Paper do Pedro Souza e Marcelo Medeiros e apresentação do Marcelo Medeiros na UERJ:
Desenvolvimento
Erro de medida, preços de imóveis e growth regressions.
Em post passado falamos de erro de medida com o cartoon do Calvin. Hoje, enquanto mexia numa base de dados de imóveis de Brasília para passar algumas consultas para um amigo, pensei em voltar no assunto. Dados de oferta de imóveis podem fornecer uma ilustração simples e fácil do problema.
Preços declarados online variam desde 1 centavo até R$ 950 milhões. Tamanhos declarados online vão desde 0.01 metro quadrado até 880 mil metros quadrados. Em outras palavras, o erro de medida pode ser grande. E, neste caso, felizmente, isso é fácil de perceber, pois todos nós temos alguma noção do que são valores razoáveis. Não existe apartamento de 0.01 metro quadrado.
Como isso afeta modelos usuais, tais como uma regressão linear?
Resumidamente: bastam alguns pontos extremos para atrapalhar muito. A regressão linear é extremamente sensível a outliers e erros de observação.
Para ilustrar, façamos a regressão de preços de venda de apartamento contra a metragem do imóvel, nos dados brutos, sem qualquer tratamento. Temos 13.200 observações. A equação resultante foi:
preço = 1.770.902,90 + 2,68 m2
Isto é, segundo a estimativa, cada metro quadrado a mais no imóvel aumentaria seu preço, em média, em R$ 2,68. Não é preciso ser um especialista da área para ver que resultado é patentemente absurdo.
E o que acontece com a estimativa se limparmos a base de dados? Tirando apenas 200 observações das 13.200 (1,5% dos dados), obtemos a seguinte equação:
preço = -45.500,44 + 9.989,81 * m2
Agora, cada metro quadrado a mais está associado a um aumento de R$9.989,81 nos preços, em média – de acordo com o senso comum (infelizmente) para a cidade de Brasília. Ou seja, com a regressão sem tratamento dos dados, você subestimaria o efeito em nada menos do que 3 mil e 700 vezes.
***
O caso anterior é fácil de identificar, mas no dia a dia nem sempre isso ocorre. E é comum tomar dados oficiais por seu valor de face.
Quer um exemplo?
A Penn World Tables, na versão 6.1, publicou uma queda de 36% no PIB da Tanzânia em 1988. Isso levou Durlauf e outros autores a colocarem em seu texto, Growth Econometrics, o “caso” da Tanzânia como um dos top 10 de queda do produto (vide tabela 8). Entretanto, na versão 7.1 da Penn Tables, os dados mostram um crescimento de 8% para Tanzânia, para o mesmo ano! Se um dado como esse já pode ser muito enganoso apenas como estatística descritiva, imagine o efeito em growth regressions com regressões lineares e variáveis instrumentais.
PS1: o legal é que o próprio texto do Durlauf tem uma seção bacana sobre erro de medida!
PS2: Sobre dados de PIB da África, livro recente do Jerven, Poor Numbers, discute muitos desses problemas.
Votos e Bolsa Família: segundo turno!
Tem gente que reclama das urnas eletrônicas, com razão. Mas de uma coisa os pesquisadores não podem reclamar: nessas eleições, os dados ficam disponíveis quase que instantaneamente. E, com os dados do segundo turno em mãos, voltemos àquela relação que sempre gera polêmica – percentual de votos versus percentual de pessoas beneficiadas pelo bolsa família (BF) por município (veja o post do primeiro turno aqui).
Por agora, e pela hora, vamos tentar responder apenas duas perguntas simples: (i) a relação entre votos e BF se manteve? (ii) há correlação entre o BF e a variação dos votos dos candidatos entre o primeiro e segundo turnos?
Quanto à primeira pergunta, a resposta é positiva, tanto no geral:
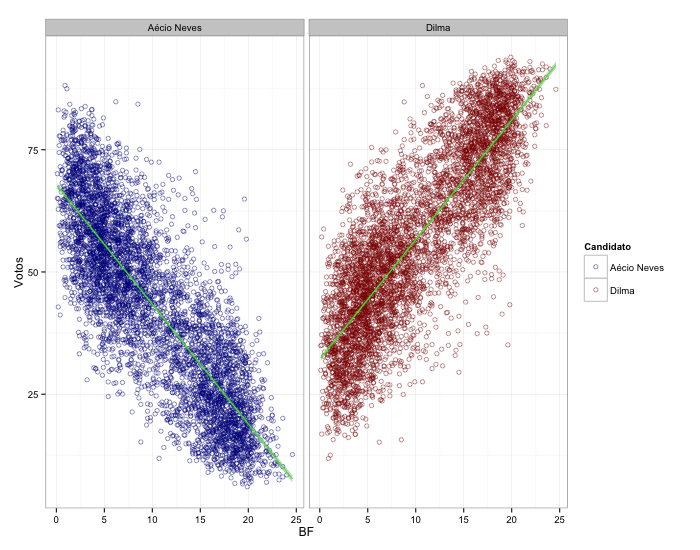
Quanto por UF:

Já com relação à segunda pergunta, o BF não parece estar correlacionado com as mudanças de votos por municípios:

PS: vale lembrar que este blog frisa, constantemente, que correlação não implica em causalidade. Sobre este ponto, leia estes outros posts aqui.
Votos e Bolsa Família: correlação se mantém quando controlada por estado?
Fábio Vasconcellos e Daniel Lima fizeram alguns gráficos interessantes sobre a correlação de algumas variáveis socioeconômicas e o percentual de votos recebidos por cada candidato. Um deles – e que sempre suscita polêmica – é a relação entre percentual de votos versus percentual de pessoas beneficiadas pelo bolsa família por município. Segue uma reprodução do gráfico abaixo, feita no R com o ggplot2.

Entretanto, esta relação me gerou a seguinte dúvida: será que a correlação se mantém dentro de cada UF? Por exemplo, Aécio ganhou em SP, SC e MT. Nesses estados, também houve correlação negativa do BF para o candidato tucano?
Aparentemente, sim, conforme pode ser visto no gráfico abaixo. E a separação por estado também indica que a correlação do BF com votos para Marina foi negativa em grande parte das UF’s. Um estado que chama a atenção é Minas Gerais, em que estas relações se parecem bem acentuadas.

PS: vale lembrar que este blog frisa, constantemente, que correlação não implica em causalidade. Sobre este ponto, leia estes outros posts aqui.
PS2: os dados em formato rds (do R) podem ser baixados aqui.
Investimento Estrangeiro Direto no Brasil por Estado (Indústria)
Os dados do Censo de Capitais Estrangeiros no País, em 2010, trouxeram a distribuição do Investimento Estrangeiro Direto (IED) na indústria por Unidade da Federação (UF).
Somente da Indústria? E como foi feita a distribuição? Aqui voltamos ao que já dissemos sobre erro de medida (ver aqui, aqui, aqui e aqui, por exemplo). Distribuir o estoque investimento estrangeiro por UF é algo complicado, sujeito a erros diversos, tanto ao se definir a metodologia, quanto ao se mensurar o valor. No censo de 1995, por exemplo, os dados foram distribuídos por estado “[…] tomando por base o endereço da sede da empresa”. Será que essa é uma boa medida? Depende.
Percebe-se que uma indústria que concentre o grosso da sua estrutura produtiva no Pará, mas que tenha sede em São Paulo, será considerada um investimento nesta última UF. Se a intenção é medir onde se encontra o centro administrativo, esta medida poderá ser boa. Todavia, se intenção é medir onde se encontram as unidades produtivas, esta medida terá, talvez, distorções significativas. Qual a melhor forma, então, de se distribuírem os investimentos por estado? Pela localização da sede? Pela localização do ativo imobilizado? Pela distribuição dos funcionários? Particularmente, acho que não existe uma métrica única que se sobressaia às demais – a melhor opção depende do uso que você irá fazer da estatística.
Voltando ao Censo, a pesquisa passou a considerar a distribuição do ativo imobilizado como critério para alocação do IED – e apenas para a indústria . Os declarantes distribuíram percentualmente o seu imobilizado pelos diferentes estados e isso foi utilizado para ponderar o investimento direto pelas UF’s.
Segue abaixo mapa do Brasil com a distribuição do IED da indústria por Unidade Federativa:

Para aprender a fazer o mapa, veja aqui.
Economia, Democratas e Republicanos
Ontem, dois blogs (Marginal Revolution e Econbrowser) comentaram um interessante artigo de Alan Blinder e Mark Watson. A economia americana, sob quase qualquer ótica que você escolher, se comportou melhor durante os governos democratas do que durante os governos republicanos. Vejam alguns indicadores:
PIB: 4,35% x 2,54%;
Recessões: 8 para os democratas x 41 para os republicanos;
Taxa de desemprego: 5,6% x 6,0% (e variação na taxa de desemprego, -0.8 p.p x +1.1 p.p);
Taxa de inflação: 2,97% x 3,44% (mas os democratas perdem na variação, +1.05 p.p x -0.83 p.p)
Mas o que explicaria essas diferenças? Os democratas governam melhor do que os republicanos? Não necessariamente. Os autores acreditam que os democratas, muito provavelmente, foram simplesmente sortudos. Segundo Blinder e Watson, os fatores que melhor explicam os diferenciais são: os choques de petróleo, os choques de produtividade e as expectativas dos consumidores.
Em suas palavras:
Specifically, Democratic presidents have experienced, on average, better oil shocks than Republicans, a better legacy of (utilization-adjusted) productivity shocks, and more optimistic consumer expectations (as measured by the Michigan ICE).
Minha opinião: o artigo é provocador, mas a evidência apresentada muito ambígua. Mesmo se aceitarmos que essas são as variáveis fundamentais, quer queira, quer não, tanto o preço do petróleo, quanto as expectativas dos consumidores são variáveis bastante afetadas por decisões políticas; e a “produtividade dos fatores” é um resíduo, indefinido do ponto de vista econômico (os autores admitem essas três qualificações, mas timidamente).
Assim, me parece que, neste caso, não haveria como fugir de uma boa (e extensa) revisão histórica de como e por que se deram os choques (de petróleo e de produtividade), bem como uma boa fundamentação teórica (e, quem sabe, contrafactual) de como esses choques ocorreriam a despeito das decisões políticas de ambos os partidos.
Bicicletas aumentam em 30% a permanência de meninas na escola, na Índia.
Foi o que encontraram os pesquisadores Karthik Muralidharan e Nishith Prakash. A bicicleta afeta principalmente as meninas que vivem entre 5 a 10 Km da escola. Isto mostra: (i) como pequenas distâncias, isto é, pequenos custos, podem ter efeito substancial em algo tão importante no longo prazo como a educação; mas, também, que (ii) esses obstáculos podem ser, muitas vezes, resolvidos com medidas bastante simples.
Veja, abaixo, o vídeo dos pesquisadores:
Via Mankiw.
Instituições e Piratas
Compartilho o interessante debate que está ocorrendo na blogosfera entre A&R e Peter Leeson. Aparentemente, os piratas que navegavam pelo Caribe no século 18 tinham instituições democráticas, votavam em seus lideres – cada pirata com direito a um voto – e ainda tinham modos de destitui-los do poder, caso seu desempenho não fosse satisfatório. Como essas instituições surgiram? Lesson argumenta que elas surgiram pois eram eficientes. A&R discordam. Você pode conferir o debate aqui, aqui e aqui.
Estatística na União Soviética
É bastante comum ver argumentos que são contra a liberdade econômica e, ao mesmo tempo, a favor da liberdade acadêmica, artística, de imprensa e de expressão em geral. Confunde-se – propositadamente ou não – democratização da mídia com financiamento público de propaganda ideológica, ou liberdade de imprensa com imprensa “neutra” ou “politicamente correta” (no sentido fluído que essas palavras ganham em cada contexto em que seu interlocutor usa).
Entretanto, ao menos no limite, há uma contradição inerente a este tipo de raciocínio; pois, uma vez que caiba a um órgão central definir quem exerce o quê em cada campo da esfera econômica, isto também abrange a atividade de professores, pesquisadores, jornalistas e artistas.
Se o único jornal a ser permitido no país é um jornal estatal, qual o incentivo para que notícias desfavoráveis ao governo circulem? Se as únicas universidades permitidas no país são estatais, qual o incentivo para que linhas de pesquisa que não agradem ao governo prosperem? E assim por diante. Sim, é possível contra-argumentar este argumento, e depois contra-argumentar o seu contra-argumento, e este é um debate acalorado e interessante; mas não será desenvolvido neste post. A ideia era apenas fazer uma introdução para comentar sobre a situação da ciência estatística na União Soviética na época de Stalin.
A Rússia produziu grandes estatísticos matemáticos, como Kolmogorov e Slutsky (sim, ele também é o mesmo que você estudou em microeconomia). Todavia, conforme se lê em The Lady Tasting Tea: How Statistics Revolutionized Science in the Twentieth Century, o regime comunista considerava que todas as ciências sociais eram, na verdade, ciências de classe, e deveriam estar subordinadas ao planejamento central do partido. Para eles, a estatística era uma ciência social. E o conceito de “aleatório” ou “erro-padrão” era algo absurdo em uma economia planejada. Nas palavras de Salsburg (p.147-148):
A palavra russa para variável aleatória se traduz como “magnitude acidental”. Para planejadores centrais e teóricos, isso era um insulto […] nada poderia ocorrer por acaso. Magnitudes acidentais poderiam descrever coisas que ocorrem em economias capitalistas – não na Rússia. As aplicações da estatística matemática foram rapidamente reprimidas.
Como resultado os periódicos de estatística foram se extinguindo e os estatísticos matemáticos tiveram que, ou pesquisar assuntos estatísticos disfarçados com outros nomes, ou mudar de área. E enquanto os Estados Unidos utilizavam os desenvolvimentos dos teóricos russos na prática – como no controle de qualidade industrial – a Rússia teve que esperar algumas décadas, até o colapso da União Soviética, para ver o fruto de seus próprios cientistas aplicado à indústria.
Comunidades tribais são mais violentas? O quão próxima é a distribuição normal? O papel do BNDES.
Alguns links aleatórios.
1) Não existe má publicidade 2 (o primeiro foi com relação ao livro do Sandel). Recém publicado livro do Jared Diamond (The World Until Yesterday: What Can We Learn from Traditional Societies?) parece ter provocado a ira (aqui e aqui) de grupos defensores das comunidades tribais. Resultado: comprei a versão para Kindle.
(Via Marginal Revolution)
2) Seguem alguns posts do Larry Wasserman que queria compartilhar há algum tempo, mas havia procrastinado:
– Review do livro de Nassim Taleb, Antifragile: Things That Gain from Disorder, apenas lido pela metade (because only sissy fragilistas finish a book before reviewing it);
– Sobre teoremas de upper-bound para erros de aproximação pela curva normal (vale conferir uma sugestão que surgiu nos comentários do post, um texto histórico, bacana, sobre robustez do Stigler).
3) Sobre o papel do BNDES. Artigo de Maurício Canêdo Pinheiro, no Estadão, bota em xeque a efetividade da instituição. Como suporte, menciona o working paper do Lazzarini (What Do Development Banks Do? Evidence from Brazil, 2002-2009). Lembro-me de terem comentado bastante sobre esse artigo na última Anpec, e tenho de confessar que as conclusões do paper são bastante alinhadas com minhas crenças e intuições a priori. A despeito disso, com base em uma passada de olho, fiquei na dúvida se os dados apresentados corroboram conclusões fortes. Para não falar mais sem ler com o devido cuidado, isso fica para outro dia.
