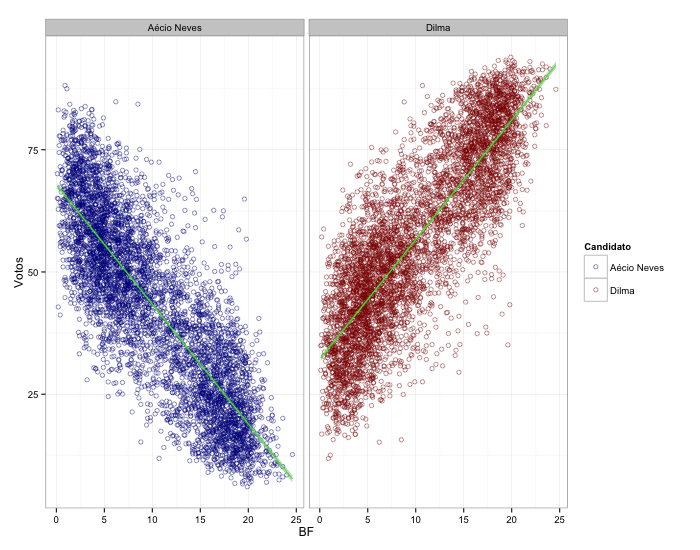
A pergunta que queria fazer era: quantos votos da Marina foram para Aécio ou para Dilma? Para responder isso, precisaria de alguns dados que não tenho e não vou ter tempo de buscar (e que talvez nem estejam disponíveis).
Mas, na verdade, vou fazer outras perguntas simples que talvez sejam tão interessantes quanto e, provavelmente, sejam uma aproximação razoável: (i) Os votos válidos para Marina explicam de maneira diferente a variação dos votos válidos para Aécio ou para Dilma? (ii) Isso variou entre os estados da federação?
Resumindo, as respostas são:
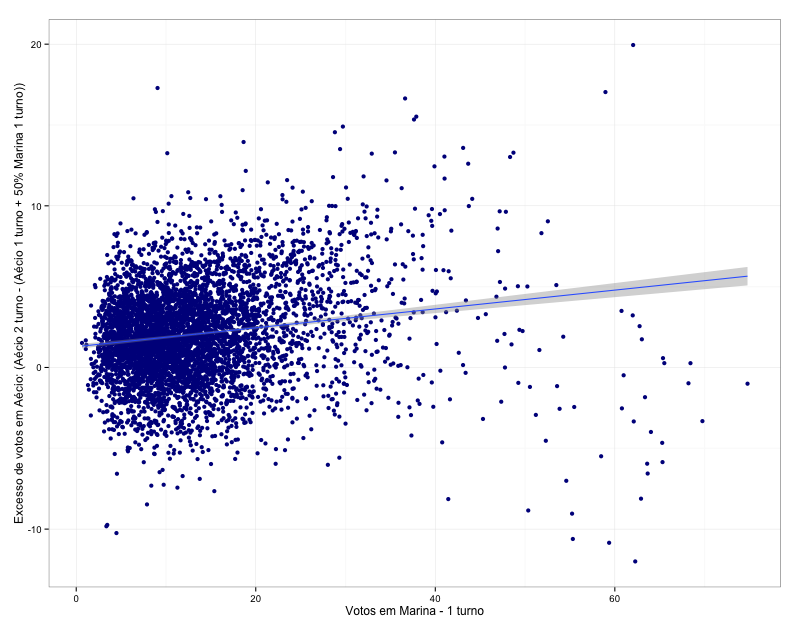
(i) sim, cada 1 ponto percentual de voto para Marina no primeiro turno previu, na média, 0.56 pp a mais para Aécio e 0.44 pp a mais para Dilma; e,
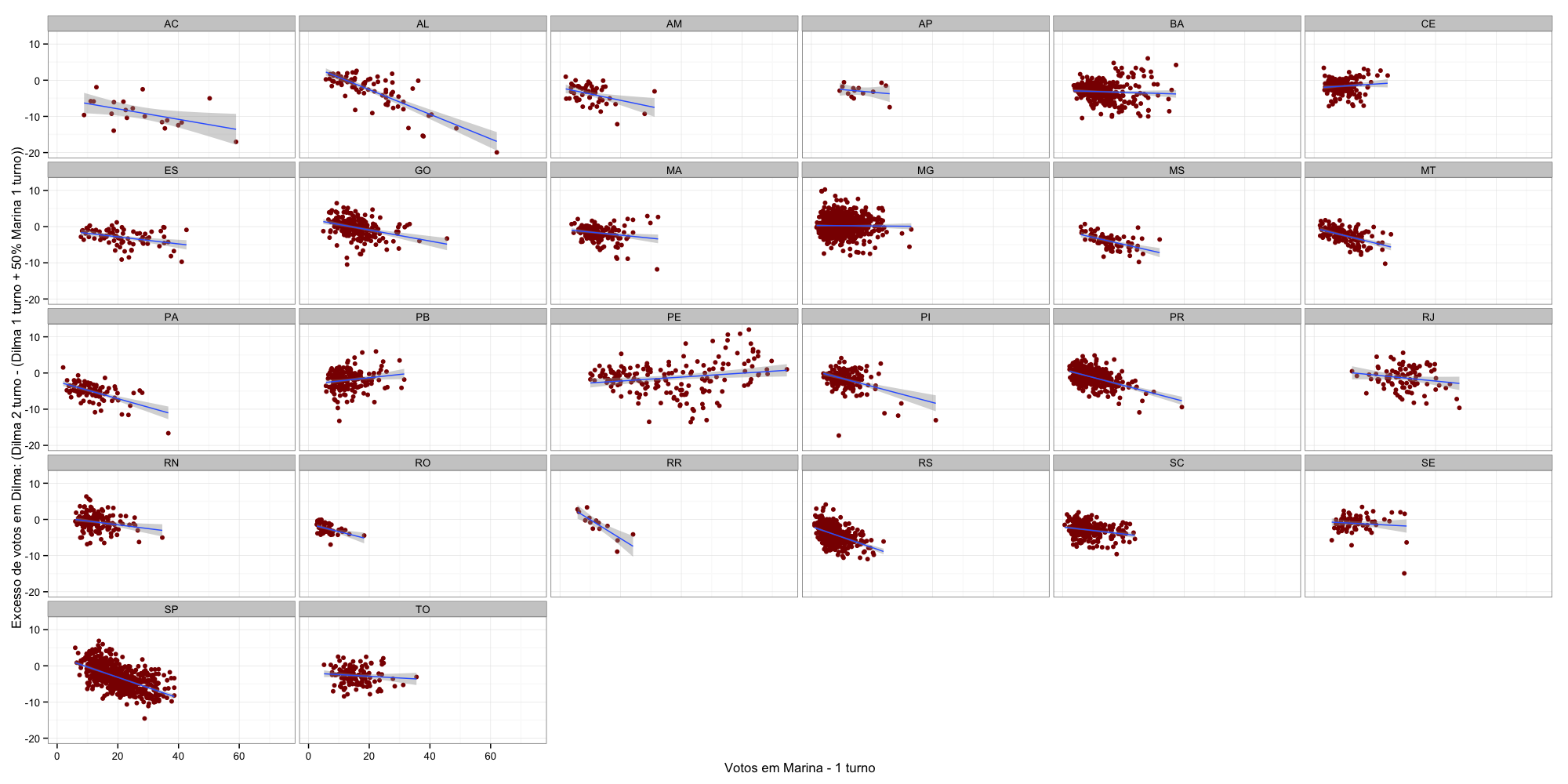
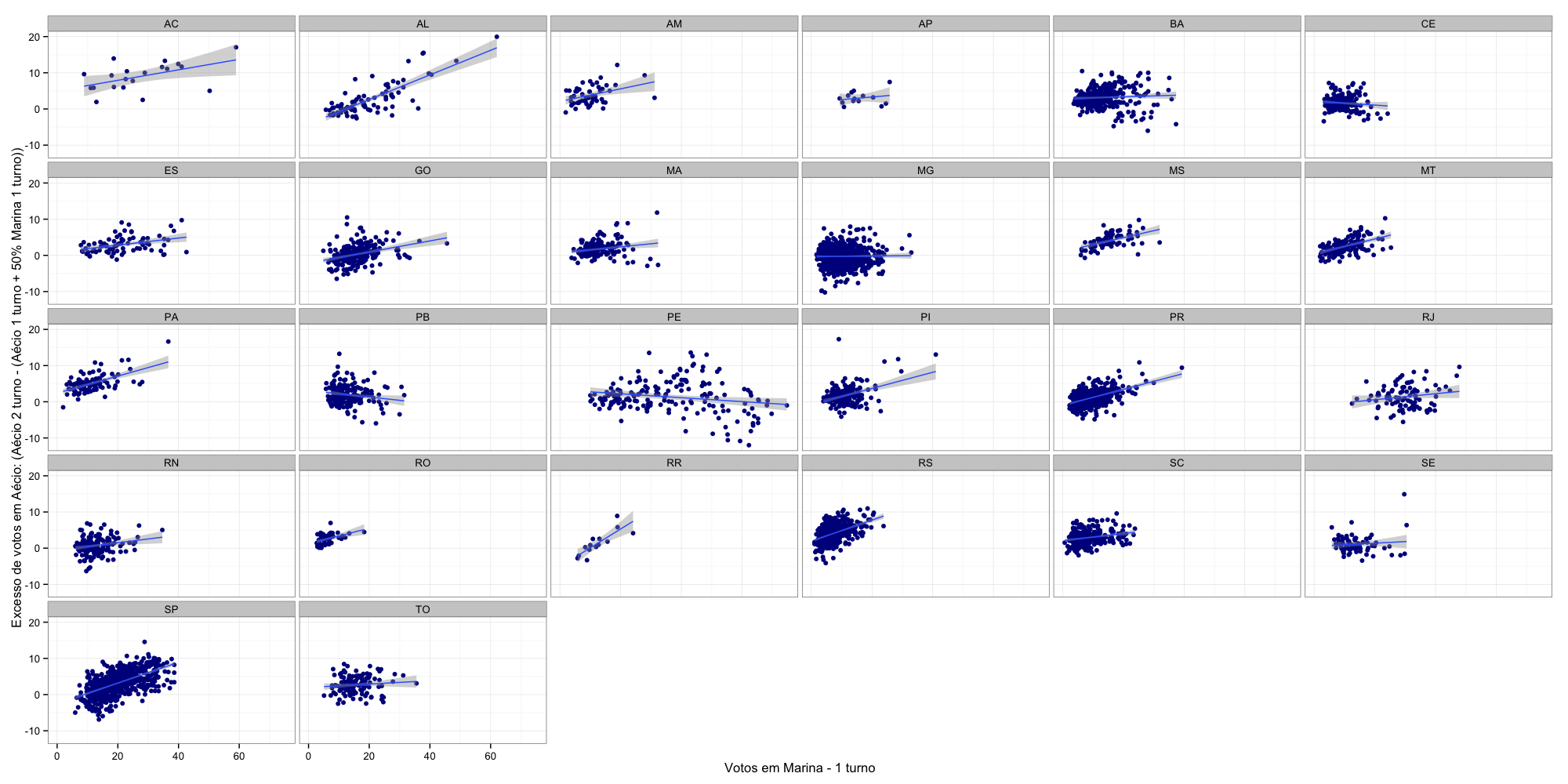
(ii) sim, a relação foi diferente para cada estado. Entre alguns exemplos, temos que em São Paulo, Rio Grande do Sul e Alagoas a relação pareceu mais pró Aécio; já em Minas Gerais e Bahia os votos em Marina explicaram pouco da variação. E em Pernambuco ou na Paraíba houve uma ligeira “conversão” pró Dilma.
***
A regressão geral.
| Dependent variable: | ||
| Variação Aécio | Variação Dilma | |
| (1) | (2) | |
| Votos Marina (1 turno) | 0.558*** | 0.442*** |
| (0.005) | (0.005) | |
| Constant | 1.287*** | -1.287*** |
| (0.076) | (0.076) | |
| Observations | 5,152 | 5,152 |
| R2 | 0.732 | 0.631 |
| Adjusted R2 | 0.732 | 0.631 |
| Residual Std. Error (df = 5150) | 2.987 | 2.987 |
| F Statistic (df = 1; 5150) | 14,087.540*** | 8,817.183*** |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | |
E os gráficos gerais e por UF (no gráfico temos o “excesso” de votos recebidos além do que seria esperado se os votos válidos de Marina tivessem sido distribuídos 50-50).
Aécio (Geral)
Aécio (Por UF)
Dilma (Geral)

Dilma (Por UF)