***
Parte do livro Introdução à análise de dados com R. Este trabalho está em andamento, o texto é bastante preliminar e sofrerá muitas alterações.
Quer fazer sugestões? Deixe um comentário abaixo ou, se você sabe utilizar o github, acesse aqui.
Não copie ou reproduza este material sem autorização.
Volte para ver atualizações!
***
Data Frames: seu banco de dados no R
Por que um data.frame?
Até agora temos utilizado apenas dados de uma mesma classe, armazenados ou em um vetor ou em uma matriz. Mas uma base de dados, em geral, é feita de dados de diversas classes diferentes: no exemplo anterior, por exemplo, podemos querer ter uma coluna com os nomes dos funcionários, outra com o sexo dos funcionários, outra com valores… note que essas colunas são de classes diferentes, como textos e números. Como guardar essas informações?
A solução para isso é o data.frame. O data.frame é talvez o formato de dados mais importante do R. No data.frame cada coluna representa uma variável e cada linha uma observação. Essa é a estrutura ideal para quando você tem várias variáveis de classes diferentes em um banco de dados.
Criando um data.frame: data.frame() e as.data.frame()
É possível criar um data.frame diretamente com a função data.frame():
funcionarios <- data.frame(nome = c("João", "Maria", "José"),
sexo = c("M", "F", "M"),
salario = c(1000, 1200, 1300),
stringsAsFactors = FALSE)
funcionarios
## nome sexo salario
## 1 João M 1000
## 2 Maria F 1200
## 3 José M 1300
Também é coverter outros objetos em um data.frame com a função as.data.frame().
Discutiremos a opção stringsAsFactors = FALSE mais a frente.
Vejamos a estrutura do data.frame. Note que cada coluna tem sua própria classe.
str(funcionarios) ## 'data.frame': 3 obs. of 3 variables: ## $ nome : chr "João" "Maria" "José" ## $ sexo : chr "M" "F" "M" ## $ salario: num 1000 1200 1300
Nomes de linhas e colunas
O data.frame sempre terá rownames e colnames.
rownames(funcionarios) ## [1] "1" "2" "3" colnames(funcionarios) ## [1] "nome" "sexo" "salario"
Detalhe: a função names() no data.fram trata de suas colunas, pois os elementos fundamentais do data.frame são seus vetores coluna.
names(funcionarios) ## [1] "nome" "sexo" "salario"
Não parece tão diferente de uma matriz…
O que ocorreria com o data.frame funcionarios se o transformássemos em uma matriz? Vejamos:
as.matrix(funcionarios) ## nome sexo salario ## [1,] "João" "M" "1000" ## [2,] "Maria" "F" "1200" ## [3,] "José" "M" "1300"
Perceba que todas as variáveis viraram character! Uma matriz aceita apenas elementos da mesma classe, e é exatamente por isso precisamos de um data.frame neste caso.
Manipulando data.frames como matrizes
Ok, temos mais um objeto do R, o data.frame … vou ter que reaprender tudo novamente? Não! Você pode manipular data.frames como se fossem matrizes!
Praticamente tudo o que vimos para selecionar e modificar elementos em matrizes funciona no data.frame. Podemos selecionar linhas e colunas do nosso data.frame como se fosse uma matriz:
## tudo menos linha 1
funcionarios[-1, ]
## nome sexo salario
## 2 Maria F 1200
## 3 José M 1300
## seleciona primeira linha e primeira coluna (vetor)
funcionarios[1, 1]
## [1] "João"
## seleciona primeira linha e primeira coluna (data.frame)
funcionarios[1, 1, drop = FALSE]
## nome
## 1 João
## seleciona linha 3, colunas "nome" e "salario"
funcionarios[3 , c("nome", "salario")]
## nome salario
## 3 José 1300
E também alterar seus valores tal como uma matriz.
## aumento de salario para o João funcionarios[1, "salario"] <- 1100 funcionarios ## nome sexo salario ## 1 João M 1100 ## 2 Maria F 1200 ## 3 José M 1300
Extra do data.frame: selecionando e modificando com $ e [[ ]]
Outras formas alternativas de selecionar colunas em um data.frame são o $ e o [[ ]]:
## Seleciona coluna nome funcionarios$nome ## [1] "João" "Maria" "José" funcionarios[["nome"]] ## [1] "João" "Maria" "José" ## Seleciona coluna salario funcionarios$salario ## [1] 1100 1200 1300 funcionarios[["salario"]] ## [1] 1100 1200 1300
Tanto o $ quanto o [[ ]] sempre retornam um vetor como resultado.
Também é possível alterar a coluna combinando $ ou [[ ]] com <-:
## outro aumento para o João funcionarios$salario[1] <- 1150 ## equivalente funcionarios[["salario"]][1] <- 1150 funcionarios ## nome sexo salario ## 1 João M 1150 ## 2 Maria F 1200 ## 3 José M 1300
Extra do data.frame: retornando sempre um data.frame com [ ]
Se você quiser garantir que o resultado da seleção será sempre um data.frame use drop = FALSE ou selecione sem a vírgula:
## Retorna data.frame funcionarios[ ,"salario", drop = FALSE] ## salario ## 1 1150 ## 2 1200 ## 3 1300 ## Retorna data.frame funcionarios["salario"] ## salario ## 1 1150 ## 2 1200 ## 3 1300
Tabela resumo: selecionando uma coluna em um data.frame
Resumindo as formas de seleção de uma coluna de um data.frame.

Criando colunas novas
Há diversas formas de criar uma coluna nova em um data.frame. O principal segredo é o seguinte: faça de conta que a coluna já exista, selecione ela com $, [,] ou [[]] e atribua o valor que deseja.
Para ilustrar, vamos adicionar ao nosso data.frame funcionarios mais três colunas.
Com $:
funcionarios$escolaridade <- c("Ensino Médio", "Graduação", "Mestrado")
Com [ , ]:
funcionarios[, "experiencia"] <- c(10, 12, 15)
Com [[ ]]:
funcionarios[["avaliacao_anual"]] <- c(7, 9, 10)
Uma última forma de adicionar coluna a um data.frame é, tal como uma matriz, utilizar a função cbind() (column bind).
funcionarios <- cbind(funcionarios,
prim_emprego = c("sim", "nao", "nao"),
stringsAsFactors = FALSE)
Vejamos como ficou nosso data.frame com as novas colunas:
funcionarios ## nome sexo salario escolaridade experiencia avaliacao_anual prim_emprego ## 1 João M 1150 Ensino Médio 10 7 sim ## 2 Maria F 1200 Graduação 12 9 nao ## 3 José M 1300 Mestrado 15 10 nao
E agora, temos colunas demais, como remover algumas delas?
Removendo colunas
A forma mais fácil de remover coluna de um data.fram é atribuir o valor NULL a ela:
## deleta coluna prim_emprego funcionarios$prim_emprego <- NULL
Mas a forma mais segura e universal de remover qualquer elemento de um objeto do R é selecionar tudo exceto aquilo que você não deseja. Isto é, selecione todas colunas menos as que você não quer e atribua o resultado de volta ao seu data.frame:
## deleta colunas 4 e 6 funcionarios <- funcionarios[, c(-4, -6)]
Adicionando linhas
Uma forma simples de adicionar linhas é atribuir a nova linha com <-. Mas cuidado! O que irá acontecer com o data.frame com o código abaixo?
## CUIDADO!
funcionarios[4, ] <- c("Ana", "F", 2000, 15)
Note que nosso data.frame inteiro se transformou em texto! Você sabe explicar por que isso aconteceu? relembrar coerção
str(funcionarios) ## 'data.frame': 4 obs. of 4 variables: ## $ nome : chr "João" "Maria" "José" "Ana" ## $ sexo : chr "M" "F" "M" "F" ## $ salario : chr "1150" "1200" "1300" "2000" ## $ experiencia: chr "10" "12" "15" "15"
Antes de prosseguir, transformemos as colunas salario e experiencia em números novamente:
funcionarios$salario <- as.numeric(funcionarios$salario) funcionarios$experiencia <- as.numeric(funcionarios$experiencia)
Se os elementos forem de classe diferente, use a função data.frame para evitar coerção:
funcionarios[4, ] <- data.frame(nome = "Ana", sexo = "F",
salario = 2000, experiencia = 15,
stringsAsFactors = FALSE)
Também é possível adicionar linhas com rbind():
rbind(funcionarios,
data.frame(nome = "Ana", sexo = "F",
salario = 2000, experiencia = 15,
stringsAsFactors = FALSE))
Atenção! Não fique aumentando um data.frame de tamanho adicionando linhas ou colunas. Sempre que possível pré-aloque espaço!
Removendo linhas
Para remover linhas, basta selecionar apenas aquelas linhas que você deseja manter:
## remove linha 4 do data.frame funcionarios <- funcionarios[-4, ]
## remove linhas em que salario <= 1150 funcionarios <- funcionarios[funcionarios$salario > 1150, ]
Filtrando linhas com vetores logicos
Relembrando: se passarmos um vetor lógico na dimensão das linhas, selecionamos apenas aquelas que são TRUE. Assim, por exemplo, se quisermos selecionar aquelas linhas em que a coluna salario é maior do que um determinado valor, basta colocar esta condição como filtro das linhas:
## Apenas linhas com salario > 1000 funcionarios[funcionarios$salario > 1000, ] ## nome sexo salario experiencia ## 2 Maria F 1200 12 ## 3 José M 1300 15 ## Apenas linhas com sexo == "F" funcionarios[funcionarios$sexo == "F", ] ## nome sexo salario experiencia ## 2 Maria F 1200 12
Funções de conveniência: subset()
Uma função de conveniência para selecionar linhas e colunas de um data.frame é a função subset(), que tem a seguinte estrutura:
subset(nome_do_data_frame,
subset = expressao_logica_para_filtrar_linhas,
select = nomes_das_colunas,
drop = simplicar_para_vetor?)
Vejamos alguns exemplos:
## funcionarios[funcionarios$sexo == "F",]
subset(funcionarios, sexo == "F")
## nome sexo salario experiencia
## 2 Maria F 1200 12
## funcionarios[funcionarios$sexo == "M", c("nome", "salario")]
subset(funcionarios, sexo == "M", select = c("nome", "salario"))
## nome salario
## 3 José 1300
Funções de conveniência: with
A função with() permite que façamos operações com as colunas do data.frame sem ter que ficar repetindo o nome do data.frame seguido de $ , [ , ] ou [[]] o tempo inteiro.
Para ilustrar:
## Com o with with(funcionarios, (salario^3 - salario^2)/log(salario)) ## [1] 2.4e+08 3.1e+08 ## Sem o with (funcionarios$salario^3 - funcionarios$salario^2)/log(funcionarios$salario) ## [1] 2.4e+08 3.1e+08
Quatro formas de fazer a mesma coisa (pense em outras formas possíveis):
subset(funcionarios, sexo == "M", select = "salario", drop = TRUE) ## [1] 1300 with(funcionarios, salario[sexo == "M"]) ## [1] 1300 funcionarios$salario[funcionarios$sexo == "M"] ## [1] 1300 funcionarios[funcionarios$sexo == "M", "salario"] ## [1] 1300
Aplicando funções no data.frame: sapply e lapply, funções nas colunas (elementos)
Outras duas funções bastante utilizadas no R são as funções sapply() e lapply().
- As funções
sapplyelapplyaplicam uma função em cada elemento de um objeto. - Como vimos, os elementos de um
data.framesão suas colunas. Deste modo, as funçõessapplyelapplyaplicam uma função nas colunas de um data.frame. - A diferença entre uma e outra é que a primeira tenta simplificar o resultado enquanto que a segunda sempre retorna uma lista.
Testando no nosso data.frame:
sapply(funcionarios[3:4], mean) ## salario experiencia ## 1250 14 lapply(funcionarios[3:4], mean) ## $salario ## [1] 1250 ## ## $experiencia ## [1] 14
Filtrando variáveis antes de aplicar funções: filter()
Como data.frames podem ter variáveis de classe diferentes, muitas vezes é conveniente filtrar apenas aquelas colunas de determinada classe (ou que satisfaçam determinada condição). A função Filter() é uma maneira rápida de fazer isso:
# seleciona apenas colunas numéricas Filter(is.numeric, funcionarios) ## salario experiencia ## 2 1200 12 ## 3 1300 15 # seleciona apenas colunas de texto Filter(is.character, funcionarios) ## nome sexo ## 2 Maria F ## 3 José M
Juntando filter() com sapply() você pode aplicar funções em apenas certas colunas, como por exemplo, calcular a média e máximo apenas nas colunas numéricas do nosso data.frame:
sapply(Filter(is.numeric, funcionarios), mean) ## salario experiencia ## 1250 14 sapply(Filter(is.numeric, funcionarios), max) ## salario experiencia ## 1300 15
Manipulando data.frames
Ainda temos muita coisa para falar de manipulação de data.framese isso merece um espaço especial. Veremos além de outras funções base do R alguns pacotes importantes como dplyr, reshape2 e tidyr em uma seção separada.



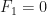 ,
,  ,
,  , $latexF_4 = 2$,
, $latexF_4 = 2$,  ,
, 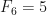 ,
, 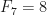 ,
,  ,
,  , e assim por diante.
, e assim por diante.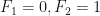 . A partir daí, os números subsequentes são a soma dos dois números anteriores, isto é,
. A partir daí, os números subsequentes são a soma dos dois números anteriores, isto é, 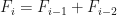 para todo i > 2.
para todo i > 2.



 , com média
, com média  e desvio padrão
e desvio padrão  .
. . Assim, temos que
. Assim, temos que  e, segundo o teorema central do limite, a variável
e, segundo o teorema central do limite, a variável 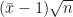 tende a uma normal-padrão (
tende a uma normal-padrão (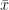 é a média amostral de
é a média amostral de  )
)
 ? Façamos uma simulação para seis valores de tamanho amostral diferentes: 1, 5, 10, 100, 500 e 1000.
? Façamos uma simulação para seis valores de tamanho amostral diferentes: 1, 5, 10, 100, 500 e 1000.