Quer ver um modelo de Redes Neurais sendo treinado ao vivo? Dê um pulo no TensorFlow playground:

Hoje descobri que é possível fazer o download de todo seu histórico de buscas no Google. TODO seu histórico de TUDO o que você busca no Google. Já que a opção está disponível, por que não dar uma olhada nos dados?
Por alguma razão meu histórico só vai até 2014 — acredito que tenha deletado o histórico anterior — então no meu caso temos apenas dois anos de dados para analisar (não vou considerar 2016 aqui pois o ano ainda não terminou). Além disso, esses dados certamente não contemplam tudo o que pesquisei na internet neste período, porque: (i) além do Google eu uso o DuckDuckGo; e, (ii) muitas vezes não estou logado quando faço pesquisas no próprio Google.
Feitas as ressalvas anteriores, a primeira coisa que tentei montar foi uma nuvem com as palavras mais utilizadas nas buscas. Em 2014 e 2015, segundo o registro do google, fiz aproximadamente 19 mil buscas, utilizando aproximadamente 69 mil palavras-chave. Após remover algumas “stopwords” em inglês e português — isto é, preposições, artigos etc — fiz uma nuvem com aquelas palavras que representam cerca de 20% da frequência total, e o resultado foi o seguinte:

Não tem muita surpresa aí. Previsivelmente, “R” foi a palavra chave mais utilizada, seguida de “package”, “statistics”, “Mac”, “Data”, “Los Angeles”, “UCLA” entre outras.
Após verificar as palavras mais utilizadas, procurei ver se encontrava alguns padrões nos meus hábitos de busca. Primeiramente, calculei a média de buscas por dia da semana. Nesses dois anos, as buscas parecem ter alcançado seu pico de segunda a quarta:
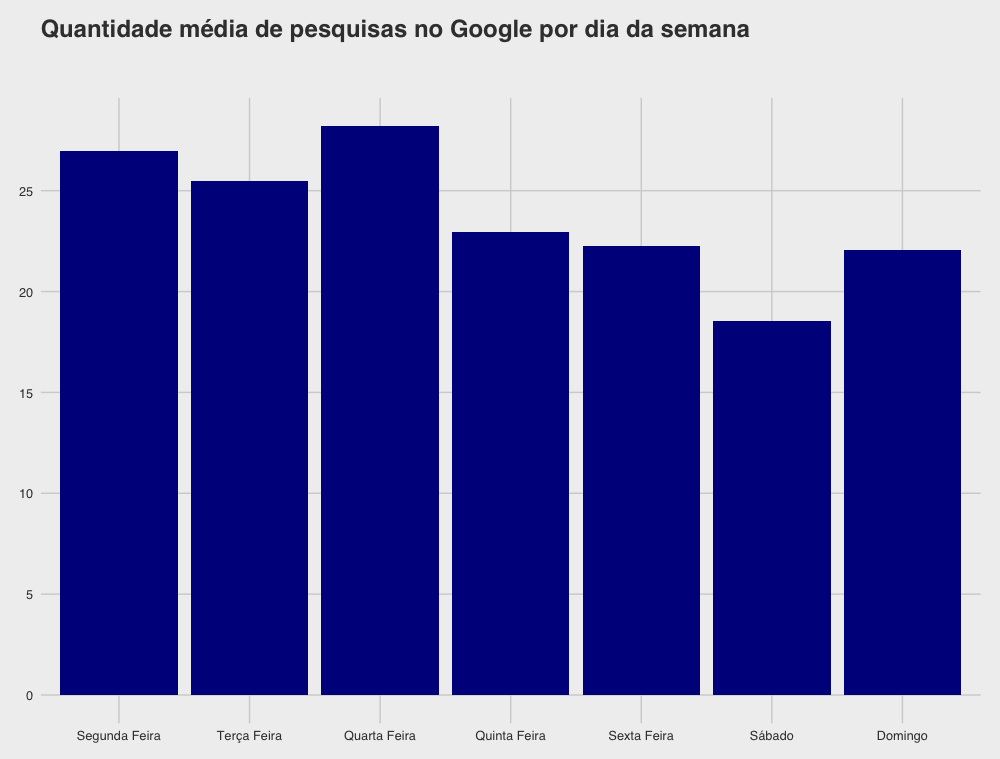
Em seguida calculei a média por hora. Tirando a madrugada e o início da manhã, não parece existir diferença significativa entre os horários. Há, contudo, um problema com essa informação: elas estão no horário brasileiro. Como estive fora do país em certas datas, isso distorce o horário original de algumas pesquisas — e ainda não descobri como consertar esse problema de maneira automática.
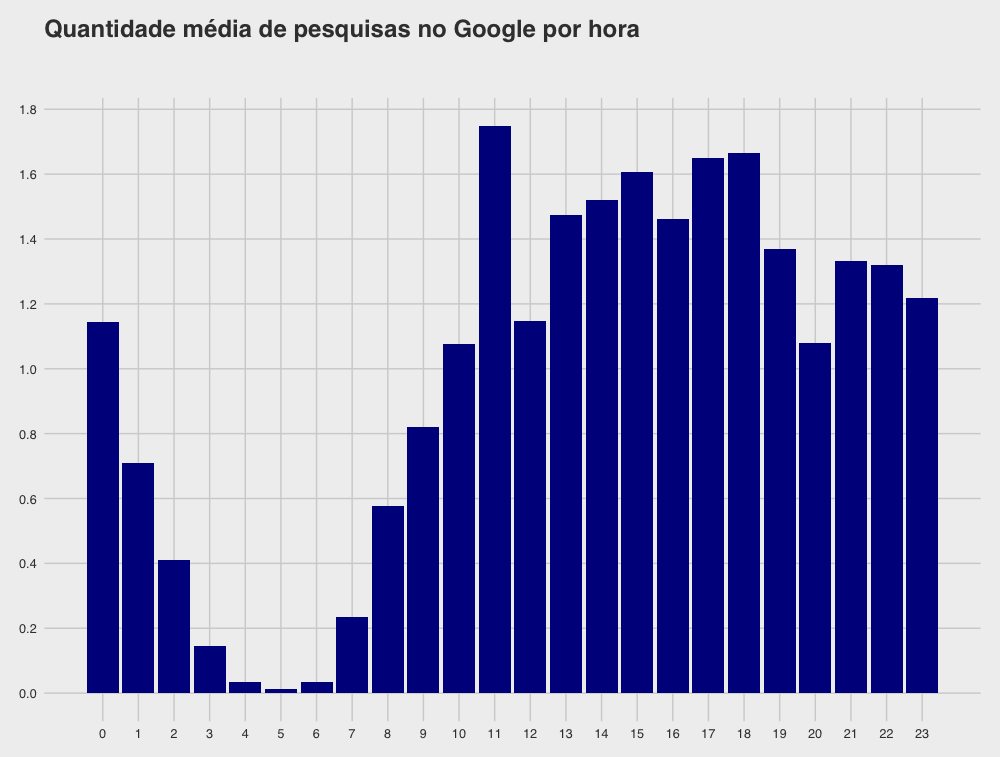
Essa questão das viagens para fora do país suscitou outra pergunta: o total de buscas no Google Maps altera quando estou viajando? A princípio, diria que sim, e é isso o que o gráfico a seguir mostra, com algumas viagens destacadas:

Isto é, pelo menos neste caso, é muito fácil identificar viagens utilizando apenas a série histórica do total de buscas do Google Maps.
Para finalizar, montei um gráfico com a média de pesquisas por hora, separados por dia da semana e ano, mas não parece ter havido mudança relevante entre os padrões de 2014 e 2015.

Quer analisar seus dados também?
Para fazer o download dos dados, basta seguir essas instruções. Os dados virão em um arquivo zip com vários arquivos no formato JSON. Para tratá-los, você pode se basear no script de R que coloquei aqui.
PS: É um pouco assustador perceber que, com análises bastante simples de dados de busca, já é possível inferir bastante coisa sobre os hábitos de uma pessoa.
Se eu tiver que passar uma impressão principal do useR! 2015 é a de que o R provavelmente chegou em um tipping point e está se tornando, oficialmente, mainstream.
O grande diferencial do R sempre foi sua comunidade com a grande quantidade de pacotes disponíveis. Entretanto, como a comunidade era basicamente em torno do meio acadêmico, havia um pouco mais de dificuldade de dedicar recursos para aplicações comerciais e corporativas. Além disso, por ser uma linguagem feita por e para estatísticos, não necessariamente a implementação atual é a mais eficiente, podendo, em algumas circunstâncias, deixar a desejar em performance (mas garantindo correição e acurácia).
Esses são dois pontos que já estão mudando: (i) várias empresas (como Microsoft, Rstudio, Oracle, Google) se reuniram oficialmente para colocar dinheiro na comunidade do R; e, (ii) a popularidade do R está estimulando iniciativas para o tornar mais rápido e eficiente. Acredito que em pouco tempo veremos os benefícios disso.
Empresas investindo na comunidade: o R Consortium
A Linux Foundation anunciou a criação do R Consortium, uma organização com o objetivo de dar suporte à R Foundation e às demais organizações envolvidas com o desenvolvimento do R. Em resumo, as empresas participantes do consórcio vão se juntar para colocar dinheiro no desenvolvimento de projetos em torno da linguagem principalmente em projetos de infraestrutura (como o R-Forge ou o próprio encontro anual useR! – que será em Stanford em 2016).
Entre os fundadores estão:
Durante o encontro, todas as empresas mostraram que já implementaram (ou estão implementando) aplicações corporativas do R em seus produtos, como, por exemplo, o R dentro do SQL server 2016 da Microsoft.
O R está ficando e vai ficar ainda mais rápido e eficiente
A popularidade do R está estimulando uma saudável competição em torno de uma implementação eficiente da linguagem. Além do trabalho da Microsoft com a Revolution R – ou de outras implementações corporativas – duas apresentações chamaram bastante a atenção: (i) o projeto CXXR que reescreve o interpretador do R em C++; e, (ii) o fastR da Oracle que – na verdade dentro de um projeto mais ambicioso envolvendo várias linguagens – reescreve o interpretador do R em Java. O fastR não tem uma data precisa para soltar uma versão plenamente funcional, mas o CXXR, aparentemente, já vai ter uma versão compatível com o GNU R a partir da próxima versão (3.3).
***
Faço questão de ressaltar aqui – como muitos já o fizeram – que a organização do useR! 2015 foi impecável! Mesmo com um público duas vezes maior do que o esperado (foram mais de 650 pessoas) tudo correu perfeitamente, tendo, inclusive, jantar Viking com arremessos de machados (literalmente). Meus parabéns para o pessoal da universidade de Aalborg e, em especial, ao Torben Tvedebrink – ano que vem o encontro será em Stanford e Aalborg elevou o nível para os próximos organizadores.

Vai fazer análise de séries temporais? Agora você também pode testá-las no Estatístico Automático. Dê uma olhada nos exemplos, são bem interessantes. E parece que o projeto está caminhando, o Google resolveu investir na iniciativa.
Momento Urban Demographics no Análise Real.
O Google lançou uma página, Brazil’s Painted Streets, em que você pode passear pelas ruas decoradas para a copa no Brasil:

E também tem um vídeo no YouTube:
Bem bacana.
Mas, como contraponto, vale colocar as pinturas contra a copa elencadas no The Guardian:

Enquanto Breaking Bad não volta, comecei a assistir ao seriado Numb3rs, cujo enredo trata do uso da matemática e da estatística na solução de crimes. Confesso que, a princípio, estava receoso. Na maior parte das vezes, filmes e seriados que tratam desses temas costumam, ou mistificar a matemática, ou conter erros crassos.
Todavia, o primeiro episódio da série abordou uma equação para tentar identificar a provável residência de um criminoso, sendo que: (i) os diálogos dos personagens e as explicações faziam sentido; e, algo mais surpreendente, (ii) as equações de background, apesar de não explicadas, pareciam fazer sentido. Desconfiei. Será que era baseado em um caso real?
E era. Bastou pesquisar um pouco no Google para encontrar a história do policial que virou criminologista, Kim Rossmo, em que o episódio foi baseado. E inclusive, encontrar também um livro para leigos, de leitura agradável, que aborda alguns dos temas de matemática por trás do seriado: The Numbers behind Numb3rs.
A primeira equação que Rossmo criou tinha a seguinte cara:
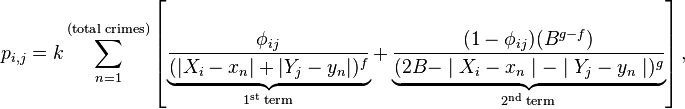
A intuição por trás da equação pode ser resumida desta forma: o criminoso não gosta de cometer crimes perto da própria residência, pois isso tornaria muito fácil sua identificação; assim, dentro de uma certa zona B, a probabilidade de o criminoso residir em um certo local é menor quanto mais próximo este estiver do crime (esse é o segundo termo da equação). Entretanto, a partir de certo ponto, começa a ser custoso ao criminoso ir mais longe para cometer o crime – assim, a partir dali, a situação se inverte, e locais longe do crime passam a ser menos prováveis (esse é o primeiro termo da equação). Em outras palavras, você tenta calcular a probabilidade de um criminoso morar na coordenada (Xi , Xj), com base na distância desta com as demais coordenadas dos crimes (xn, yn), levando em conta o fato de a residência estar ou não em B. Os parâmetros da equação são estimados de modo a otimizar o modelo com base nos dados de casos passados.
Por mais simples que seja, a equação funcionou muito bem e Kim Rossmo prosseguiu com seus estudos em criminologia. Evidentemente que, como em qualquer modelo, há casos em que a equação falha miseravelmente, como em situações em que os criminosos mudam de residência o tempo inteiro – mas isso não é um problema da equação em si, pois o trabalho de quem a utiliza é justamente identificar se a situação é, ou não, adequada para tanto. Acho que este exemplo ilustra muito bem como sacadas simples e bem aplicadas podem ser muito poderosas!
PS: O tema me interessou bastante e o livro de Rossmo, Geographic Profiling, entrou para a (crescente) wishlist da Amazon.
Como já havia dito, para quem gosta de trabalhar com dados, conciliando teoria e prática, o Google deve ser a empresa dos sonhos.
Agora, veja a empresa fornecendo mapas com tendências de gripe e de dengue ao redor do mundo, com detalhes anuais por país e em “tempo real”, tomando por base termos de pesquisa relacionados às doenças e seus sintomas.
Será que a dengue está pior este ano do que no ano passado no Brasil? Aparentemente sim. E os dados do Google podem fornecer uma resposta mais tempestiva do que os dados oficiais:

Mas esses dados fornecem uma boa aproximação dos casos reais? Bom, julgue você mesmo com o gráfico abaixo, comparando o indicador do Google com os dados do Ministério da Saúde:

Impressionante.
Mais sobre o Google aqui (entrevista com Nate Silver) e aqui (Hal Varian aplicando teoria dos jogos na prática).
Jeff Leek do Simply Statistics trouxe uma entrevista bacana com Nick Chamandy, um estatístico do Google.
Destaque para a parte em que ele diz que, na maioria dos casos, o estatístico que trabalha no Google não é somente responsável por fazer as análises, mas também por coletar e tratar os dados brutos.
In the vast majority of cases, the statistician pulls his or her own data — this is an important part of the Google statistician culture. It is not purely a question of self-sufficiency. There is a strong belief that without becoming intimate with the raw data structure, and the many considerations involved in filtering, cleaning, and aggregating the data, the statistician can never truly hope to have a complete understanding of the data. For massive and complex data, there are sometimes as many subtleties in whittling down to the right data set as there are in choosing or implementing the right analysis procedure
Esta é uma reflexão importante, principalmente para os (macro)economistas, que dependem em grande medida de dados de terceiros e podem acabar não tendo intimidade com a produção dos dados e o grau de acurácia das medidas.
PS.: o Google realmente parece ser a empresa dos sonhos para quem quer conciliar teoria e prática. Além da entrevista acima, veja Hal Varian aplicando teoria dos jogos na prática aqui.
Vale à pena conferir a entrevista, abaixo, de Nate Silver com Hal Varian no Google:
Mais sobre Nate Silver neste blog aqui.
Via Simply Statistics.
PS: Em futuros posts, alguns comentários sobre papers da ANPEC/SBE 2012.

