Para quem começou a ter interesse, vale a pena acompanhar o FiveThirtyEight, o Princeton Election Consortium e o The Upshot.
Previsões
Previsões para o Impeachment 4 – mercados de previsão
Para finalizar, além dos modelos apresentados nos posts anteriores (aqui e aqui), temos dois mercados de previsão em que o evento da queda de Dilma Rousseff é negociado.
O Predict It:

E o ipredict:

Previsões para o impeachment 2
Neale diz que as chances de passar são de 96% (dados de hoje):

No final do ano passado, as estimativas estavam em 0%.
Já Guilherme, Marcelo e Eduardo dizem que as chances são de praticamente 100% (dados de hoje):

E as simulações do Regis mostram resultado semelhante (com ausência de 0%, dados de hoje) . Com 10% de ausência, por outro lado, o resultado se inverte:
 Há outras previsões por aí?
Há outras previsões por aí?
PS: claro, há também as previsões do Vidente Carlinhos (feitas ano passado). Além do impeachment, aparentemente 2016 será um ano difícil para Ivete Sangalo. E Álvaro Dias será presidente, em 2018, pela Rede. Mas Carlinhos não tem lá um bom histórico.
Quando confiar nas suas previsões?
Quando você deve confiar em suas previsões? Como um amigo meu já disse, a resposta para essa questão é fácil: nunca (ou quase nunca).
Mas, brincadeiras à parte, para este post fazer sentido, vou reformular a pergunta: quando você deve desconfiar ainda mais das previsões do seu modelo?
Há várias situações em que isso ocorre, ilustremos aqui uma delas.
***
Imagine que você tenha as seguintes observações de x e y.
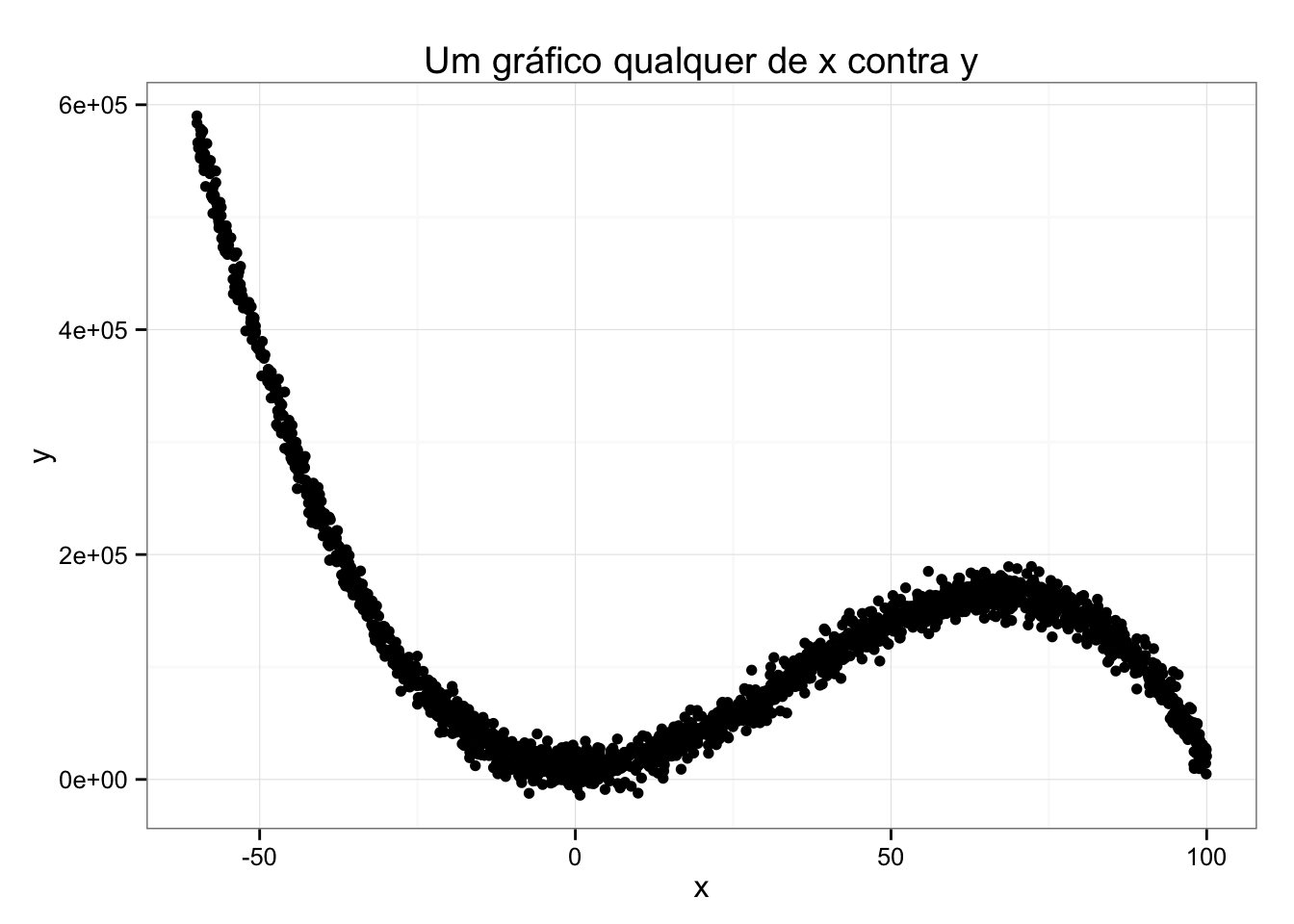
Para modelar os dados acima, vamos usar uma técnica de machine learning chamada Suport Vector Machine com um núcleo radial. Se você nunca ouviu falar disso, você pode pensar na técnica, basicamente, como uma forma genérica de aproximar funções.
Será que nosso modelo vai fazer um bom trabalho?
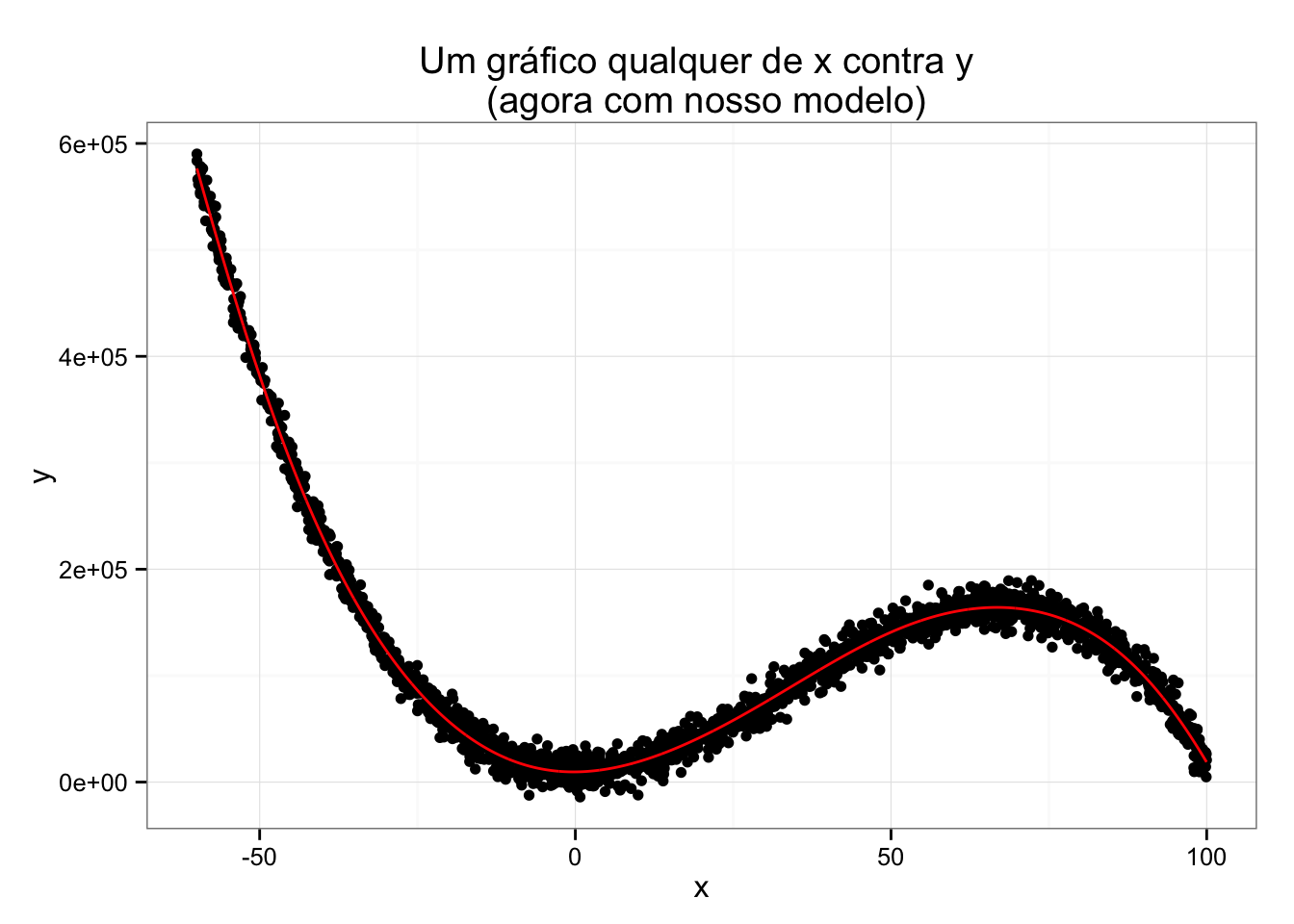
Pelo gráfico, é fácil ver que nossa aproximação ficou bem ajustada! Para ser mais exato, temos um R2 de 0.992 estimado por cross validation (que é uma estimativa do ajuste fora da amostra – e é isso o que importa, você não quer saber o quão bem você fez overfitting dos dados!).
Agora suponha que tenhamos algumas observações novas, isto é, observações nunca vistas antes. Só que essas observações novas serão de dois “tipos”, que aqui criativamente chamaremos de tipo 1 e tipo 2. Enquanto a primeira está dentro de um intervalo de x que observamos ao “treinar” nosso modelo, a segunda está em intervalos muito diferentes.
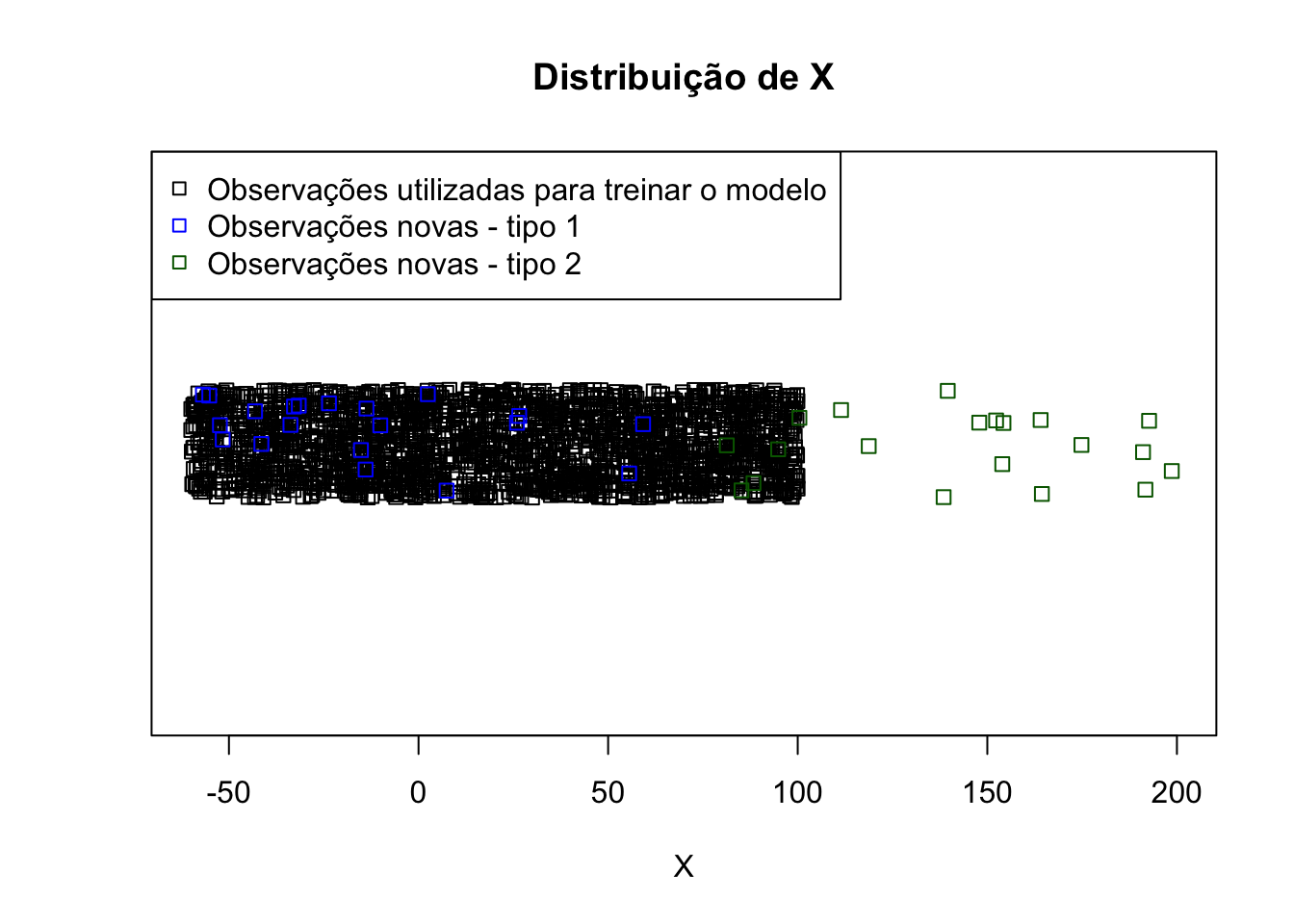
Qual tipo de observação você acha que teremos mais dificuldades de prever, a de tipo 1 ou tipo 2? Você já deve ter percebido onde queremos chegar.
Vejamos, portanto, como nosso modelo se sai agora:
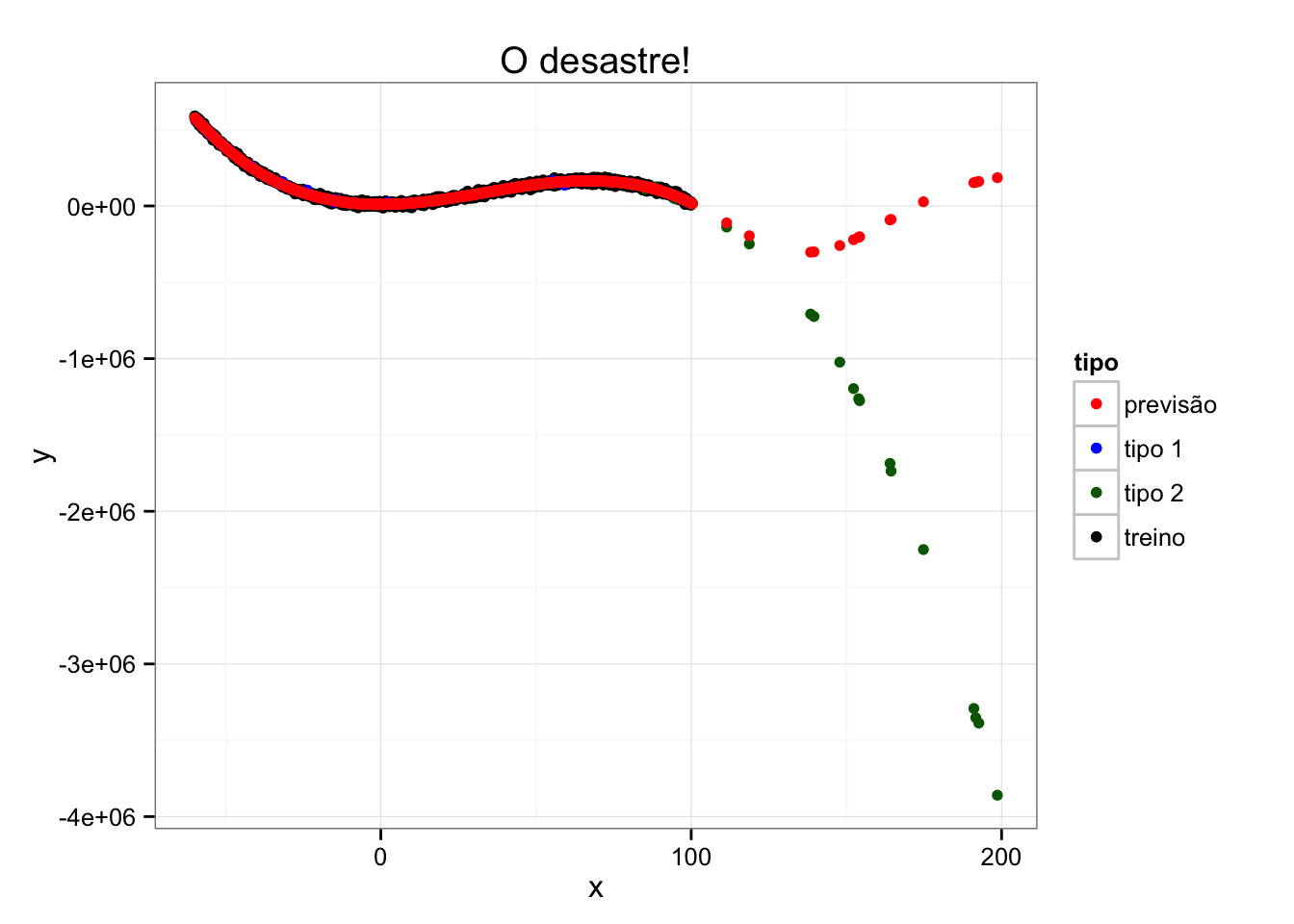
Note que nas observações “similares” (tipo 1) o modelo foi excelente, mas nas observações “diferentes” (tipo 2) nós erramos – e erramos muito. Este é um problema de extrapolação.
Neste caso, unidimensional, foi fácil perceber que uma parte dos dados que gostaríamos de prever era bastante diferente dos dados que usamos para modelar. Mas, na vida real, essa distinção pode se tornar bastante difícil. Uma complicação simples é termos mais variáveis. Imagine um caso com mais de 20 variáveis explicativas – note que já não seria trivial determinar se novas observações são similares ou não às observadas!
Quer aprofundar mais um pouco no assunto? Há uma discussão legal no livro do Max Kuhn, que já mencionamos aqui no blog.
Pesquisas eleitorais: Veritá ou DataFolha? Sobre metodologia e margens de erro.
As eleições têm trazido ao público um debate importante sobre estatística e incerteza. Em um dia, o Datafolha indica 52% dos votos para a Dilma. No dia seguinte, o Instituto Veritá contabiliza 53% do votos para Aécio. Como conciliar isso com as pequenas margens de erro sugeridas pelas pesquisas?
O problema é que, em geral, as margens de erro das pesquisas são divulgadas como se tivessem sido feitas por amostragem aleatória simples. Mas, na verdade, as pesquisas têm um processo de amostragem mais complexo, sujeito a outros tipos de erros. Um texto legal sobre o assunto é este, do Rogério.
E para complicar ainda mais, os institutos usam métodos diferentes. Por exemplo, olhando as últimas duas pesquisas presidenciais, aparentemente a pesquisa do Instituto Veritá foi uma Amostragem Probabilística por Cotas com entrevistas por domicílios (e também com o uso de ponto de fluxo onde a entrevista domiciliar não fosse possível – vide aqui); e, a do DataFolha, uma Amostragem por Cotas com entrevistas por ponto de fluxo (vide aqui).
Esses métodos, apesar de terem nomes semelhantes, segundo Neale El-Dash não são tão semelhantes assim:
Outro problema é que o documento divulgado no TSE é muitas vezes pouco claro com relação a certos detalhes da metodologia. Se você se interessa pelo tema, deixo também os links para outros dois posts interessantes do Neale: este e este.
Previsões do primeiro turno: Google Trends (e Vidente Carlinhos)?
Os resultados do primeiro turno saíram e, mesmo com as evidências de ontem que apontavam para uma alta de Aécio Neves, surpreenderam: o candidato mineiro amealhou quase 34% dos votos, quando há pouco se estimava que conseguiria 15%! Os modelos de previsão, apesar de favorecerem Aécio quando atualizados com as pesquisas de sábado, não conseguiram capturar a magnitude da mudança, apontando para estimativas entre 21 a 26%.
Faz parte. Prever em meio a tanta incerteza (e pesquisas de metodologia duvidosa) é uma tarefa ingrata.
Por outro lado, o Google Trends (depois de corrigido com a dica do Gabriel Ferreira – valeu!) trouxe um indício bastante forte da subida de Aécio. E com uma coincidência aritmética, digamos, “mística”, quase ao estilo Vidente Carlinhos. Uma regra de 3 com os dados do trends de sexta, considerando 40% para Dilma como base, trazia valores estimados de 35% para Aécio e 21% para Marina. Quase cravado.
Evidentemente, isso não passou de sorte, pois utilizando os dados disponíveis agora você estimaria que Aécio ultrapassou Dilma. Mas tampouco é somente algo curioso. Isto mostra o potencial do Google Trends no auxílio do “nowcasting” das eleições, complementando os resultados das pesquisas para entender as tendências do eleitorado. O grande desafio aqui é separar o sinal do ruído, tanto das pesquisas, quanto das redes sociais e dos mecanismos de buscas, além de saber como juntar essas evidências de forma complementar e coerente.
No caso do Google, certamente o teor das buscas importa, lembre do caso do Pastor Everaldo. E as buscas relacionadas que mais estavam crescendo eram aquelas que diziam respeito aos números dos candidatos. Ou seja, tinham relação direta com intenção de voto.
 Depois dessa, é capaz de muita gente ficar de olho no Trends durante o segundo turno. Só espero que o Google tenha bons algoritmos para impedir que os bots dos partidos manipulem o indicador. Ou ainda, será que a relação continuará valendo, uma vez que as pessoas já tenham tido tempo de decorar os números de seus candidatos?
Depois dessa, é capaz de muita gente ficar de olho no Trends durante o segundo turno. Só espero que o Google tenha bons algoritmos para impedir que os bots dos partidos manipulem o indicador. Ou ainda, será que a relação continuará valendo, uma vez que as pessoas já tenham tido tempo de decorar os números de seus candidatos?
Dilma, Marina e Aécio no Google Trends, um dia antes das eleições
Mais uma antes das eleições amanhã: os Google Trends de Dilma, Marina e Aécio. Já tínhamos visto essa busca antes, como ela está agora?
Diferentemente das pesquisas eleitorais, as pesquisas do Google não mostram uma ultrapassagem no interesse de busca pelo termo “Aécio Neves”.
UPDATE: O Google Trends tem uma sutileza que não havia percebido. A pesquisa considerando o tópico (repare no detalhe abaixo dos termos de busca: “Former Governor”, “President of Brazil” etc) mostra sim a ultrapassagem de Aécio em relação à Marina. A ressalva de sempre é válida: estes são dados de busca na internet; por favor, não confunda, não são dados de intenção de voto. A despeito disso, não deixa de ser interessante acompanhar.
 Na pesquisa anterior, abaixo, Marina e Aécio foram buscados como termos genéricos e Dilma não.
Na pesquisa anterior, abaixo, Marina e Aécio foram buscados como termos genéricos e Dilma não.
 Curiosidades: a pesquisa com termos genéricos mostra a busca Marina disparada na frente, seguida de Aécio e depois Dilma.
Curiosidades: a pesquisa com termos genéricos mostra a busca Marina disparada na frente, seguida de Aécio e depois Dilma.

E a pesquisa com os nomes dos presidenciáveis sem os sobrenomes e como termos genéricos também mostra a busca “Marina” na frente. Todavia, sem saber direito o que essas duas pesquisas estão considerando, e como os termos sem sobrenome, como “Marina”, podem refletir outras buscas, não saberia dizer se essas medidas são as mais apropriadas. Ficam aqui como food for thought.

E aí, será que o Google Trends é uma boa proxy para intenção de voto? E quais os termos adequados a utilizar?
PS: Veja previsões para o resultado amanhã aqui e aqui (update).
UPDATE: Previsões para eleições: o que estão dizendo para amanhã? Atualização com as pesquisas de hoje.
A vantagem de um modelo bayesiano é a a forma coerente de atualizar as probabilidades frente às novas informações. E o Polling Data atualizou suas previsões, agora à tarde, considerando as novas pesquisas eleitorais: são 79% de chances para Aécio ir ao segundo turno.

As estimativas pontuais ficaram em 40% para Dilma, 24% para Aécio e 21% para Marina. Leia um pouco mais sobre o assunto no blog do Neale.
Previsões para eleições: o que estão dizendo para amanhã?
O que o pessoal que se aventurou nesta empreitada está chutando dizendo um dia antes da contenda eleitoral?
Acredito que há dois eventos que devem ser vistos com mais atenção: (i) uma possível eleição da Dilma no primeiro turno; e (ii) a possibilidade de Aécio ultrapassar Marina e ir para o segundo turno.
Polling Data
UPDATE: O Polling Data atualizou as probabilidades com as novas pesquisas eleitorais. Agora são 79% de chances para Aécio ir ao segundo turno. Leia mais no blog do Neale.

Os resultados a seguir eram da previsão pela manhã, antes das novas pesquisas.
Neale El-Dash, do Polling Data, está dando apenas 2% de chances de não ter segundo turno. Já para o Aécio passar Marina, a probabilidade está em cerca de 22% – baixa, mas plausível. Grosso modo, isto é uma em cada 4 ou 5 vezes.

A previsão mais recente dos votos está em 39% para Dilma, 23% para Marina e 21% para Aécio.
Daniel Marcelino
As previsões mais recentes do Daniel são: 39% para Dilma, 23% para Marina e 18% para Aécio. Considerando somente os votos válidos, esses números passariam para: Dilma 46%; Marina 28%; e, Aecio 22%.
Com relação a Aécio ultrapassar Marina, as chances parecem um pouco menores do que no modelo de Neale. No olhomêtro, com o gráfico abaixo, está em algo em torno de 5%. E o segundo turno também parece bastante provável.

Vidente Carlinhos
Para não ficar só com os modelos Bayesianos, vamos colocar algo místico no páreo: o vidente Carlinhos, que ficou famoso por “prever” a derrota do Brasil e a “saída” de Neymar durante a copa. Pense no Carlinhos como um grupo de controle. Há vários outros “videntes” por aí que poderiam ser incluídos, mas esse é o mais divertido. O interessante da previsão do Carlinhos é que ela é ousada (algo natural para quem não tem nada a perder, pois se acertar leva a fama e se errar pode dar uma desculpa): Aécio não somente ultrapassaria Marina, como ganharia a eleição no segundo turno. Note que essa previsão tem baixa probabilidade nos dois modelos bayesianos. Entretanto, o problema principal da previsão do vidente é que ela não é probabilística. Deste modo, acertando ou errando, não conseguimos mensurar direito o quanto ele acertou ou errou – algo fundamental para comparar modelos de previsão – e que podemos fazer com as outras elencadas acima.
***
Conhece mais alguma previsão? Informe aqui para que possamos acompanhar e ver quem se saiu melhor.
Dilma, Marina e Aécio (e Pastor Everaldo?) no Google Trends!
Olhem que curioso o Google Trends das buscas pelos presidenciáveis, Dilma, Marina e Aécio, nos últimos 30 dias:

Por algum acaso, as tendências parecem refletir um pouco os resultados das pesquisas eleitorais. Dilma, em azul pontilhado, tinha o maior número de buscas. Até que, de repente, Marina – em vermelho – a ultrapassou. Uma nota: o pico de Dilma Rousseff é fruto da entrevista no Jornal Nacional e, aparentemente, parece ter sido mais mérito de William Bonner do que da Presidenta, segundo os dados das pesquisas relacionadas.

Mais recentemente, parece que as buscas estão se aproximando. Vendo apenas os últimos sete dias:
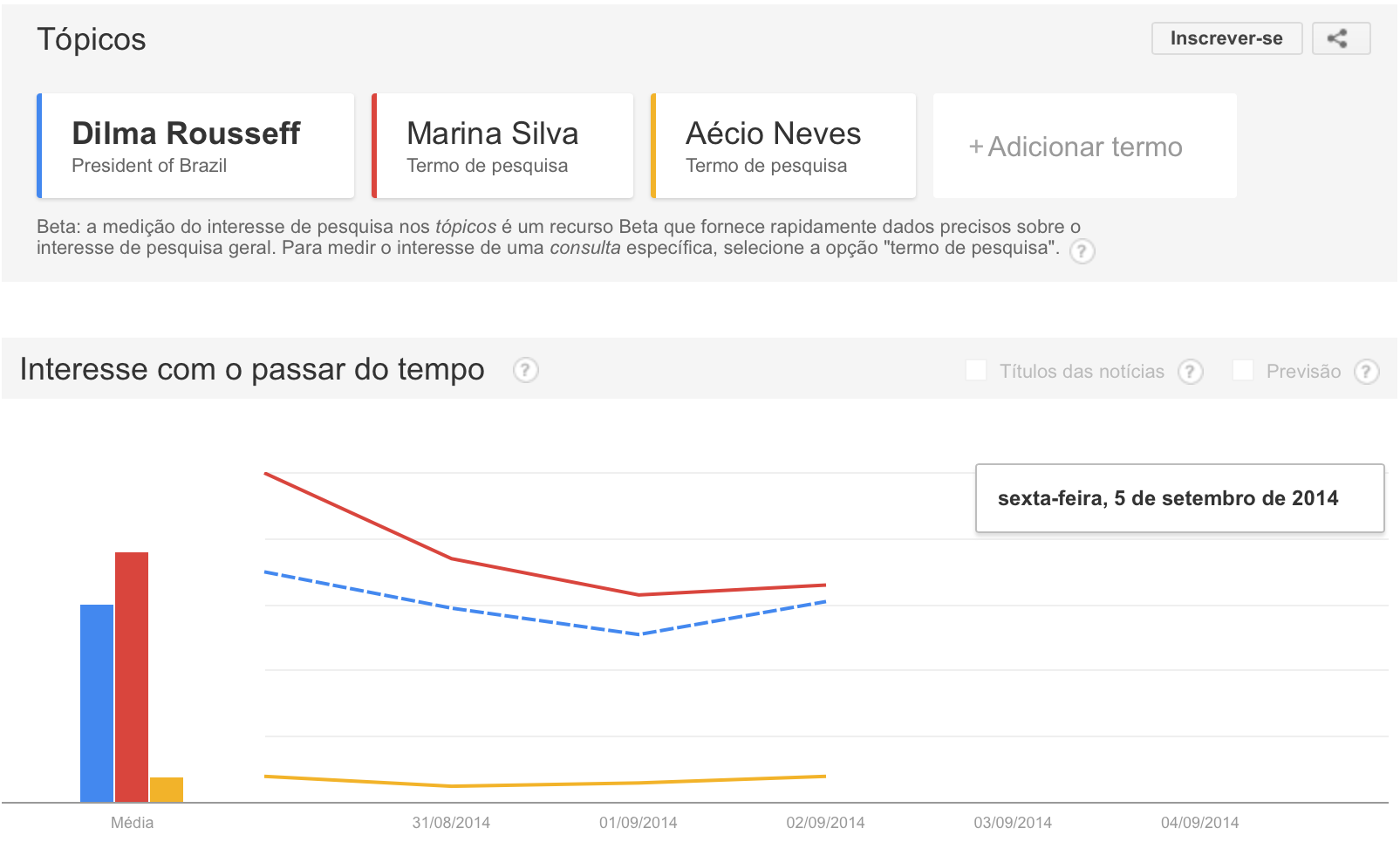
Vale ressaltar, logicamente, que os dados do Google Trends são dados de busca na internet; por favor, não são dados de intenção de voto. Para ilustrar, vejamos o pastor Everaldo, em verde:

Algo estranho para quem tem menos de 2% das intenções de votos. Entretanto, vejamos as buscas relacionadas:

Se você não entendeu, provavelmente foi um dos poucos que não viu este vídeo. Ou seja, não basta ver o número de buscas, mas também seu teor. A despeito dessas ressalvas, incluir o Google Trends como mais um dos inputs para previsão eleitoral talvez não seja uma má idéia.
PS: você pode brincar com essas pesquisa aqui!
