***
Parte do livro Introdução à análise de dados com R. Este trabalho está em andamento, o texto é bastante preliminar e sofrerá muitas alterações.
Quer fazer sugestões? Deixe um comentário abaixo ou, se você sabe utilizar o github, acesse aqui.
Não copie ou reproduza este material sem autorização.
Volte para ver atualizações!
***
Criando textos
No R, textos são representados por vetores do tipo character. Você pode criar manualmente um elemento do tipo character colocando o texto entre aspas, podendo ser tanto aspas simples (‘texto’) quanto aspas duplas (“texto”).
# criando um vetor de textos
# aspas simples
x1 <- 'texto 1'
# aspas duplas
x2 <- "texto 2"
Como já vimos, para saber se um objeto é do tipo texto você pode utilizar a função is.character() e também é possível converter objetos de outros tipos para textos utilizando a função as.character().
# criando um vetor de inteiros
x3 <- 1:10
# É texto? Não.
is.character(x3)
## [1] FALSE
# Convertendo para texto
x3 <- as.character(x3)
# Agora é texto? Sim.
is.character(x3)
## [1] TRUE
Operações com textos
Operações como ordenação e comparações são definidas para textos. A ordenação de um texto é feita de maneira lexicográfica, tal como em um dicionário.
# ordenação de letras
sort(c("c", "d", "a", "f"))
## [1] "a" "c" "d" "f"
# ordenação de palavras
# tal como um dicionário
sort(c("cor", "casa", "árvore", "zebra", "branco", "banco"))
## [1] "árvore" "banco" "branco" "casa" "cor" "zebra"
Como a comparação é lexicográfica, é preciso tomar alguns cuidados. Por exemplo, o texto “2” é maior do que o texto “100”. Se por acaso seus números forem transformados em texto, você não vai receber uma mensagem de erro na comparação "2" > "100" mas sim um resultado errado: TRUE.
# CUIDADO!
2 > 100
## [1] FALSE
"2" > "100"
## [1] TRUE
# b > a
"b" > "a"
## [1] TRUE
# A > a
"A" > "a"
## [1] TRUE
# casa > banana
"casa" > "banana"
## [1] TRUE
Imprimindo textos
Se você estiver usando o R de modo interativo, chamar o objeto fará com que ele seja exibido na tela usando print().
# Imprime texto na tela
print(x1)
## [1] "texto 1"
# Quando em modo interativo
# Equivalente a print(x1)
x1
## [1] "texto 1"
Se você não estiver usando o R de modo interativo — como ao dar source() em um script ou dentro de um loop — é preciso chamar explicitamente uma função que exiba o texto na tela.
# sem print não acontece nada
for(i in 1:3) i
# com print o valor de i é exibido
for(i in 1:3) print(i)
## [1] 1
## [1] 2
## [1] 3
Existem outras opções para “imprimir” e formatar textos além do print(). Uma função bastante utilizada para exibir textos na tela é a função cat() (concatenate and print).
cat(x1)
## texto 1
cat("A função cat exibe o texto sem aspas:", x1)
## A função cat exibe o texto sem aspas: texto 1
Por padrão, cat() separa os textos com um espaço em branco, mas é possível alterar este comportamento com o argumento sep.
cat(x1, x2)
## texto 1 texto 2
cat(x1, x2, sep = " - ")
## texto 1 - texto 2
Outra funções úteis são sprintf() e format(), principalmente para formatar e exibir números. Para mais detalhes sobre as funções, olhar a ajuda ?sprintf e ?format.
# %.2f (float, 2 casas decimais)
sprintf("R$ %.2f", 312.12312312)
## [1] "R$ 312.12"
# duas casas decimais, separador de milhar e decimal
format(10500.5102, nsmall=2, big.mark=".", decimal.mark=",")
## [1] "10.500,51"
Caracteres especiais
Como fazemos para gerar um texto com separação entre linhas no R? Criemos a separação de linhas manualmente para ver o que acontece:
texto_nova_linha <- "texto
com nova linha"
texto_nova_linha
## [1] "texto\ncom nova linha"
Note que aparece um \n no meio do texto. Isso é um caractere especial: \n simboliza justamente uma nova linha. Quando você exibe um texto na tela com print(), caracteres especiais não são processados e aparecem de maneira literal. Já se você exibir o texto na tela usando cat(), os caracteres especiais serão processados. No nosso exemplo, o \n será exibido como uma nova linha.
# print: \n aparece literalmente
print(texto_nova_linha)
## [1] "texto\ncom nova linha"
# cat: \n aparece como nova linha
cat(texto_nova_linha)
## texto
## com nova linha
Caracteres especiais são sempre “escapados” com a barra invertida \ . Além da nova linha (\n), outros caracteres especiais recorrentes são o tab (\t) e a própria barra invertida, que precisa ela mesma ser escapada (\\). Vejamos alguns exemplos:
cat("colocando uma \nnova linha")
## colocando uma
## nova linha
cat("colocando um \ttab")
## colocando um tab
cat("colocando uma \\ barra")
## colocando uma \ barra
cat("texto com novas linhas e\numa barra no final\n\\")
## texto com novas linhas e
## uma barra no final
## \
Para colocar aspas simples ou duplas dentro do texto há duas opções. A primeira é alternar entre as aspas simples e duplas, uma para definir o objeto do tipo character e a outra servido literalmente como aspas.
# Aspas simples dentro do texto
aspas1 <- "Texto com 'aspas' simples dentro"
aspas1
## [1] "Texto com 'aspas' simples dentro"
# Aspas duplas dentro do texto
aspas2 <- 'Texto com "aspas" duplas dentro'
cat(aspas2)
## Texto com "aspas" duplas dentro
Outra opção é colocar as aspas como caracter expecial. Neste caso, não é preciso alternar entre aspas simples e duplas.
aspas3 <- "Texto com \"aspas\" duplas"
cat(aspas3)
## Texto com "aspas" duplas
aspas4 <- 'Texto com \'aspas\' simples'
cat(aspas4)
## Texto com 'aspas' simples
Utilidade das funções de exibição
Qual a utilidade de funções que exibam coisas na tela?
Um caso bastante comum é exibir mensagens durante a execução de alguma rotina ou função. Por exemplo, você pode exibir o percentual de conclusão de um loop a cada 25 rodadas:
for(i in 1:100){
# imprime quando o resto da divisão
# de i por 25 é igual a 0
if(i %% 25 == 0){
cat("Executando: ", i, "%\n", sep = "")
}
# alguma rotina
Sys.sleep(0.01)
}
## Executando: 25%
## Executando: 50%
## Executando: 75%
## Executando: 100%
Outro uso frequente é criar métodos de exibição para suas próprias classes. Vejamos um exemplo simples de uma fução base do R, a função rle(), que computa tamanhos de sequências repetidas de valores em um vetor. O resultado da função é uma lista, mas ao exibirmos o objeto na tela, o print não é igual ao de uma lista comum:
x <- rle(c(1,1,1,0))
# resultado é uma lista
str(x)
## List of 2
## $ lengths: int [1:2] 3 1
## $ values : num [1:2] 1 0
## - attr(*, "class")= chr "rle"
# print do objeto na tela
# não é como uma lista comum
x
## Run Length Encoding
## lengths: int [1:2] 3 1
## values : num [1:2] 1 0
# tirando a classe do objeto
# veja que o print agora é como uma lista comum
unclass(x)
## $lengths
## [1] 3 1
##
## $values
## [1] 1 0
Isso ocorre porque a classe rle tem um método de print próprio, print.rle():
print.rle <- function (x, digits = getOption("digits"), prefix = "", ...)
{
if (is.null(digits))
digits <- getOption("digits")
cat("", "Run Length Encoding\n", " lengths:", sep = prefix)
utils::str(x$lengths)
cat("", " values :", sep = prefix)
utils::str(x$values, digits.d = digits)
invisible(x)
}
Tamanho do texto
A função nchar() retorna o número de caracteres de um elemento do tipo texto. Note que isso é diferente da função length() que retorna o tamanho do vetor.
# O vetor x1 tem apenas um elemento
length(x1)
## [1] 1
# O elemento do vetor x1 tem 7 caracteres
# note que espaços em brancos contam
nchar(x1)
## [1] 7
A função nchar() é vetorizada.
# vetor do tipo character
y <- c("texto 1", "texto 11")
# vetor tem dois elementos
length(y)
## [1] 2
# O primeiro elemento tem 7 caracteres
# O segundo 8.
nchar(y) # vetorizada
## [1] 7 8
Manipulando textos
Manipulação de textos é uma atividade bastante comum na análise de dados. O R possui uma série de funções para isso e suporta o uso de expressões regulares. Nesta seção veremos exemplos simples das principais funções de manipulação de textos. Na próxima seção abordaremos um pouco de expressões regulares.
Colando (ou concatenando) textos
A função paste() é uma das funções mais úteis para manipulação de textos. Como o próprio nome diz, ela serve para “colar” textos.
# Colando textos
tipo <- "Apartamento"
bairro <- "Asa Sul"
texto <- paste(tipo,"na", bairro )
texto
## [1] "Apartamento na Asa Sul"
Por default, paste() separa os textos com um espaço em branco. Você pode alterar isso modificando o argumento sep. Caso não queira nenhum espaço entre as strings, basta definir sep = "" ou utilizar a função paste0(). Como usual, todas essas funções são vetorizadas.
# separação padrão
paste("x", 1:5)
## [1] "x 1" "x 2" "x 3" "x 4" "x 5"
# separando por ponto
paste("x", 1:5, sep=".")
## [1] "x.1" "x.2" "x.3" "x.4" "x.5"
# sem separação
paste("x", 1:5, sep ="")
## [1] "x1" "x2" "x3" "x4" "x5"
# sem separação, usando paste0.
paste0("x", 1:5)
## [1] "x1" "x2" "x3" "x4" "x5"
Note que foram gerados 5 elementos diferentes nos exemplos acima. É possível “colar” todos os elementos em um único texto com a opção collapse().
paste("x", 1:5, sep="", collapse=" ")
## [1] "x1 x2 x3 x4 x5"
Separando textos
Outra atividade frequente em análise de dados é separar um texto em elementos diferentes. Por exemplo, suponha que você tenha que trabalhar com um conjunto de números, mas que eles estejam em um formato de texto separados por ponto e vírgula:
dados <- "1;2;3;4;5;6;7;8;9;10"
dados
## [1] "1;2;3;4;5;6;7;8;9;10"
Com a função strsplit() é fácil realizar essa tarefa:
dados_separados <- strsplit(dados, split=";")
dados_separados
## [[1]]
## [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10"
Note que o resultado da função é uma lista. Agora é possível converter os dados em números e trabalhar normalmente.
# convertendo o resultado em número
dados_separados <- as.numeric(dados_separados[[1]])
# agora é possível trabalhar com os números
# média
mean(dados_separados)
## [1] 5.5
# soma
sum(dados_separados)
## [1] 55
Encontrando partes de um texto
Quando você estiver trabalhando com suas bases de dados, muitas vezes será preciso encontrar certas palavras ou padrões dentro do texto. Por exemplo, imagine que você tenha uma base de dados de aluguéis de apartamentos e você gostaria de encontrar imóveis em um certo endereço. Vejamos este exemplo com dados online de aluguel em Brasília.
# Carrega arquivo de anúncios de aluguel (2014)
arquivo <- url("https://dl.dropboxusercontent.com/u/44201187/aluguel.rds")
con <- gzcon(arquivo)
aluguel <- readRDS(con)
close(con)
Vejamos a estrutura da nossa base de dados:
str(aluguel)
## 'data.frame': 2612 obs. of 5 variables:
## $ bairro : chr "Asa Norte" "Asa Norte" "Sudoeste" "Asa Norte" ...
## $ endereco: chr "CLN 310 BLOCO A " "SCRN 716 BLOCO G ENT. 26 3º ANDAR" "QMSW 06 ED.STUDIO IN" "CLN 406 BLOCO D - ED. POP CENTER (APARTAMENTO)" ...
## $ quartos : num 1 1 1 1 1 1 1 1 1 1 ...
## $ m2 : num 22.9 26 30 30 30 30 30 30 28 30 ...
## $ preco : num 650 750 800 800 800 820 850 850 850 860 ...
## - attr(*, "na.action")=Class 'omit' Named int [1:120] 15943 16001 17264 17323 18600 18659 19935 19996 21278 22617 ...
## .. ..- attr(*, "names")= chr [1:120] "15943" "16001" "17264" "17323" ...
Temos mais de 2 mil anúnciso, como encontrar aqueles apartamentos que queremos, como, por exemplos, os que contenham “CLN 310” no endereço? Neste caso você pode utilizar a função grep() para encontrar padrões dentro do texto. A função retornará o índice das observações que contém o texto:
busca_indice <- grep(pattern = "CLN 310", aluguel$endereco)
busca_indice
## [1] 1 1812
aluguel[busca_indice, ]
## bairro endereco quartos m2 preco
## 1 Asa Norte CLN 310 BLOCO A 1 22.9 650
## 1812 Asa Norte CLN 310 BLOCO E ENTRADA 52 SALA 216 0 30.0 900
Uma variante da função grep() é a função grepl(), que realiza a mesma coisa, mas ao invés de retornar um índice numérico, retorna um vetor lógico:
busca_logico <- grepl(pattern = "CLN 310", aluguel$endereco)
str(busca_logico)
## logi [1:2612] TRUE FALSE FALSE FALSE FALSE FALSE ...
aluguel[busca_indice, ]
## bairro endereco quartos m2 preco
## 1 Asa Norte CLN 310 BLOCO A 1 22.9 650
## 1812 Asa Norte CLN 310 BLOCO E ENTRADA 52 SALA 216 0 30.0 900
Nossa busca é útil, mas ainda é simples. Quando aprendermos expressões regulares, essas buscas ficarão bem mais poderosas. Lá também aprenderemos outras funções como regexpr(), gregexpr(), regexec() e regmatches().
Substituindo partes de um texto
A função sub() substitui o primeiro padrão (pattern) que encontra:
texto2 <- paste(texto, ", Apartamento na Asa Norte")
texto2
## [1] "Apartamento na Asa Sul , Apartamento na Asa Norte"
# Vamos substituir "apartamento" por "Casa"
# Mas apenas o primeiro caso
sub(pattern = "Apartamento",
replacement = "Casa",
texto2)
## [1] "Casa na Asa Sul , Apartamento na Asa Norte"
Já a função gsub() substitui todos os padrões que encontra:
# Vamos substituir "apartamento" por "Casa"
# Agora em todos os casos
gsub(pattern="Apartamento",
replacement="Casa",
texto2)
## [1] "Casa na Asa Sul , Casa na Asa Norte"
Você pode usar as funções sub() e gsub() para “deletar” partes indesejadas do texto, basta colocar como replacement um caractere vazio "". Um exemplo bem corriqueiro, quando se trabalha com com nomes de arquivos, é a remoção das extensões:
# nomes dos arquivos
arquivos <- c("simulacao_1.csv","simulacao_2.csv")
# queremos eliminar a extensão .csv
# note que o ponto precisa ser escapado
nomes_sem_csv <- gsub("\\.csv", "", arquivos)
nomes_sem_csv
## [1] "simulacao_1" "simulacao_2"
Extraindo partes específicas de um texto
Às vezes você precisa extrair apenas algumas partes específicas de um texto, em determinadas posições. Para isso você pode usar as funções substr() e substring().
Para essas funções, você basicamente passa as posições dos caracteres inicial e final que deseja extrair.
# extraindo caracteres da posição 4 à posição 8
x <- "Um texto de exemplo"
substr(x, start = 4, stop = 8)
## [1] "texto"
É possível utilizar essas funções para alterar partes específicas do texto.
# substituindo caracteres da posição 4 à posição 8
substr(x, start = 4, stop = 8) <- "TEXTO"
x
## [1] "Um TEXTO de exemplo"
A principal diferença entre substr() e substring() é que a segunda permite você passar vários valores iniciais e finais:
# pega caracteres de (4 a 8) e de (10 a 11)
substring(x, first = c(4, 10), last = c(8, 11))
## [1] "TEXTO" "de"
# pega caracteres de (1 ao último), (2 ao último) ...
substring("abcdef", first = 1:6)
## [1] "abcdef" "bcdef" "cdef" "def" "ef" "f"
**** A SEGUIR ****
- expressões regulares
- regmatches, regexpr, gregexpr, regexc
- fuzzy matching
- stringr





 , com média
, com média  e desvio padrão
e desvio padrão  .
. . Assim, temos que
. Assim, temos que  e, segundo o teorema central do limite, a variável
e, segundo o teorema central do limite, a variável 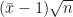 tende a uma normal-padrão (
tende a uma normal-padrão (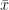 é a média amostral de
é a média amostral de  )
)
 ? Façamos uma simulação para seis valores de tamanho amostral diferentes: 1, 5, 10, 100, 500 e 1000.
? Façamos uma simulação para seis valores de tamanho amostral diferentes: 1, 5, 10, 100, 500 e 1000.