Programação
Data Frames
***
Parte do livro Introdução à análise de dados com R. Este trabalho está em andamento, o texto é bastante preliminar e sofrerá muitas alterações.
Quer fazer sugestões? Deixe um comentário abaixo ou, se você sabe utilizar o github, acesse aqui.
Não copie ou reproduza este material sem autorização.
Volte para ver atualizações!
***
Data Frames: seu banco de dados no R
Por que um data.frame?
Até agora temos utilizado apenas dados de uma mesma classe, armazenados ou em um vetor ou em uma matriz. Mas uma base de dados, em geral, é feita de dados de diversas classes diferentes: no exemplo anterior, por exemplo, podemos querer ter uma coluna com os nomes dos funcionários, outra com o sexo dos funcionários, outra com valores… note que essas colunas são de classes diferentes, como textos e números. Como guardar essas informações?
A solução para isso é o data.frame. O data.frame é talvez o formato de dados mais importante do R. No data.frame cada coluna representa uma variável e cada linha uma observação. Essa é a estrutura ideal para quando você tem várias variáveis de classes diferentes em um banco de dados.
Criando um data.frame: data.frame() e as.data.frame()
É possível criar um data.frame diretamente com a função data.frame():
funcionarios <- data.frame(nome = c("João", "Maria", "José"),
sexo = c("M", "F", "M"),
salario = c(1000, 1200, 1300),
stringsAsFactors = FALSE)
funcionarios
## nome sexo salario
## 1 João M 1000
## 2 Maria F 1200
## 3 José M 1300
Também é coverter outros objetos em um data.frame com a função as.data.frame().
Discutiremos a opção stringsAsFactors = FALSE mais a frente.
Vejamos a estrutura do data.frame. Note que cada coluna tem sua própria classe.
str(funcionarios) ## 'data.frame': 3 obs. of 3 variables: ## $ nome : chr "João" "Maria" "José" ## $ sexo : chr "M" "F" "M" ## $ salario: num 1000 1200 1300
Nomes de linhas e colunas
O data.frame sempre terá rownames e colnames.
rownames(funcionarios) ## [1] "1" "2" "3" colnames(funcionarios) ## [1] "nome" "sexo" "salario"
Detalhe: a função names() no data.fram trata de suas colunas, pois os elementos fundamentais do data.frame são seus vetores coluna.
names(funcionarios) ## [1] "nome" "sexo" "salario"
Não parece tão diferente de uma matriz…
O que ocorreria com o data.frame funcionarios se o transformássemos em uma matriz? Vejamos:
as.matrix(funcionarios) ## nome sexo salario ## [1,] "João" "M" "1000" ## [2,] "Maria" "F" "1200" ## [3,] "José" "M" "1300"
Perceba que todas as variáveis viraram character! Uma matriz aceita apenas elementos da mesma classe, e é exatamente por isso precisamos de um data.frame neste caso.
Manipulando data.frames como matrizes
Ok, temos mais um objeto do R, o data.frame … vou ter que reaprender tudo novamente? Não! Você pode manipular data.frames como se fossem matrizes!
Praticamente tudo o que vimos para selecionar e modificar elementos em matrizes funciona no data.frame. Podemos selecionar linhas e colunas do nosso data.frame como se fosse uma matriz:
## tudo menos linha 1
funcionarios[-1, ]
## nome sexo salario
## 2 Maria F 1200
## 3 José M 1300
## seleciona primeira linha e primeira coluna (vetor)
funcionarios[1, 1]
## [1] "João"
## seleciona primeira linha e primeira coluna (data.frame)
funcionarios[1, 1, drop = FALSE]
## nome
## 1 João
## seleciona linha 3, colunas "nome" e "salario"
funcionarios[3 , c("nome", "salario")]
## nome salario
## 3 José 1300
E também alterar seus valores tal como uma matriz.
## aumento de salario para o João funcionarios[1, "salario"] <- 1100 funcionarios ## nome sexo salario ## 1 João M 1100 ## 2 Maria F 1200 ## 3 José M 1300
Extra do data.frame: selecionando e modificando com $ e [[ ]]
Outras formas alternativas de selecionar colunas em um data.frame são o $ e o [[ ]]:
## Seleciona coluna nome funcionarios$nome ## [1] "João" "Maria" "José" funcionarios[["nome"]] ## [1] "João" "Maria" "José" ## Seleciona coluna salario funcionarios$salario ## [1] 1100 1200 1300 funcionarios[["salario"]] ## [1] 1100 1200 1300
Tanto o $ quanto o [[ ]] sempre retornam um vetor como resultado.
Também é possível alterar a coluna combinando $ ou [[ ]] com <-:
## outro aumento para o João funcionarios$salario[1] <- 1150 ## equivalente funcionarios[["salario"]][1] <- 1150 funcionarios ## nome sexo salario ## 1 João M 1150 ## 2 Maria F 1200 ## 3 José M 1300
Extra do data.frame: retornando sempre um data.frame com [ ]
Se você quiser garantir que o resultado da seleção será sempre um data.frame use drop = FALSE ou selecione sem a vírgula:
## Retorna data.frame funcionarios[ ,"salario", drop = FALSE] ## salario ## 1 1150 ## 2 1200 ## 3 1300 ## Retorna data.frame funcionarios["salario"] ## salario ## 1 1150 ## 2 1200 ## 3 1300
Tabela resumo: selecionando uma coluna em um data.frame
Resumindo as formas de seleção de uma coluna de um data.frame.

Criando colunas novas
Há diversas formas de criar uma coluna nova em um data.frame. O principal segredo é o seguinte: faça de conta que a coluna já exista, selecione ela com $, [,] ou [[]] e atribua o valor que deseja.
Para ilustrar, vamos adicionar ao nosso data.frame funcionarios mais três colunas.
Com $:
funcionarios$escolaridade <- c("Ensino Médio", "Graduação", "Mestrado")
Com [ , ]:
funcionarios[, "experiencia"] <- c(10, 12, 15)
Com [[ ]]:
funcionarios[["avaliacao_anual"]] <- c(7, 9, 10)
Uma última forma de adicionar coluna a um data.frame é, tal como uma matriz, utilizar a função cbind() (column bind).
funcionarios <- cbind(funcionarios,
prim_emprego = c("sim", "nao", "nao"),
stringsAsFactors = FALSE)
Vejamos como ficou nosso data.frame com as novas colunas:
funcionarios ## nome sexo salario escolaridade experiencia avaliacao_anual prim_emprego ## 1 João M 1150 Ensino Médio 10 7 sim ## 2 Maria F 1200 Graduação 12 9 nao ## 3 José M 1300 Mestrado 15 10 nao
E agora, temos colunas demais, como remover algumas delas?
Removendo colunas
A forma mais fácil de remover coluna de um data.fram é atribuir o valor NULL a ela:
## deleta coluna prim_emprego funcionarios$prim_emprego <- NULL
Mas a forma mais segura e universal de remover qualquer elemento de um objeto do R é selecionar tudo exceto aquilo que você não deseja. Isto é, selecione todas colunas menos as que você não quer e atribua o resultado de volta ao seu data.frame:
## deleta colunas 4 e 6 funcionarios <- funcionarios[, c(-4, -6)]
Adicionando linhas
Uma forma simples de adicionar linhas é atribuir a nova linha com <-. Mas cuidado! O que irá acontecer com o data.frame com o código abaixo?
## CUIDADO!
funcionarios[4, ] <- c("Ana", "F", 2000, 15)
Note que nosso data.frame inteiro se transformou em texto! Você sabe explicar por que isso aconteceu? relembrar coerção
str(funcionarios) ## 'data.frame': 4 obs. of 4 variables: ## $ nome : chr "João" "Maria" "José" "Ana" ## $ sexo : chr "M" "F" "M" "F" ## $ salario : chr "1150" "1200" "1300" "2000" ## $ experiencia: chr "10" "12" "15" "15"
Antes de prosseguir, transformemos as colunas salario e experiencia em números novamente:
funcionarios$salario <- as.numeric(funcionarios$salario) funcionarios$experiencia <- as.numeric(funcionarios$experiencia)
Se os elementos forem de classe diferente, use a função data.frame para evitar coerção:
funcionarios[4, ] <- data.frame(nome = "Ana", sexo = "F",
salario = 2000, experiencia = 15,
stringsAsFactors = FALSE)
Também é possível adicionar linhas com rbind():
rbind(funcionarios,
data.frame(nome = "Ana", sexo = "F",
salario = 2000, experiencia = 15,
stringsAsFactors = FALSE))
Atenção! Não fique aumentando um data.frame de tamanho adicionando linhas ou colunas. Sempre que possível pré-aloque espaço!
Removendo linhas
Para remover linhas, basta selecionar apenas aquelas linhas que você deseja manter:
## remove linha 4 do data.frame funcionarios <- funcionarios[-4, ]
## remove linhas em que salario <= 1150 funcionarios <- funcionarios[funcionarios$salario > 1150, ]
Filtrando linhas com vetores logicos
Relembrando: se passarmos um vetor lógico na dimensão das linhas, selecionamos apenas aquelas que são TRUE. Assim, por exemplo, se quisermos selecionar aquelas linhas em que a coluna salario é maior do que um determinado valor, basta colocar esta condição como filtro das linhas:
## Apenas linhas com salario > 1000 funcionarios[funcionarios$salario > 1000, ] ## nome sexo salario experiencia ## 2 Maria F 1200 12 ## 3 José M 1300 15 ## Apenas linhas com sexo == "F" funcionarios[funcionarios$sexo == "F", ] ## nome sexo salario experiencia ## 2 Maria F 1200 12
Funções de conveniência: subset()
Uma função de conveniência para selecionar linhas e colunas de um data.frame é a função subset(), que tem a seguinte estrutura:
subset(nome_do_data_frame,
subset = expressao_logica_para_filtrar_linhas,
select = nomes_das_colunas,
drop = simplicar_para_vetor?)
Vejamos alguns exemplos:
## funcionarios[funcionarios$sexo == "F",]
subset(funcionarios, sexo == "F")
## nome sexo salario experiencia
## 2 Maria F 1200 12
## funcionarios[funcionarios$sexo == "M", c("nome", "salario")]
subset(funcionarios, sexo == "M", select = c("nome", "salario"))
## nome salario
## 3 José 1300
Funções de conveniência: with
A função with() permite que façamos operações com as colunas do data.frame sem ter que ficar repetindo o nome do data.frame seguido de $ , [ , ] ou [[]] o tempo inteiro.
Para ilustrar:
## Com o with with(funcionarios, (salario^3 - salario^2)/log(salario)) ## [1] 2.4e+08 3.1e+08 ## Sem o with (funcionarios$salario^3 - funcionarios$salario^2)/log(funcionarios$salario) ## [1] 2.4e+08 3.1e+08
Quatro formas de fazer a mesma coisa (pense em outras formas possíveis):
subset(funcionarios, sexo == "M", select = "salario", drop = TRUE) ## [1] 1300 with(funcionarios, salario[sexo == "M"]) ## [1] 1300 funcionarios$salario[funcionarios$sexo == "M"] ## [1] 1300 funcionarios[funcionarios$sexo == "M", "salario"] ## [1] 1300
Aplicando funções no data.frame: sapply e lapply, funções nas colunas (elementos)
Outras duas funções bastante utilizadas no R são as funções sapply() e lapply().
- As funções
sapplyelapplyaplicam uma função em cada elemento de um objeto. - Como vimos, os elementos de um
data.framesão suas colunas. Deste modo, as funçõessapplyelapplyaplicam uma função nas colunas de um data.frame. - A diferença entre uma e outra é que a primeira tenta simplificar o resultado enquanto que a segunda sempre retorna uma lista.
Testando no nosso data.frame:
sapply(funcionarios[3:4], mean) ## salario experiencia ## 1250 14 lapply(funcionarios[3:4], mean) ## $salario ## [1] 1250 ## ## $experiencia ## [1] 14
Filtrando variáveis antes de aplicar funções: filter()
Como data.frames podem ter variáveis de classe diferentes, muitas vezes é conveniente filtrar apenas aquelas colunas de determinada classe (ou que satisfaçam determinada condição). A função Filter() é uma maneira rápida de fazer isso:
# seleciona apenas colunas numéricas Filter(is.numeric, funcionarios) ## salario experiencia ## 2 1200 12 ## 3 1300 15 # seleciona apenas colunas de texto Filter(is.character, funcionarios) ## nome sexo ## 2 Maria F ## 3 José M
Juntando filter() com sapply() você pode aplicar funções em apenas certas colunas, como por exemplo, calcular a média e máximo apenas nas colunas numéricas do nosso data.frame:
sapply(Filter(is.numeric, funcionarios), mean) ## salario experiencia ## 1250 14 sapply(Filter(is.numeric, funcionarios), max) ## salario experiencia ## 1300 15
Manipulando data.frames
Ainda temos muita coisa para falar de manipulação de data.framese isso merece um espaço especial. Veremos além de outras funções base do R alguns pacotes importantes como dplyr, reshape2 e tidyr em uma seção separada.
Vídeos das apresentações do useR! disponíveis!
Todos os vídeos já estão disponíveis aqui. Tem muita coisa boa, vale a pena conferir.
Programação no R: if(), if() else e ifelse()
***
Parte do livro Introdução à análise de dados com R. Este trabalho está em andamento, o texto é bastante preliminar e sofrerá muitas alterações.
Quer fazer um curso presencialmente!? Estamos com turmas abertas em Brasília e São Paulo!
Quer fazer sugestões? Deixe um comentário abaixo ou, se você sabe utilizar o github, acesse aqui.
Não copie ou reproduza este material sem autorização.
Volte para ver atualizações!
***
Há ocasiões em queremos ou precisamos executar parte do código apenas se alguma condição for atendida. O R fornece três opções básicas para estruturar seu código dessa maneira: if(), if() else e ifelse(). Vejamos cada uma delas.
O if() sozinho
A estrutura básica do if() é a seguinte:
if (condicao) {
# comandos que
# serao rodados
# caso condicao = TRUE
}
- O início do código se dá com o comando
ifseguido de parênteses e chaves; - Dentro do parênteses temos uma condição lógica, que deverá ter como resultado ou
TRUEouFALSE; - Dentro das chaves temos o bloco de código que será executado se – e somente se – a condição do parênteses for
TRUE.
Vejamos um exemplo muito simples. Temos dois blocos de código que criam as variáveis x e y, mas eles só serão executados se as variáveis cria_x e cria_y forem TRUE, respectivamente.
# vetores de condição lógica
cria_x <- TRUE
cria_y <- FALSE
# só executa se cria_x = TRUE
if (cria_x) {
x <- 1
}
# só executa se cria_y = TRUE
if (cria_y) {
y <- 1
}
# note que x foi criado
exists("x")
## [1] TRUE
# note que y não foi criado
exists("y")
## [1] FALSE
Note que somente a variável x foi criada. Vamos agora rodar o mesmo bloco mas com TRUE e FALSE diferentes.
# remove x que foi criado
rm(x)
# vetores de condição lógica
cria_x <- FALSE
cria_y <- TRUE
# só executa se cria_x = TRUE
if (cria_x) {
x <- 1
}
# só executa se cria_y = TRUE
if (cria_y) {
y <- 1
}
# note que x não foi criado
exists("x")
## [1] FALSE
# note que y foi criado
exists("y")
## [1] TRUE
Note que agora apenas o y foi criado.
O if() com o else
Outra forma de executar códigos de maneira condicional é acrescentar ao if() o opcional else.
A estrutura básica do if() else é a seguinte:
if (condicao) {
# comandos que
# serao rodados
# caso condicao = TRUE
} else {
# comandos que
# serao rodados
# caso condicao = FALSE
}
- O início do código se dá com o comando
ifseguido de parênteses e chaves; - Dentro do parênteses temos uma condição lógica, que deverá ter como resultado ou
TRUEouFALSE; - Dentro das chaves do
if()temos um bloco de código que será executado se – e somente se – a condição do parênteses forTRUE. - Logo em seguida temos o
elseseguido de chaves; - Dentro das chaves do
elsetemos um bloco de código que será executado se – e somente se – a condição do parênteses forFALSE.
Como no caso anterior, vejamos primeiramente um exemplo bastante simples.
numero <- 1
if (numero == 1) {
cat("o numero é igual a 1")
} else {
cat("o numero não é igual a 1")
}
## o numero é igual a 1
É possível encadear diversos if() else em sequência:
numero <- 10
if (numero == 1) {
cat("o numero é igual a 1")
} else if (numero == 2) {
cat("o numero é igual a 2")
} else {
cat("o numero não é igual nem a 1 nem a 2")
}
## o numero não é igual nem a 1 nem a 2
Para fins de ilustração, vamos criar uma função que nos diga se um número é par ou ímpar. Nela vamos utilizar tanto o if() sozinho quanto o if() else.
Vale relembrar que um número (inteiro) é par se for divisível por 2 e que podemos verificar isso se o resto da divisão (operador %% no R) deste número por 2 for igual a zero.
par_ou_impar <- function(x){
# verifica se o número é um decimal comparando o tamanho da diferença de x e round(x)
# se for decimal retorna NA (pois par e ímpar não fazem sentido para decimais)
if (abs(x - round(x)) > 1e-7) {
return(NA)
}
# se o número for divisível por 2 (resto da divisão zero) retorna "par"
# caso contrário, retorna "ímpar"
if (x %% 2 == 0) {
return("par")
} else {
return("impar")
}
}
Vamos testar nossa função:
par_ou_impar(4) ## [1] "par" par_ou_impar(5) ## [1] "impar" par_ou_impar(2.1) ## [1] NA
Parece que está funcionando bem… só tem um pequeno problema. Se quisermos aplicar nossa função a um vetor de números, olhe o que ocorrerá:
x <- 1:5
par_ou_impar(x)
## Warning in if (abs(x - round(x)) > 1e-07) {: a condição tem comprimento > 1 e somente o primeiro
## elemento será usado
## Warning in if (x%%2 == 0) {: a condição tem comprimento > 1 e somente o primeiro elemento será usado
## [1] "impar"
Provavelmente não era isso o que esperávamos. O que está ocorrendo aqui?
A função ifelse()
Os comandos if() e if() else não são vetorizados. Uma alternativa para casos como esses é utilizar a função ifelse().
A função ifelse() tem a seguinte estrutura básica:
ifelse(vetor_de_condicoes, valor_se_TRUE, valor_se_FALSE)
- o primeiro argumento é um vetor (ou uma expressão que retorna um vetor) com vários
TRUEeFALSE; - o segundo argumento é o valor que será retornado quando o elemento do
vetor_de_condicoesforTRUE; - o terceiro argumento é o valor que será retornado quando o elemento do
vetor_de_condicoesforFALSE.
Primeiramente, vejamos um caso trivial, para entender melhor como funciona o ifelse():
ifelse(c(TRUE, FALSE, FALSE, TRUE), 1, -1) ## [1] 1 -1 -1 1
Note que passamos um vetor de condições com TRUE, FALSE, FALSE e TRUE. O valor para o caso TRUE é 1 e o valor para o caso FALSE é -1. Logo, o resultado é 1, -1, -1 e 1.
Façamos agora um exemplo um pouco mais elaborado. Vamos criar uma versão com ifelse da nossa função que nos diz se um número é par ou ímpar.
par_ou_impar_ifelse <- function(x){
# se x for decimal, retorna NA, se não for, retorna ele mesmo (x)
x <- ifelse(abs(x - round(x)) > 1e-7, NA, x)
# se x for divisivel por 2, retorna 'par', se não for, retorna impar
ifelse(x %% 2 == 0, "par", "impar")
}
Testemos a função com vetores. Perceba que agora funciona sem problemas!
par_ou_impar_ifelse(x) ## [1] "impar" "par" "impar" "par" "impar" par_ou_impar_ifelse(c(x, 1.1)) ## [1] "impar" "par" "impar" "par" "impar" NA
Vetorização e ifelse()
Um tema constante neste livro é fazer com que você comece a pensar em explorar a vetorização do R. Este caso não é diferente, note que poderíamos ter feito a função utilizando apenas comparações vetorizadas:
par_ou_impar_vec <- function(x){
# transforma decimais em NA
decimais <- abs(x - round(x)) > 1e-7
x[decimais] <- NA
# Cria vetor para aramazenar resultados
res <- character(length(x))
# verificar quem é divisível por dois
ind <- (x %% 2) == 0
# quem for é par
res[ind] <- "par"
# quem não for é ímpar
res[!ind] <- "impar"
# retorna resultado
return(res)
}
Na prática, o que a função ifelse() faz é mais ou menos isso o que fizemos acima – comparações e substituições de forma vetorizada. Note que, neste caso, nossa implementação ficou inclusive um pouco mais rápida do que a solução anterior com ifelse():
library(microbenchmark) microbenchmark(par_ou_impar_vec(1:1e3), par_ou_impar_ifelse(1:1e3)) ## Unit: microseconds ## expr min lq mean median uq max neval cld ## par_ou_impar_vec(1:1000) 56 58 85 59 83 1428 100 a ## par_ou_impar_ifelse(1:1000) 322 324 411 326 414 2422 100 b
Loops no R: usando o for()
***
Parte do livro Introdução à análise de dados com R. Este trabalho está em andamento, o texto é bastante preliminar e sofrerá muitas alterações.
Quer fazer um curso presencialmente!? Estamos com turmas abertas em Brasília e São Paulo!
Quer fazer sugestões? Deixe um comentário abaixo ou, se você sabe utilizar o github, acesse aqui.
Não copie ou reproduza este material sem autorização.
Volte para ver atualizações!
***
Loops: for()
Um loop utilizando for() no R tem a seguinte estrutura básica:
for(i in conjunto_de_valores){
# comandos que
# serão repetidos
}
- O início do loop se dá com o comando
forseguido de parênteses e chaves; - Dentro do parênteses temos um indicador que será usado durante o loop (no caso escolhemos o nome
i) e um conjunto de valores que será iterado (conjunto_de_valores). - Dentro das chaves temos o bloco de código que será executado durante o loop.
Em outras palavras, no comando acima estamos dizendo que para cada elemento i contido no conjunto_de_valores iremos executar os comandos que estão dentro das chaves.
Para facilitar o entendimento, vejamos dois exemplos muito simples. Primeiro, vamos imprimir na tela os números de 1 a 5.
for(i in 1:5){
print(i)
}
## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
Agora, vamos imprimir na tela as 5 primeiras letras do alfabeto (o R já vem com um vetor com as letras do alfabeto: letters).
for(i in 1:5){
print(letters[i])
}
## [1] "a"
## [1] "b"
## [1] "c"
## [1] "d"
## [1] "e"
No mesmo exemplo, acima, ao invés correr o loop no índice de inteiros 1:5, vamos iterar diretamente sobre os primeiros 5 elementos do vetor letters:
for(letra in letters[1:5]){
print(letra)
}
## [1] "a"
## [1] "b"
## [1] "c"
## [1] "d"
## [1] "e"
seq_along
Uma função bastante útil ao fazer loops é a função seg_along(). Ela cria um vetor de inteiros com índices para acompanhar o objeto.
# criando um vetor de exemplo set.seed(119) x <- rnorm(10) # inteiros de 1 a 10 seq_along(x) ## [1] 1 2 3 4 5 6 7 8 9 10
Também é possível criar um vetor de inteiros do tamanho do objeto fazendo uma sequência de 1 até length(x):
1:length(x) ## [1] 1 2 3 4 5 6 7 8 9 10
Entretanto, a vantagem de seq_along() é que quando o vetor é vazio, ela retorna um vetor vazio e, deste modo, o loop não é executado (o que é o comportamento correto).
Já a sequência 1:length(x) retorna a sequência 1:0, isto é, uma sequência decrescente de 1 até 0, e loop é executado nestes valores.
Vejamos:
# cria vetor vazio x <- numeric(0) # 1:length(x) # note que o loop é executado (o que é errado) for(i in 1:length(x)) print(i) ## [1] 1 ## [1] 0 # seq_along # note que o loop não é executado (o que é correto) for(i in seq_along(x)) print(i)
Vetorização, funções nativas e loops
Como vimos, o R é vetorizado. Muitas vezes, quando você pensar que precisa usar um loop, ao pensar melhor, descobrirá que não precisa. Em geral é possível resolver o problema de maneira vetorizada e usando funções nativas do R.
Para quem está aprendendo a programar diretamente com o R, isso é algo que virá naturalmente. Todavia, para quem já sabia programar em outras linguagens de programação – como C – pode ser difícil se acostumar a pensar desta maneira.
Vejamos um exemplo trivial. Suponha que você queira dividir os valores de um vetor x por 10. Se o R não fosse vetorizado, você teria que fazer algo como:
# criando vetor de exemplo x <- 10:20 # divide cada elemento por 10 for(i in seq_along(x)) x[i] <- x[i]/10 # resultado x ## [1] 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
Mas o R é vetorizado e, portanto, este é o tipo de loop que não faz sentido na linguagem. É muito mais rápido e fácil de enteder escrever simplesmente x/10.
# recriando vetor de exemplo x <- 10:20 # divide cada elemento por 10 x <- x/10 x ## [1] 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
Vejamos um caso um pouco mais complicado. Suponha que você queira, gerar um passeio aleatório com um algoritmo simples: a cada período você pode andar para frente (+1) ou para trás (-1) com probabilidades iguais.
set.seed(1)
# número de passos
n <- 1000
# vetor para armazenar o passeio aleatório
passeio <- numeric(n)
# primeiro passo
passeio[1] <- sample(c(-1, 1), 1)
# demais passos
for(i in 2:n){
# passo i é o onte você estava (passeio[i-1])
# mais o passo seguinte
passeio[i] <- passeio[i - 1] + sample(c(-1, 1), 1)
}
É possível fazer tudo isso com apenas uma linha de maneira “vetorizada” e bem mais eficiente: crie todos os n passos de uma vez e faça a soma acumulada.
set.seed(1) passeio2 <- cumsum(sample(c(-1, 1), n, TRUE)) # verifica se são iguais all.equal(passeio, passeio2) ## [1] TRUE
Então, você deve estar se perguntando: “não é para usar loops nunca”?
Não é isso. Em algumas situações loops são inevitáveis e podem inclusive ser mais fáceis de ler e de entender. O ponto aqui é apenas lembrá-lo de explorar a vetorização do R.
Voltando ao nosso exemplo do passeio aleatório, você deve ter notado a linha passeio <- numeric(n) em que criamos um vetor numérico para ir armazenando os resultados das iterações. Discutamos um pouco mais esse ponto.
Pré-alocar espaço antes do loop
Um erro bastante comum de quem está começando a programar em R é “crescer” objetos durante o loop. Isto tem um impacto substancial na performance do seu programa! Sempre que possível, crie um objeto, antes de iniciar o loop, para armazenar os resultados de cada iteração.
Vejamos um exemplo um pouco mais elaborado: vamos calcular os n primeiros números da sequência de Fibonacci: 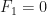



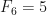
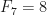


Note que a sequência de Fibonacci pode ser definida da seguinte forma, os primeiros dois números são 0 e 1, isto é, 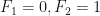
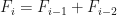
Vejamos uma forma de implementar isto no R usando for() e criando um vetor para armazenar os resultados:
n <- 9
# crie um vetor de tamanho n
# para armazenar os n resultados
fib <- numeric(n)
# comece definindo as condições iniciais
# F1 = 0 e F2 = 1
fib[1] <- 0
fib[2] <- 1
# Agora para todo i > 2
# calculamos Fi = F(i-1) + F(i - 2)
for(i in 3:n){
fib[i] <- fib[i - 1] + fib[i - 2]
}
# conferindo resultado
fib
## [1] 0 1 1 2 3 5 8 13 21
Vamos comparar a performance deste código com outro sem pré-alocar um vetor de resultados. Primeiro, transformemos nosso loop em uma função:
fib <- function(n){
# vetor para armazenar resultados
fib <- numeric(n)
# condições iniciais
fib[1] <- 0
fib[2] <- 1
# calculandos o números de 3 a n
for(i in 3:n){
fib[i] <- fib[i - 1] + fib[i - 2]
}
return(fib)
}
Agora, criemos outra função em que o vetor fib cresce a cada iteração:
fib_sem_pre_alocar <- function(n){
# condições iniciais
fib <- 0
fib <- c(fib, 1)
# calculandos o números de 3 a n
for(i in 3:n){
fib <- c(fib, fib[i - 1] + fib[i - 2])
}
return(fib)
}
Comparando as duas implementações:
library(microbenchmark) set.seed(5) microbenchmark(fib(5000), fib_sem_pre_alocar(5000)) ## Unit: milliseconds ## expr min lq mean median uq max neval cld ## fib(5000) 5.8 6 6.5 6.4 6.9 10 100 a ## fib_sem_pre_alocar(5000) 39.0 53 60.5 56.4 58.9 195 100 b
Note que quanto maior o número de simulações, maior a queda na performance: com n = 5000 a função fib_sem_pre_alocar() chega a ser mais de 10 vezes mais lenta do que a função fib().
Exemplo: entendendo a família apply
Vamos calcular a média de cada uma das colunas do data.frame mtcars usando loops.
Para isso precisamos: (i) saber quantas colunas existem no data.frame; (ii) criar um vetor para armazenar os resultados; (iii) nomear o vetor de resultados com os nomes das colunas; e (iv) fazer um loop para cada coluna.
# (i) quantas colunas no data.frame
n <- ncol(mtcars)
# (ii) vetor para armazenar resultados
medias <- numeric(n)
# (iii) nomeando vetor com nomes das colunas
names(medias) <- colnames(mtcars)
# (iv) loop para cada coluna
for(i in seq_along(mtcars)){
medias[i] <- mean(mtcars[,i])
}
# resultado final
medias
## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp
## 20.09 6.19 230.72 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81 20.09 6.19 230.72
## hp drat wt qsec vs am gear carb
## 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81
Gastamos várias linhas para fazer essa simples operação. Como já vimos, é bastante fácil fazer isso no R com apenas uma linha:
sapply(mtcars, mean) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp ## 20.09 6.19 230.72 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81 20.09 6.19 230.72 ## hp drat wt qsec vs am gear carb ## 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81
Imagine que não existisse a função sapply() no R. Se quiséssemos aplicar outra função para cada coluna, teríamos que copiar e colar todo o código novamente, certo?
Sim, você poderia fazer isso, mas não seria uma boa prática. Neste caso, como já vimos, o ideal seria criar uma função.
Façamos, portanto, uma função que nos permita aplicar uma fução arbitrária nas colunas de um data.frame.
meu_sapply <- function(x, funcao){
n <- length(x)
resultado <- numeric(n)
names(resultado) <- names(x)
for(i in seq_along(x)){
resultado[i] <- funcao(x[[i]])
}
return(resultado)
}
Perceba que ficou bastante simples percorrer todas as colunas de um data.frame para aplicar a função que você quiser:
meu_sapply(mtcars, mean) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp ## 20.09 6.19 230.72 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81 20.09 6.19 230.72 ## hp drat wt qsec vs am gear carb ## 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81 meu_sapply(mtcars, sd) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp ## 6.03 1.79 123.94 68.56 0.53 0.98 1.79 0.50 0.50 0.74 1.62 6.03 1.79 123.94 ## hp drat wt qsec vs am gear carb ## 68.56 0.53 0.98 1.79 0.50 0.50 0.74 1.62 meu_sapply(mtcars, max) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp hp drat ## 33.9 8.0 472.0 335.0 4.9 5.4 22.9 1.0 1.0 5.0 8.0 33.9 8.0 472.0 335.0 4.9 ## wt qsec vs am gear carb ## 5.4 22.9 1.0 1.0 5.0 8.0 meu_sapply(mtcars, min) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp hp drat wt qsec vs am ## 10.4 4.0 71.1 52.0 2.8 1.5 14.5 0.0 0.0 3.0 1.0 10.4 4.0 71.1 52.0 2.8 1.5 14.5 0.0 0.0 ## gear carb ## 3.0 1.0
É isso o que as funções da família apply são: são funções que fazem loops para você. Elas automaticamente cuidam de toda a parte chata do loop como, por exemplo, criar um objeto de tamanho correto para pré-alocar os resultados. Além disso, em grande parte das vezes essas funções serão mais eficientes do que se você mesmo fizer a implementação.
Por curiosidade, vamos comparar a eficiência do sapply() do R com meu_sapply()
microbenchmark(sapply(mtcars, mean), meu_sapply(mtcars, mean)) ## Unit: microseconds ## expr min lq mean median uq max neval cld ## sapply(mtcars, mean) 98 104 113 113 121 180 100 a ## meu_sapply(mtcars, mean) 239 275 286 285 294 360 100 b
Exercícios
As funções que você irá implementar aqui, usando for(), serão até mais de 100 vezes mais lentas do que as funções nativas do R. Estes exercícios são para você treinar a construção de loops, um pouco de lógica de programação, e entender o que as funções do R estão fazendo – de maneira geral – por debaixo dos panos.
1) Crie uma função que encontre o máximo de um vetor (use for() na sua função). Compare os resultados e a performance de sua implementação com a função max() do R. Sua função é quantas vezes mais lenta?
2) Crie uma função que calcule o fatorial de n (use for() na sua função). Compare os resultados e a performance de sua implementação com a função factorial() do R. Sua função é quantas vezes mais lenta?
3) Crie uma função que calcule a soma de um vetor (use for() na sua função). Compare os resultados e a performance de sua implementação com a função sum() do R. Sua função é quantas vezes mais lenta?
4) Crie uma função que calcule a soma acumulada de um vetor (use for() na sua função). Compare os resultados e a performance de sua implementação com a função cumsum() do R. Sua função é quantas vezes mais lenta?
Respostas
Criando vetor aleatório para comparar as funções:
# cria vetor para comparar resultados set.seed(123) x <- rnorm(100) # Pacote para comparar resultados library(microbenchmark)
Resposta sugerida ex-1:
# 1) loop para encontrar máximo
max_loop <- function(x){
max <- x[1]
for(i in 2:length(x)){
if(x[i] > max){
max <- x[i]
}
}
return(max)
}
all.equal(max(x), max_loop(x))
## [1] TRUE
microbenchmark(max(x), max_loop(x))
## Unit: nanoseconds
## expr min lq mean median uq max neval cld
## max(x) 378 544 701 594 672 8366 100 a
## max_loop(x) 83031 85970 91228 88492 94796 156594 100 b
Resposta sugerida ex-2:
# 2) loop para fatorial
fatorial <- function(n){
fat <- 1
for(i in 1:n){
fat <- fat*i
}
return(fat)
}
all.equal(factorial(10), fatorial(10))
## [1] TRUE
microbenchmark(factorial(10), fatorial(10))
## Unit: nanoseconds
## expr min lq mean median uq max neval cld
## factorial(10) 323 381 514 464 552 4755 100 a
## fatorial(10) 3207 3612 4820 3738 3955 29361 100 b
Resposta sugerida ex-3:
# 3) loop para soma
soma <- function(x){
n <- length(x)
soma <- numeric(n)
soma <- x[1]
for(i in 2:n){
soma <- x[i] + soma
}
return(soma)
}
all.equal(soma(x), sum(x))
## [1] TRUE
microbenchmark(sum(x), soma(x))
## Unit: nanoseconds
## expr min lq mean median uq max neval cld
## sum(x) 351 474 662 567 642 8938 100 a
## soma(x) 42717 46671 50345 51072 52788 85080 100 b
Resposta sugerida ex-4:
# 4) loop para soma acumulada
soma_acumulada <- function(x){
n <- length(x)
soma <- numeric(n)
soma[1] <- x[1]
for(i in 2:n){
soma[i] <- x[i] + soma[i-1]
}
return(soma)
}
all.equal(soma_acumulada(x), cumsum(x))
## [1] TRUE
microbenchmark(cumsum(x), soma_acumulada(x))
## Unit: nanoseconds
## expr min lq mean median uq max neval cld
## cumsum(x) 543 616 852 875 942 4625 100 a
## soma_acumulada(x) 128217 139040 145288 143372 149446 184268 100 b
Introdução ao ggplot2
***
Parte do livro Introdução à análise de dados com R. Este trabalho está em andamento, o texto é bastante preliminar e sofrerá muitas alterações.
Quer fazer sugestões? Deixe um comentário abaixo ou, se você sabe utilizar o github, acesse aqui.
Não copie ou reproduza este material sem autorização.
Volte para ver atualizações!
***
Utilizando gráficos para explorar sua base de dados
Os gráficos base do R são bastante poderosos e com eles é possível fazer muita coisa. Entretanto, eles podem ser um pouco demorados para explorar dinamicamente sua base de dados. O pacote ggplot2 é uma alternativa atraente para resolver este problema. O ggplot2 é um pouco diferente de outros pacotes gráficos pois não segue a lógica de desenhar elementos na tela; ao invés disso, a sintaxe do ggplot2 segue uma “gramática de gráficos estatísticos” baseada no Grammar of Graphics de Wilkinson (2005).
No começo, pode parecer um pouco diferente essa forma de construir gráficos. Todavia, uma aprendidos os conceitos básicos da gramática, você vai pensar em gráficos da mesma forma que pensa numa análise de dados, construindo seu gráfico iterativamente, com visualizações que ajudem a revelar padrões e informações interessantes gastando poucas linhas de código. É um investimento que vale a pena.
Nesta seção, faremos uma breve introdução ao pacote ggplot2, destacando seus principais elementos. Para um tratamento mais aprofundado, recomenda-se o livro do Hadley Wickham.
Antes de continuar, você precisa instalar e carregar os pacotes que vamos utilizar nesta seção. Além do próprio ggplot2, vamos utilizar também os pacotes ggthemes e gridExtra.
# Instalando os pacotes (caso não os tenha instalados)
install.packages(c("ggplot2","ggthemes", "gridExtra"))
# Carregando os pacotes
library(ggplot2)
library(ggthemes)
library(gridExtra)
Também vamos utilizar uma base de dados de anúncio de imóveis de Brasília que você pode baixar aqui ou carregar com o comando abaixo. Vamos utilizar apenas os dados de venda.
# Carrega arquivo
arquivo <- url("https://dl.dropboxusercontent.com/u/44201187/imoveis.rds")
con <- gzcon(arquivo)
dados <- readRDS(con)
# Filtra apenas para venda
venda <- dados[dados$tipo == "venda", ]
A “gramática dos gráficos”
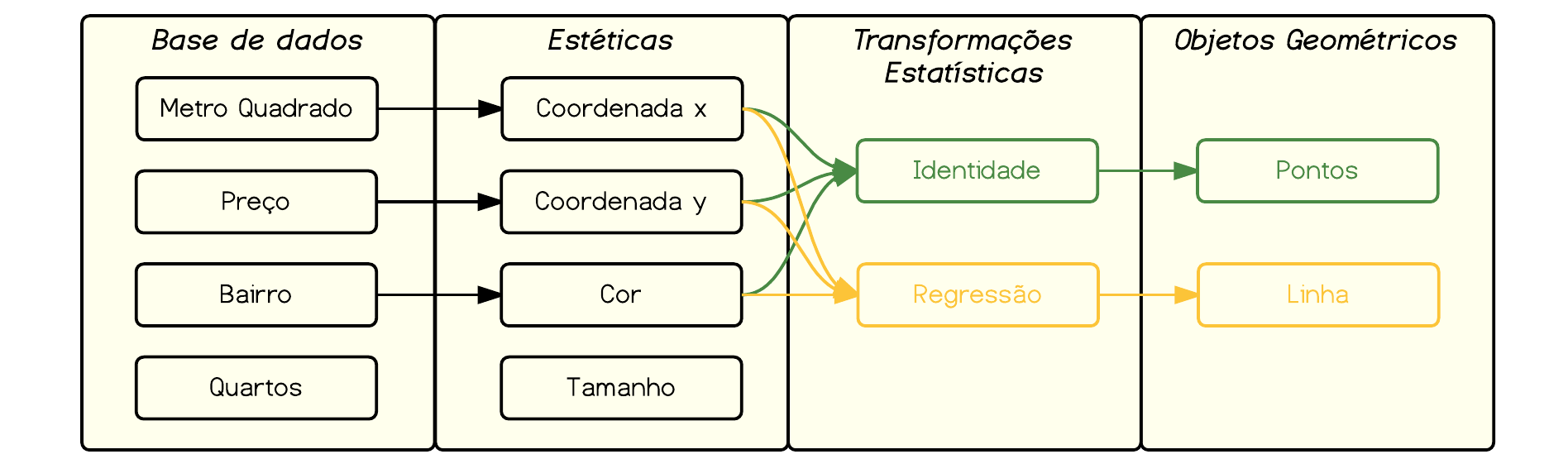
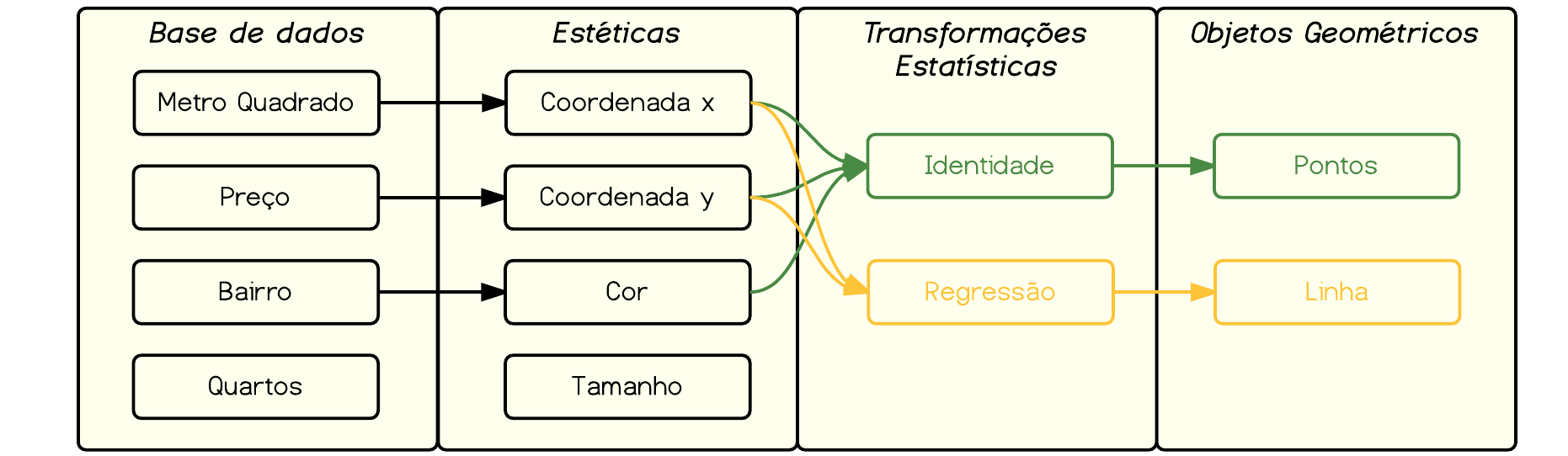
Mas o que seria essa gramática de gráficos estatísticos? Podemos dizer que um gráfico estatístico é um mapeamento dos dados para propriedades estéticas (cor, forma, tamanho) e geométricas (pontos, linhas, barras) da tela. O gráfico também pode conter transformações estatísticas e múltiplas facetas para diferentes subconjuntos dos dados. É a combinação de todas essas camadas que forma seu gráfico estatístico.
Deste modo, os gráficos no ggplot2 são construídos por meio da adição de camadas. Cada camada, grosso modo, é composta de:
- Uma base de dados (um data.frame, preferencialmente no formato long);
- Atributos estéticos (aesthetics);
- Objetos geométricos;
- Transformações estatísticas;
- Facetas; e,
- Demais ajustes.
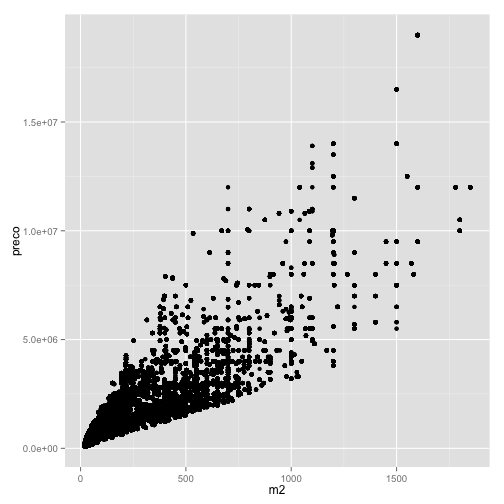
Vejamos um exemplo simples de scatter plot com os dados de preço e metro quadrado dos imóveis da nossa base de dados.
ggplot(data=venda, aes(x=m2, y=preco)) + geom_point()
Traduzindo o comando acima do gpplot2, nós começamos chamando a função ggplot() que inicializa o gráfico com os seguintes parâmetros:
- data: aqui indicamos que estamos usando a base de dados
venda; - aes: aqui indicamos as estéticas que estamos mapeando. Mais especificamente, estamos dizendo que vamos mapear o eixo x na variável
m2e o eixo y na variávelpreco.
Em seguida, adicionamos um objeto geométrico:
- geom_point(): estamos falando ao
ggplotque queremos adicionar o ponto como objeto geométrico.
Com relação às transformações estatísticas, neste caso não estamos realizando nenhuma. Isto é, estamos plotando os dado sem quaisquer modificações. Em termos esquemáticos, nós estamos fazendo o seguinte mapeamento:
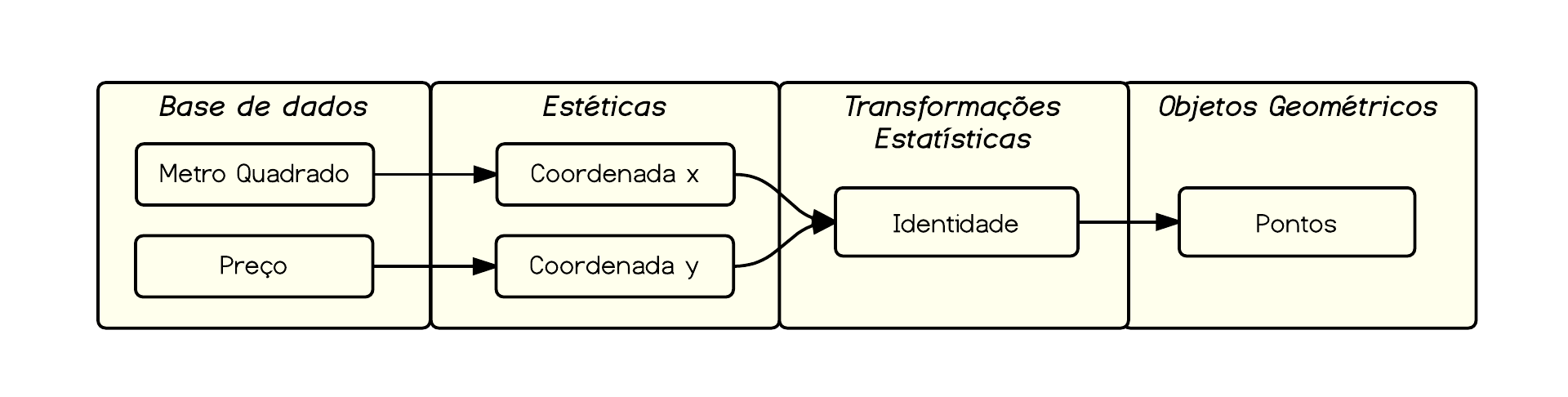
O que resulta no seguinte gráfico:
aes: mapeando cor, tamanho, forma etc
Um gráfico no plano tem apenas duas coordenadas, x e y, mas nossa base de dados tem, em geral, vários colunas… como podemos representá-las? Uma forma de fazer isso é mapear variáveis em outras propriedades estéticas do gráfico, tais como cor, tamanho e forma. Isto é, vamos expandir as variáveis que estamos meapeando nos aesthetics.
Para exemplificar, vamos mapear cada bairro em uma cor diferente e o número de quartos no tamanho dos pontos.
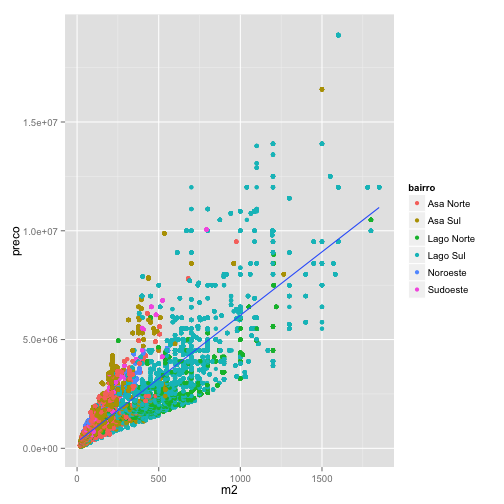
ggplot(data=venda, aes(x = m2, y = preco, color = bairro, size = quartos)) + geom_point()
Nosso esquema anterior ficaria da seguinte forma.
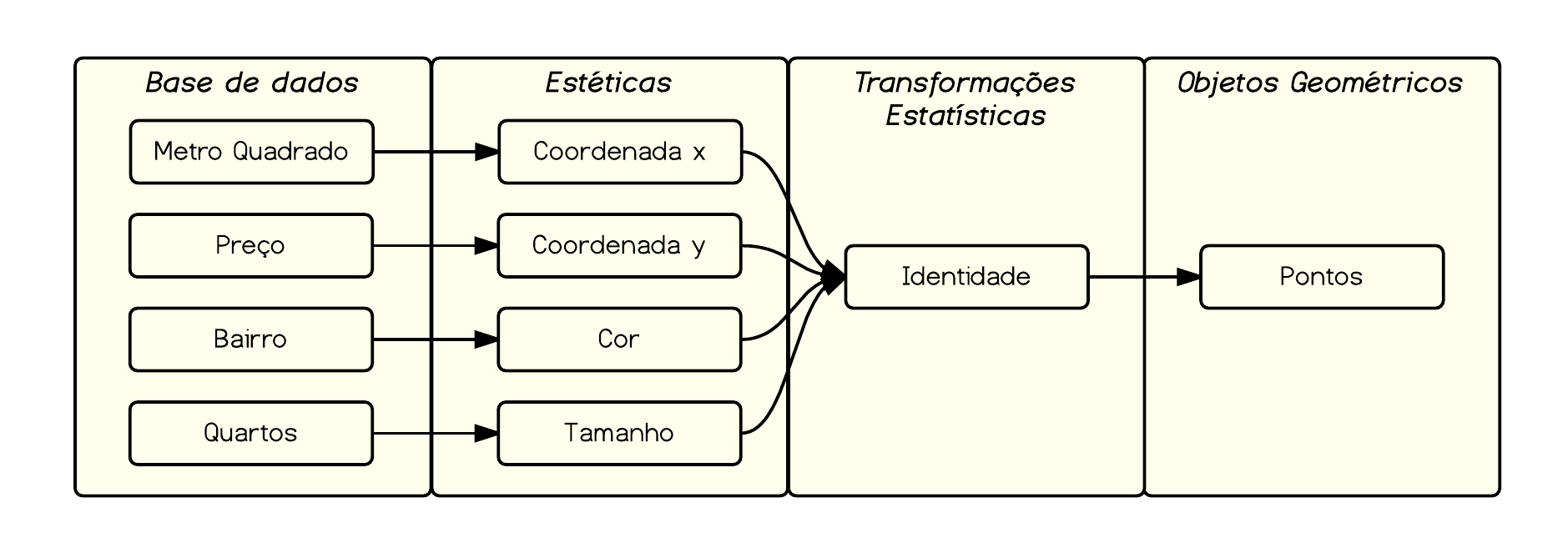
E o gráfico resultante:
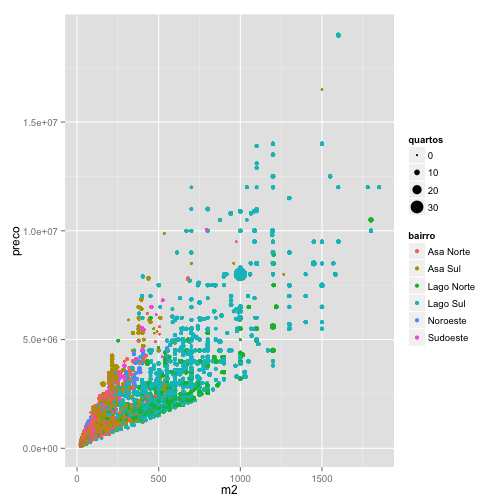
Note que este gráfico revela aspectos diferentes da base de dados, como alguns registros possivelmente errados (imóvel com 30 quartos) e concentração de imóveis grandes em determinados bairros.
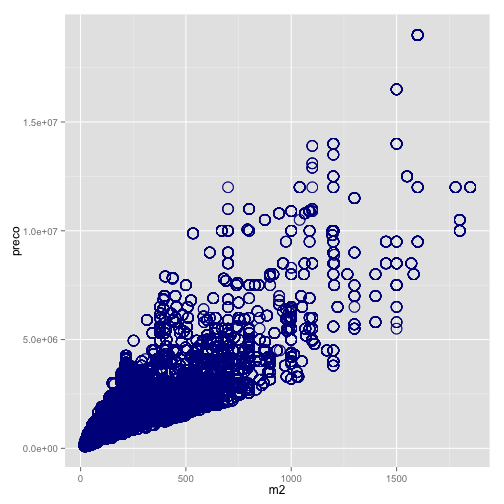
Mapear é diferente de determinar
Uma dúvida bastante comum quando as pessoas começam a aprender o ggplot2 é a diferença entre mapear variáveis em certo atributo estético e determinar certo atributo estético.
Quando estamos mapeando variáveis, fazemos isso dentro do comando aes(). Quando estamos apenas mudando a estética do gráfico, sem vincular isso a alguma variávei, fazemos isso fora do comando aes().
Por exemplo, no comando abaixo mudamos a cor, o tamanho e a forma dos pontos do scatter plot. Entretanto, essas mudanças foram apenas cosméticas e não representam informações de variáveis da base de dados e, portanto, não possuem legenda.
# muda o tamanho, a cor e a forma dos pontos # note que não há legenda, pois não estamos # mapeando os dados a atributos estéticos ggplot(data=venda, aes(x=m2, y=preco)) + geom_point(color="darkblue", shape=21, size = 5)
geoms: pontos, retas, boxplots, regressões
Até agora vimos apenas o geom_poin(), mas o ggplot2 vem com vários geoms diferentes e abaixo listamos os mais utilizados:
| Tipo de Gráfico | geom |
|---|---|
| scatterplot (gráfico de dispersão) | geom_point() |
| barchart (gráfico de barras) | geom_bar() |
| boxplot | geom_boxplot() |
| line chart (gráfico de linhas) | geom_line() |
| histogram (histograma) | geom_histogram() |
| density (densidade) | geom_density() |
| smooth (aplica modelo estatístico) | geom_smooth() |
Aqui, em virtude do espaço, mostraremos apenas um exemplo de gráfico de densidade e boxplot. Experimente em seu computador diferentes geoms na base de dados de imóveis.
# Density ggplot(data=venda, aes(x=preco)) + geom_density(fill = "darkred") # Boxplot ggplot(data=venda, aes(x=bairro, y=preco)) + geom_boxplot(aes(fill = bairro))
Combinando aes e geom
Os gráficos do ggplot2 são construídos em etapas e podemos combinar uma série de camadas compostas de aes e geoms diferentes, adicionando informações ao gráfico iterativamente.
Toda informação que você passa dentro do comando inicial ggplot() é repassada para os geoms() seguintes. Assim, as estéticas que você mapeia dentro do comando ggplot() valem para todas as comadas subsequentes; por outro lado, as estéticas que você mapeia dentro dos geoms valem apenas para aquele geom especificamente. Vejamos um exemplo.
O comando abaixo mapeia o bairro como cor dentro do comando ggplot(). Dessa forma, tanto nos pontos geom_point(), quanto nas regressões geom_smooth() temos cores mapeando bairros, resultando em várias regressões diferentes.
# aes(color) compartilhado ggplot(venda, aes(m2, preco, color=bairro)) + geom_point() + geom_smooth(method="lm")
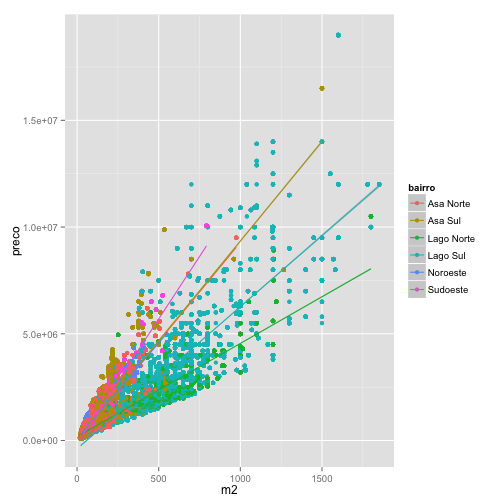
Mas e se você quisesse manter os pontos com cores diferentes com apenas uma regressão para todas observações? Neste caso, temos que mapear os bairros nas cores apenas para os pontos. Note que no comando a seguir passamos a estética color = bairro apenas para geom_poin().
# aes(color) apenas nos pontos ggplot(venda, aes(m2, preco)) + geom_point(aes(color=bairro)) + geom_smooth(method="lm")
Revelando padrões
A combinação simples de estéticas e formas geométricas pode ser bastante poderosa para revelar padrões interessantes nas bases de dados. Vejamos um caso ilustrativo.
Cilindradas, cilindros e Milhas por Galão
A base de dados mpg contém informações sobre eficiência no uso de combustível para diversos modelos de carro de 1999 a 2008. Vejamos um scatter plot relacionando cilindradas e consumo medido por milhas por galão:
ggplot(mpg, aes(displ, hwy)) + geom_point()
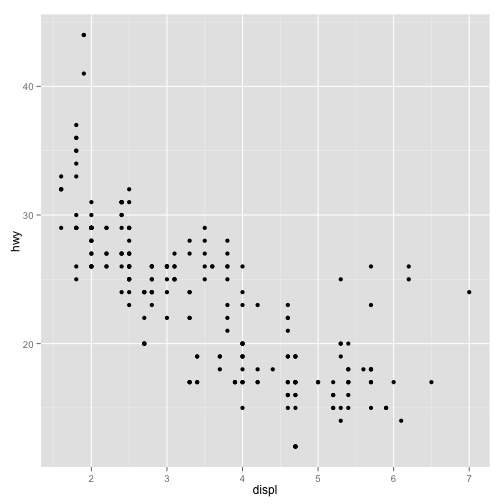
A imagem parece revelar uma relação não linear entre cilindradas e milhas por galão. Vejamos, todavia, o mesmo gráfico mapeando o número de cilindros nas cores:
ggplot(mpg, aes(displ, hwy, col=factor(cyl))) + geom_point() + geom_smooth(method = "lm")
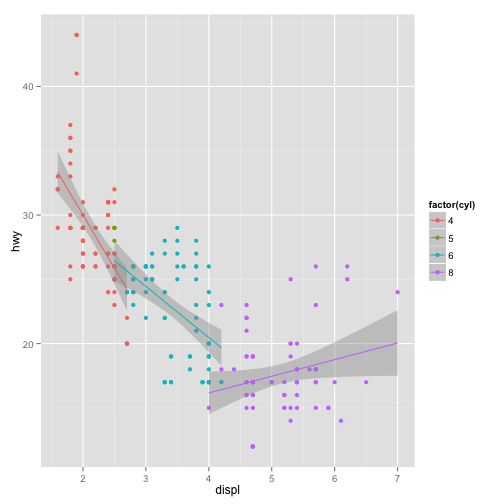
Note que o gráfico parece revelar que, uma vez condicionada ao número de cilindros, a relação entre cilindradas e milhas por galão é razoavelmente linear!
Adicionando facetas
No ggplot2(), você pode dividir o gráfico em diversos subgráficos utilizando variáveis categóricas. Vejamos um exemplo utilizando facet_wrap().
ggplot(venda, aes(m2, preco)) + geom_point(aes(col=factor(quartos))) + geom_smooth(method="lm") + facet_wrap(~bairro)
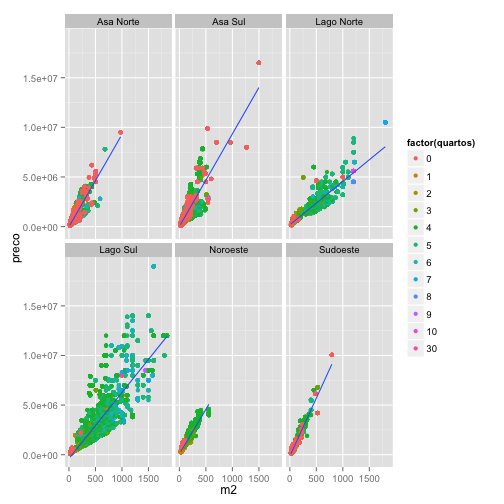
Personalizando seu o gráfico
Depois de chegar em um gráfico interessante, você provavelmente vai querer personalizar detalhes estéticos deste gráfico para apresentá-lo ao público. No ggplot2 é possível fazer o ajuste fino de diversos elementos do seu gráfico e o detalhamento disso fugiria ao escopo deste livro.
Entretanto, vejamos um exemplo de histograma com a personalização de alguns elementos, adicionando labels, títulos, e mudando o fundo para branco:
media <- mean(log(venda$preco))
dp <- sd(log(venda$preco))
ggplot(data=venda, aes(x=log(preco))) +
geom_histogram(aes(y = ..density..), binwidth=0.3, fill="lightblue", col="black") +
stat_function(fun=dnorm, args=list(mean=media, sd=dp), color="red") +
geom_rug() + # adiciona rug no eixo x
xlab("Log do Preço") + # adiciona descrição do eixo x
ylab("Densidade") + # adiciona descrição do eixo y
ggtitle("Histograma Preços de Imóveis") + # adiciona título
theme_bw() # adciona tema "Black and White"
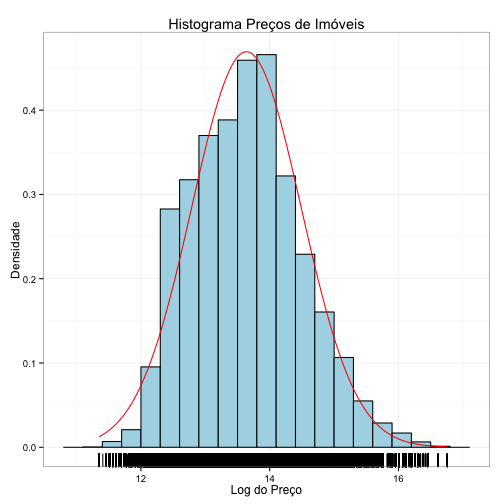
Ficou bonito, não?
Temas pré prontos – ggthemes
O pacote ggthemes já vem com vários temas pré-programados, replicando formatações de sites como The Economist, The Wall Street Journal, FiveThirtyEight, ou de outros aplicativos como o Stata, Excel entre outros. Esta é uma forma rápida e fácil de adicionar um estilo diferente ao seu gráfico.
Experimente com os temas abaixo (gráficos omitidos aqui):
grafico <- ggplot(mpg, aes(displ, hwy, col=factor(cyl))) + geom_point() +
geom_smooth(method = "lm", se = F) + ggtitle("Cilindradas, cilindros e Milhas por Galão") +
ylab("Milhas por galão") + xlab("Cilindradas")
# Gráfico original
grafico
# Tema "The Economist" com respectiva escala de cores grafico + theme_economist() + scale_color_economist()
# Tema "The Wall Street Journal" com respectiva escala de cores grafico + theme_wsj() + scale_color_wsj()
# Tema "Excel" com respectiva escala de cores grafico + theme_excel() + scale_color_excel()
# Tema "fivethirtyeight" grafico + theme_fivethirtyeight()
# Tema "highcharts" com respectiva escala de cores grafico + theme_hc() + scale_color_hc()
# Tema "Tufte" grafico + theme_tufte()
# Tema "Stata" com respectiva escala de cores grafico + theme_stata() + scale_color_stata()
Vários gráficos juntos
Por fim, uma última dica e como colocar vários gráficos juntos com a função grid.arrange().
g1 <- grafico + theme_fivethirtyeight() g2 <- grafico + theme_hc() + scale_color_hc() g3 <- grafico + theme_tufte() g4 <- grafico + theme_stata() + scale_color_stata() grid.arrange(g1, g2, g3, g4)
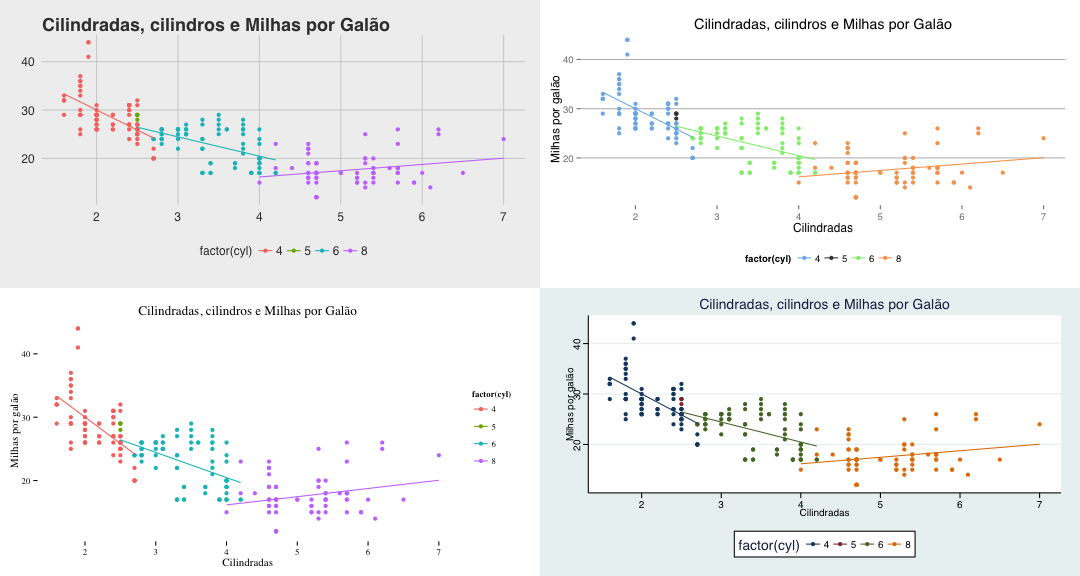
Programming tools: Adventures with R
Ainda está na dúvida se vale a pena aprender R? Então de uma olhada neste pequeno artigo da Nature sobre a linguagem.
Links diversos: o Estatístico Automático e um pouco de história do R.
Seguem alguns links interessantes:
1. Andrew Gelman comentou sobre o estatístico automático e resolvi testar. Como ainda é um protótipo, por enquanto o site só trabalha com modelos lineares. O que o algoritmo tentará fazer? O seguinte:
(…) the automatic statistician will attempt to describe the final column of your data in terms of the rest of the data. After constructing a model of your data, it will then attempt to falsify its claims to see if there is any aspect of the data that has not been well captured by its model.
Testei com os dados dos votos municipais na Dilma vs variáveis socio-econômicas dos municípios (primeiro turno). Veja aqui os resultados.
2. Ok, este link só vai ser interessante se você tiver um pouco de curiosidade sobre o R. Rasmus Baath comprou os livros das antigas versões do S (a linguagem que deu origem ao R) e ressaltou alguns pontos interessantes sobre o desenvolvimento da linguagem ao longo do tempo.
useR! 2014 – Entrevistas com JJ Allaire e Joe Cheng
Excelente entrevista com o criador do RStudio, JJ Allaire. A combinação R+Rstudio certamente é um dos melhores e mais fáceis ambientes gratuitos para a análise interativa de dados, virtualmente sem competição se considerarmos usuários que não são desenvolvedores de software (a maioria). Sem contar os desenvolvimentos recentes de pacotes como knitr e packrat para reproducibilidade de pesquisas, ou shiny e ggvis para aplicativos web.
Aproveitando, vale a pena também ver a entrevista com Joe Cheng, engenheiro de software do RStudio, um dos responsáveis pelo shiny.
useR! 2014 – Entrevista com Romain Francois
Eduardo está liberando as entrevistas aos poucos, e agora saiu a do Roman Francois!
Romain, além de gente boa, é um dos caras por trás dos avanços na integração do R com C++ (Rcpp) e C++11 (Rcpp11). Além disso, Romain, junto com Hadley, tem criado pacotes fantásticos (e rápidos) como o dplyr. Vale a pena conferir a entrevista.
