that all of the correlation is causation running from high debt to slower future growth. And suppose that we boost government spending by 2% of GDP this year in the first case. Output this year then goes up by 3% of GDP. Debt goes up by 1% of GDP taking account of higher tax collections. This higher debt then reduces growth by… wait for it… 0.006% points per year. After 10 years GDP is lower than it would otherwise have been by 0.06%. 3% higher GDP this year and slower growth that leads to GDP lower by 0.06% in a decade. And this is supposed to be an argument against expansionary fiscal policy right now?….
Gráfico retirado de Os números (não) mentem.
