***
Parte do livro Introdução à análise de dados com R. Este trabalho está em andamento, o texto é bastante preliminar e sofrerá muitas alterações.
Quer fazer um curso presencialmente!? Estamos com turmas abertas em Brasília e São Paulo!
Quer fazer sugestões? Deixe um comentário abaixo ou, se você sabe utilizar o github, acesse aqui.
Não copie ou reproduza este material sem autorização.
Volte para ver atualizações!
***
Loops: for()
Um loop utilizando for() no R tem a seguinte estrutura básica:
for(i in conjunto_de_valores){
# comandos que
# serão repetidos
}
- O início do loop se dá com o comando
forseguido de parênteses e chaves; - Dentro do parênteses temos um indicador que será usado durante o loop (no caso escolhemos o nome
i) e um conjunto de valores que será iterado (conjunto_de_valores). - Dentro das chaves temos o bloco de código que será executado durante o loop.
Em outras palavras, no comando acima estamos dizendo que para cada elemento i contido no conjunto_de_valores iremos executar os comandos que estão dentro das chaves.
Para facilitar o entendimento, vejamos dois exemplos muito simples. Primeiro, vamos imprimir na tela os números de 1 a 5.
for(i in 1:5){
print(i)
}
## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
Agora, vamos imprimir na tela as 5 primeiras letras do alfabeto (o R já vem com um vetor com as letras do alfabeto: letters).
for(i in 1:5){
print(letters[i])
}
## [1] "a"
## [1] "b"
## [1] "c"
## [1] "d"
## [1] "e"
No mesmo exemplo, acima, ao invés correr o loop no índice de inteiros 1:5, vamos iterar diretamente sobre os primeiros 5 elementos do vetor letters:
for(letra in letters[1:5]){
print(letra)
}
## [1] "a"
## [1] "b"
## [1] "c"
## [1] "d"
## [1] "e"
seq_along
Uma função bastante útil ao fazer loops é a função seg_along(). Ela cria um vetor de inteiros com índices para acompanhar o objeto.
# criando um vetor de exemplo set.seed(119) x <- rnorm(10) # inteiros de 1 a 10 seq_along(x) ## [1] 1 2 3 4 5 6 7 8 9 10
Também é possível criar um vetor de inteiros do tamanho do objeto fazendo uma sequência de 1 até length(x):
1:length(x) ## [1] 1 2 3 4 5 6 7 8 9 10
Entretanto, a vantagem de seq_along() é que quando o vetor é vazio, ela retorna um vetor vazio e, deste modo, o loop não é executado (o que é o comportamento correto).
Já a sequência 1:length(x) retorna a sequência 1:0, isto é, uma sequência decrescente de 1 até 0, e loop é executado nestes valores.
Vejamos:
# cria vetor vazio x <- numeric(0) # 1:length(x) # note que o loop é executado (o que é errado) for(i in 1:length(x)) print(i) ## [1] 1 ## [1] 0 # seq_along # note que o loop não é executado (o que é correto) for(i in seq_along(x)) print(i)
Vetorização, funções nativas e loops
Como vimos, o R é vetorizado. Muitas vezes, quando você pensar que precisa usar um loop, ao pensar melhor, descobrirá que não precisa. Em geral é possível resolver o problema de maneira vetorizada e usando funções nativas do R.
Para quem está aprendendo a programar diretamente com o R, isso é algo que virá naturalmente. Todavia, para quem já sabia programar em outras linguagens de programação – como C – pode ser difícil se acostumar a pensar desta maneira.
Vejamos um exemplo trivial. Suponha que você queira dividir os valores de um vetor x por 10. Se o R não fosse vetorizado, você teria que fazer algo como:
# criando vetor de exemplo x <- 10:20 # divide cada elemento por 10 for(i in seq_along(x)) x[i] <- x[i]/10 # resultado x ## [1] 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
Mas o R é vetorizado e, portanto, este é o tipo de loop que não faz sentido na linguagem. É muito mais rápido e fácil de enteder escrever simplesmente x/10.
# recriando vetor de exemplo x <- 10:20 # divide cada elemento por 10 x <- x/10 x ## [1] 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
Vejamos um caso um pouco mais complicado. Suponha que você queira, gerar um passeio aleatório com um algoritmo simples: a cada período você pode andar para frente (+1) ou para trás (-1) com probabilidades iguais.
set.seed(1)
# número de passos
n <- 1000
# vetor para armazenar o passeio aleatório
passeio <- numeric(n)
# primeiro passo
passeio[1] <- sample(c(-1, 1), 1)
# demais passos
for(i in 2:n){
# passo i é o onte você estava (passeio[i-1])
# mais o passo seguinte
passeio[i] <- passeio[i - 1] + sample(c(-1, 1), 1)
}
É possível fazer tudo isso com apenas uma linha de maneira “vetorizada” e bem mais eficiente: crie todos os n passos de uma vez e faça a soma acumulada.
set.seed(1) passeio2 <- cumsum(sample(c(-1, 1), n, TRUE)) # verifica se são iguais all.equal(passeio, passeio2) ## [1] TRUE
Então, você deve estar se perguntando: “não é para usar loops nunca”?
Não é isso. Em algumas situações loops são inevitáveis e podem inclusive ser mais fáceis de ler e de entender. O ponto aqui é apenas lembrá-lo de explorar a vetorização do R.
Voltando ao nosso exemplo do passeio aleatório, você deve ter notado a linha passeio <- numeric(n) em que criamos um vetor numérico para ir armazenando os resultados das iterações. Discutamos um pouco mais esse ponto.
Pré-alocar espaço antes do loop
Um erro bastante comum de quem está começando a programar em R é “crescer” objetos durante o loop. Isto tem um impacto substancial na performance do seu programa! Sempre que possível, crie um objeto, antes de iniciar o loop, para armazenar os resultados de cada iteração.
Vejamos um exemplo um pouco mais elaborado: vamos calcular os n primeiros números da sequência de Fibonacci: 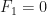



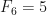
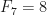


Note que a sequência de Fibonacci pode ser definida da seguinte forma, os primeiros dois números são 0 e 1, isto é, 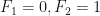
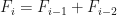
Vejamos uma forma de implementar isto no R usando for() e criando um vetor para armazenar os resultados:
n <- 9
# crie um vetor de tamanho n
# para armazenar os n resultados
fib <- numeric(n)
# comece definindo as condições iniciais
# F1 = 0 e F2 = 1
fib[1] <- 0
fib[2] <- 1
# Agora para todo i > 2
# calculamos Fi = F(i-1) + F(i - 2)
for(i in 3:n){
fib[i] <- fib[i - 1] + fib[i - 2]
}
# conferindo resultado
fib
## [1] 0 1 1 2 3 5 8 13 21
Vamos comparar a performance deste código com outro sem pré-alocar um vetor de resultados. Primeiro, transformemos nosso loop em uma função:
fib <- function(n){
# vetor para armazenar resultados
fib <- numeric(n)
# condições iniciais
fib[1] <- 0
fib[2] <- 1
# calculandos o números de 3 a n
for(i in 3:n){
fib[i] <- fib[i - 1] + fib[i - 2]
}
return(fib)
}
Agora, criemos outra função em que o vetor fib cresce a cada iteração:
fib_sem_pre_alocar <- function(n){
# condições iniciais
fib <- 0
fib <- c(fib, 1)
# calculandos o números de 3 a n
for(i in 3:n){
fib <- c(fib, fib[i - 1] + fib[i - 2])
}
return(fib)
}
Comparando as duas implementações:
library(microbenchmark) set.seed(5) microbenchmark(fib(5000), fib_sem_pre_alocar(5000)) ## Unit: milliseconds ## expr min lq mean median uq max neval cld ## fib(5000) 5.8 6 6.5 6.4 6.9 10 100 a ## fib_sem_pre_alocar(5000) 39.0 53 60.5 56.4 58.9 195 100 b
Note que quanto maior o número de simulações, maior a queda na performance: com n = 5000 a função fib_sem_pre_alocar() chega a ser mais de 10 vezes mais lenta do que a função fib().
Exemplo: entendendo a família apply
Vamos calcular a média de cada uma das colunas do data.frame mtcars usando loops.
Para isso precisamos: (i) saber quantas colunas existem no data.frame; (ii) criar um vetor para armazenar os resultados; (iii) nomear o vetor de resultados com os nomes das colunas; e (iv) fazer um loop para cada coluna.
# (i) quantas colunas no data.frame
n <- ncol(mtcars)
# (ii) vetor para armazenar resultados
medias <- numeric(n)
# (iii) nomeando vetor com nomes das colunas
names(medias) <- colnames(mtcars)
# (iv) loop para cada coluna
for(i in seq_along(mtcars)){
medias[i] <- mean(mtcars[,i])
}
# resultado final
medias
## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp
## 20.09 6.19 230.72 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81 20.09 6.19 230.72
## hp drat wt qsec vs am gear carb
## 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81
Gastamos várias linhas para fazer essa simples operação. Como já vimos, é bastante fácil fazer isso no R com apenas uma linha:
sapply(mtcars, mean) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp ## 20.09 6.19 230.72 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81 20.09 6.19 230.72 ## hp drat wt qsec vs am gear carb ## 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81
Imagine que não existisse a função sapply() no R. Se quiséssemos aplicar outra função para cada coluna, teríamos que copiar e colar todo o código novamente, certo?
Sim, você poderia fazer isso, mas não seria uma boa prática. Neste caso, como já vimos, o ideal seria criar uma função.
Façamos, portanto, uma função que nos permita aplicar uma fução arbitrária nas colunas de um data.frame.
meu_sapply <- function(x, funcao){
n <- length(x)
resultado <- numeric(n)
names(resultado) <- names(x)
for(i in seq_along(x)){
resultado[i] <- funcao(x[[i]])
}
return(resultado)
}
Perceba que ficou bastante simples percorrer todas as colunas de um data.frame para aplicar a função que você quiser:
meu_sapply(mtcars, mean) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp ## 20.09 6.19 230.72 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81 20.09 6.19 230.72 ## hp drat wt qsec vs am gear carb ## 146.69 3.60 3.22 17.85 0.44 0.41 3.69 2.81 meu_sapply(mtcars, sd) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp ## 6.03 1.79 123.94 68.56 0.53 0.98 1.79 0.50 0.50 0.74 1.62 6.03 1.79 123.94 ## hp drat wt qsec vs am gear carb ## 68.56 0.53 0.98 1.79 0.50 0.50 0.74 1.62 meu_sapply(mtcars, max) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp hp drat ## 33.9 8.0 472.0 335.0 4.9 5.4 22.9 1.0 1.0 5.0 8.0 33.9 8.0 472.0 335.0 4.9 ## wt qsec vs am gear carb ## 5.4 22.9 1.0 1.0 5.0 8.0 meu_sapply(mtcars, min) ## mpg cyl disp hp drat wt qsec vs am gear carb mpg cyl disp hp drat wt qsec vs am ## 10.4 4.0 71.1 52.0 2.8 1.5 14.5 0.0 0.0 3.0 1.0 10.4 4.0 71.1 52.0 2.8 1.5 14.5 0.0 0.0 ## gear carb ## 3.0 1.0
É isso o que as funções da família apply são: são funções que fazem loops para você. Elas automaticamente cuidam de toda a parte chata do loop como, por exemplo, criar um objeto de tamanho correto para pré-alocar os resultados. Além disso, em grande parte das vezes essas funções serão mais eficientes do que se você mesmo fizer a implementação.
Por curiosidade, vamos comparar a eficiência do sapply() do R com meu_sapply()
microbenchmark(sapply(mtcars, mean), meu_sapply(mtcars, mean)) ## Unit: microseconds ## expr min lq mean median uq max neval cld ## sapply(mtcars, mean) 98 104 113 113 121 180 100 a ## meu_sapply(mtcars, mean) 239 275 286 285 294 360 100 b
Exercícios
As funções que você irá implementar aqui, usando for(), serão até mais de 100 vezes mais lentas do que as funções nativas do R. Estes exercícios são para você treinar a construção de loops, um pouco de lógica de programação, e entender o que as funções do R estão fazendo – de maneira geral – por debaixo dos panos.
1) Crie uma função que encontre o máximo de um vetor (use for() na sua função). Compare os resultados e a performance de sua implementação com a função max() do R. Sua função é quantas vezes mais lenta?
2) Crie uma função que calcule o fatorial de n (use for() na sua função). Compare os resultados e a performance de sua implementação com a função factorial() do R. Sua função é quantas vezes mais lenta?
3) Crie uma função que calcule a soma de um vetor (use for() na sua função). Compare os resultados e a performance de sua implementação com a função sum() do R. Sua função é quantas vezes mais lenta?
4) Crie uma função que calcule a soma acumulada de um vetor (use for() na sua função). Compare os resultados e a performance de sua implementação com a função cumsum() do R. Sua função é quantas vezes mais lenta?
Respostas
Criando vetor aleatório para comparar as funções:
# cria vetor para comparar resultados set.seed(123) x <- rnorm(100) # Pacote para comparar resultados library(microbenchmark)
Resposta sugerida ex-1:
# 1) loop para encontrar máximo
max_loop <- function(x){
max <- x[1]
for(i in 2:length(x)){
if(x[i] > max){
max <- x[i]
}
}
return(max)
}
all.equal(max(x), max_loop(x))
## [1] TRUE
microbenchmark(max(x), max_loop(x))
## Unit: nanoseconds
## expr min lq mean median uq max neval cld
## max(x) 378 544 701 594 672 8366 100 a
## max_loop(x) 83031 85970 91228 88492 94796 156594 100 b
Resposta sugerida ex-2:
# 2) loop para fatorial
fatorial <- function(n){
fat <- 1
for(i in 1:n){
fat <- fat*i
}
return(fat)
}
all.equal(factorial(10), fatorial(10))
## [1] TRUE
microbenchmark(factorial(10), fatorial(10))
## Unit: nanoseconds
## expr min lq mean median uq max neval cld
## factorial(10) 323 381 514 464 552 4755 100 a
## fatorial(10) 3207 3612 4820 3738 3955 29361 100 b
Resposta sugerida ex-3:
# 3) loop para soma
soma <- function(x){
n <- length(x)
soma <- numeric(n)
soma <- x[1]
for(i in 2:n){
soma <- x[i] + soma
}
return(soma)
}
all.equal(soma(x), sum(x))
## [1] TRUE
microbenchmark(sum(x), soma(x))
## Unit: nanoseconds
## expr min lq mean median uq max neval cld
## sum(x) 351 474 662 567 642 8938 100 a
## soma(x) 42717 46671 50345 51072 52788 85080 100 b
Resposta sugerida ex-4:
# 4) loop para soma acumulada
soma_acumulada <- function(x){
n <- length(x)
soma <- numeric(n)
soma[1] <- x[1]
for(i in 2:n){
soma[i] <- x[i] + soma[i-1]
}
return(soma)
}
all.equal(soma_acumulada(x), cumsum(x))
## [1] TRUE
microbenchmark(cumsum(x), soma_acumulada(x))
## Unit: nanoseconds
## expr min lq mean median uq max neval cld
## cumsum(x) 543 616 852 875 942 4625 100 a
## soma_acumulada(x) 128217 139040 145288 143372 149446 184268 100 b

Pingback: Dica R do Dia – mais um capítulo do livro do Cinelli | De Gustibus Non Est Disputandum
Olá, gostei muito das suas explicações de como usar loop no R. Será que vc pode me ajudar num passo um pouco mais elaborado?
Quero criar uma nova coluna no meu dataframe que seja uma sequência de números para cada valor de uma determinada coluna que esteja no intervalo de 0.3.
Por exemplo, tenho uma coluna com os valores (0.74, 0.78, 0.88, 0.94, 1.08, 2.14, 2.62, 3.22, 3.46, 3.48, 5.02) e quero criar uma coluna que atribua valores para cada intervalo de 0.3 da coluna anterior, ou seja (3 3 3 4 4 8 9 11 12 12 17).
Como informar ao R que quero a classificação em intervalos?
O que eu fiz foi usar a a função cut(), como neste exemplo:
dados$Sector<-cut(dados$Stretch, breaks= c(-Inf, 0.3, 0.6, 0.9, 1.2, 1.5, 1.8, 2.1, 2.4, 2.7, 3, 3.3, 3.6, 3.9, 4.2, 4.5, 4.8, 5.1, Inf), labels=F, right=F)
E isso resultou no que eu queria, mas para aplicar isso aos meus dados eu teria que digitar mais de 8 mil intervalos, o que não acho muito razoável.
Você conhece alguma maneira de falar pro R que eu quero que ele separe a cada intervalo de 0.3?
CurtirCurtir
Pingback: Por que loops são lentos no R? Como evitá-los? - rr loop - Perguntas e Respostas