Paper do Pedro Souza e Marcelo Medeiros e apresentação do Marcelo Medeiros na UERJ:
Acurácia
Foda-se a nuance, entrevista com Alvin Roth, erro de medida no desemprego e Machine Learning no Airbnb.
Algumas leituras e vídeos interessantes
– Kieran Healy mandando um fuck nuance. (Abstract: Seriously, fuck it).
– Entrevista de Alvin Roth no Google:
– Sobre a acurácia das variáveis econômicas: quanto é o desemprego da China? Nessa linha, qual é a medida adequada para “desemprego”? Veja uma discussão interessante para o caso dos EUA no Econbrowser.
– Como o Airbnb usa Machine Learning?
Sobre a acurácia das variáveis econômicas – Dilbert Style.
Dilbert, resumindo Os Números (não) mentem em uma tirinha.

Ok, tenho resgatado uns cartoons velhos. Mas valem a pena, não valem!?
Estatísticas de homicídio – mais sobre erro de medida.
Qual foi a quantidade de homicídios no EUA em 2010? Três medidas diferentes, com 25% de diferença entre a maior e menor.
12,966, FBI, Crime in the United States 2010.
13,164, FBI, Crime in the United States 2011 (2010 figure).
14,720, Bureau of Justice Statistics (Table 1, based on FBI, Supplementary Homicide Statistics).
16,259, CDC (based on death certificates in the National Vital Statistics System).
Veja mais no Marginal Revolution.
Para saber mais sobre o assunto, veja no blog também aqui , aqui ,aqui, aqui, aqui e aqui.
Investimento Estrangeiro Direto no Brasil por Estado (Indústria)
Os dados do Censo de Capitais Estrangeiros no País, em 2010, trouxeram a distribuição do Investimento Estrangeiro Direto (IED) na indústria por Unidade da Federação (UF).
Somente da Indústria? E como foi feita a distribuição? Aqui voltamos ao que já dissemos sobre erro de medida (ver aqui, aqui, aqui e aqui, por exemplo). Distribuir o estoque investimento estrangeiro por UF é algo complicado, sujeito a erros diversos, tanto ao se definir a metodologia, quanto ao se mensurar o valor. No censo de 1995, por exemplo, os dados foram distribuídos por estado “[…] tomando por base o endereço da sede da empresa”. Será que essa é uma boa medida? Depende.
Percebe-se que uma indústria que concentre o grosso da sua estrutura produtiva no Pará, mas que tenha sede em São Paulo, será considerada um investimento nesta última UF. Se a intenção é medir onde se encontra o centro administrativo, esta medida poderá ser boa. Todavia, se intenção é medir onde se encontram as unidades produtivas, esta medida terá, talvez, distorções significativas. Qual a melhor forma, então, de se distribuírem os investimentos por estado? Pela localização da sede? Pela localização do ativo imobilizado? Pela distribuição dos funcionários? Particularmente, acho que não existe uma métrica única que se sobressaia às demais – a melhor opção depende do uso que você irá fazer da estatística.
Voltando ao Censo, a pesquisa passou a considerar a distribuição do ativo imobilizado como critério para alocação do IED – e apenas para a indústria . Os declarantes distribuíram percentualmente o seu imobilizado pelos diferentes estados e isso foi utilizado para ponderar o investimento direto pelas UF’s.
Segue abaixo mapa do Brasil com a distribuição do IED da indústria por Unidade Federativa:

Para aprender a fazer o mapa, veja aqui.
Concentração do Investimento Brasileiro no Exterior e erro de medida
Já que falamos do CBE no post anterior, aproveito para destacar outro dado daquela pesquisa, que muitas vezes passa despercebido: a concentração do Investimento Brasileiro Direto (IBD) no exterior em poucos investidores. Na publicação dos resultados, os declarantes foram separados pelo tamanho de seu investimento, como, por exemplo, investidores que possuem investimentos no exterior de até US$ 1 milhão (a menor categoria) ou investidores que possuem investimentos no exterior maiores do que US$1 bilhão (a maior categoria).
No quadro 2 da publicação, você encontrará a seguinte distribuição, reproduzida no gráfico abaixo (agrupei as duas últimas categorias do quadro). Em vermelho, você tem o percentual de investidores que se encontram naquela faixa de investimento – perceba que quase 70% dos declarantes do CBE têm um investimento menor ou igual a US$ 1 milhão e que apenas 0,3% dos declarantes possuem investimentos maiores do que US$500 milhões. Já em azul, você encontra o quanto cada uma dessas categorias responde pelo valor total declarado. Note que 0,3% dos declarantes respondem por cerca de 70% dos 356 bilhões de dólares que o Brasil possuía investidos no exterior.

Em outras palavras, a distribuição do IBD tem cauda bastante pesada – poucas observações respondem pela quase totalidade do valor. Além de ilustrar o grau de concentração deste tipo de investimento , isto tem uma implicação importante com relação ao (provável) erro de medida, e consequentemente, na incerteza dessas estatísticas.
Para tanto, vejamos o quadro 7, que é análogo ao quadro 2, mas faz a separação apenas para a modalidade de IBD participação no capital. Pelo quadro, 32 declarantes respondem por US$ 158 bilhões do estoque total, isto dá, na média, cerca de US$ 5 bilhões por declarante. Agora veja a distribuição da mesma modalidade por país (quadro 3). Em 2012, o maior estoque de IBD participação no capital, segundo o quadro 3 do CBE, estava na Áustria, com cerca de US$ 57 bilhões. Este valor, então, decresce exponencialmente, sendo a média por país mais ou menos US$ 6 bilhões e a mediana US$ 1 bilhão. Perceba que, caso apenas um dos grandes declarantes esteja classificado de forma errada – e considerando, conservadoramente, o valor médio do grupo – no melhor cenário, se o erro for na Áustria, isso responde por 10% do total estimado para aquele país; se for em um país de IBD médio, isso responde por um erro de 83%; e se for em um país de IBD mediano, o valor do erro é cinco vezes maior do que o valor estimado!
Então se, por um lado, o fato de a distribuição estar concentrada em poucos investidores reduz o número de declarantes que o Banco Central precisa investigar para validar grande parte do valor total declarado, por outro, o impacto de apenas um registro errado pode ser bastante significativo. Note a diferença deste tipo de estatística, para, por exemplo, a estimativa da expectativa de vida média do brasileiro – neste caso, vários registros errados dificilmente alterariam o valor médio de forma substancial.
Para finalizar, uma curiosidade. Veja abaixo os gráficos do logaritmo do valor do investimento (X) contra o logaritmo da probabilidade de o investidor ter investimentos maiores do que X (a linha preta é reta de regressão). Lembra o gráfico de um lei de potência, não?
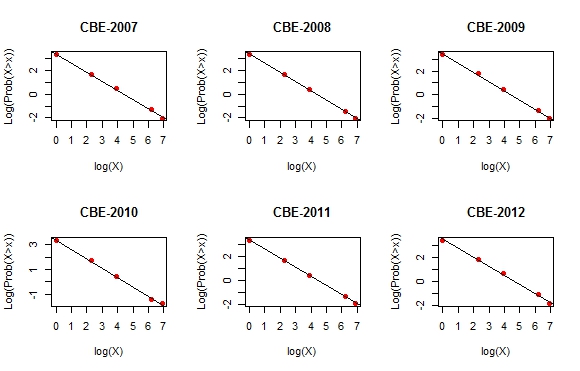 Mais sobre este tipo de assunto neste blog aqui.
Mais sobre este tipo de assunto neste blog aqui.
Erro de medida, Precificação de ativos e Prêmio Nobel
Entrevista com Larry Cahoon, estatístico do Censo norte-americano. Destaco a passagem abaixo, em que ele ressalta a importância de se saber sobre a variabilidade de uma estimativa, algo tão ou mais crítico do que saber a própria estimativa. Isto está em linha com o que discutimos acerca da acurácia das variáveis econômicas, aqui, aqui e aqui.
To do good statistics, knowledge of the subject matter it is being applied to is critical. I also learned early on that issues of variance and bias in any estimate are actually more important than the estimate itself. If I don’t know things like the variability inherent in an estimate and the bias issues in that estimate, then I really don’t know very much.
A favorite saying among the statisticians at the Census Bureau where I worked is that the biases are almost always greater than the sampling error. So my first goal is always to understand the data source, the data quality and what it actually measures.
But, I also still have to make decisions based on the data I have. The real question then becomes given the estimate on hand, what I know about the variance of that estimate, and the biases in that estimate, what decision am I going to make.
Se você não tinha seguido a recomendação de acompanhar o blog do Damodaran, seguem alguns posts interessantes que você perdeu:
– Chill, dude: Debt Default Drama Queens
– When the pieces add-up too much: Micro Dreams and Macro Delusions;
– Twitter announces the IPO: Pricing Games Begins, The Valuation, Why a good trade be a bad investment (or vice-versa).
Sobre o prêmio Nobel, saiu tanta coisa na internet que inclusive descobri muitos detalhes interessantes dos trabalhos dos três ganhadores que sequer imaginava. Deixo aqui, para quem ainda não leu, os materiais do Marginal Revolution e do Cochrane.
Sobre a acurácia das variáveis econômicas III
Em posts anteriores falamos sobre a qualidade dos dados macroeconômicos e que dados oficiais são estimativas (ver aqui e aqui). Mas, qual o sentido prático disto? Vejamos com um exemplo.
Na conta de importação de serviços do balanço de pagamentos do México, fretes e seguros respondem por US$ 9,8 bilhões, cerca de 33% dos US$ 29 bilhões que totalizam a rubrica – trata-se de seu componente mais relevante. Como o México estima esse valor?
Antes de entrar no caso do México, tratemos brevemente dos meios de estimação mais comuns de fretes e seguros entre os países. O primeiro método é por meio dos valores declarados na aduana. Quando esta tem um campo de fretes e seguros discriminados em algum documento administrativo, é possível ao compilador utilizar estes valores para a estimação. Um segundo método é utilizar alguma proporção das importações ou exportações. Muitas vezes, a aduana do país registra apenas o valor CIF das importações, isto é, o valor com os custos de fretes e seguros incluídos. Deste modo, o compilador realiza uma pesquisa a cada 5 ou 10 anos, por exemplo, para estimar qual é a proporção do valor importado que corresponde a fretes e seguros.
É possível que você tenha pensado: “o primeiro método, com os dados da aduana, não deveria ser considerado uma estimativa, é o valor real!”. Mas não é. Voltemos ao México.
O México é um país que poderia se enquadrar no primeiro caso – sua aduana registra valores de fretes e seguros. Contudo, os pagamentos de fretes e seguros relatados em uma operação da aduana correspondem à importação de uma ampla gama de produtos, de diferentes naturezas e de vários países, tudo consolidado em um único documento. A regulamentação aduaneira tem suas próprias peculiaridades, não necessariamente relacionadas às informações que desejariam os compiladores da estatística. Ao fim, os dados da aduana lhes pareciam muito imprecisos, subestimados e demasiadamente agregados.
Com isto em mente, o Banxico buscou metodologia alternativa. Sua intenção era calcular o valor ao custo real de mercado e, assim, buscou preços no país vizinho, os Estados Unidos, que publicam, mensalmente, dados de custo médio dos fretes e seguros de importação por tipo de produto, país de origem e meio de transporte. Entretanto, o custo médio varia bastante por volume importado, e é preciso realizar este ajuste. Assim, roda-se uma regressão deste custo médio contra dummies dos portos dos EUA (pois cada porto pode ter um custo diferente) e volume importado (em log), para encontrar o coeficiente de ajuste entre volume e custo médio, chamado aqui de beta. Com o custo médio, o beta para ajuste e o volume das importações mexicanas em mãos , é possível estimar os custos de fretes e seguros do país. Atualizam-se o beta anualmente e o preço médio mensalmente sendo possível, deste modo, obter estimativas por produto, país e meio de transporte, que variam conforme condições de mercado, algo que não seria factível com os dados administrativos da aduana.
Mas, qual a diferença deste valor com o anterior, da aduana? O novo método estima custos cerca de duas vezes maiores e isso pareceu mais alinhado à realidade de mercado do que os dados anteriormente declarados. É uma diferença bem significativa.
Portanto, é importante atentar-se para dois detalhes: (i) dados que, a primeira vista, poderiam ser considerados “os valores reais” (dados de questionários, formulários administrativos, etc), podem ter problemas e estar tão sujeitos a erros quanto outros procedimentos; (ii) muitos componentes dos dados macroeconômicos que você utiliza, tal como a conta de fretes e seguros do exemplo acima, são derivados de um processo de estimação prévia. No nosso exemplo, seja o dado administrativo, ou o dado derivado pela outra metodologia, fica claro que ambos têm que ser vistos como estimativas, cada método com suas vantagens e limitações, sendo preciso entendê-las para saber o que aquele dado pode ou não pode te responder.
Sobre a acurácia das variáveis econômicas II
Em post anterior tratamos da importância de se conhecer bem as variáveis com que se trabalha. Muitas vezes o economista utiliza dados que, por sua dificuldade de mensuração, são estimados por terceiros (IBGE, Banco Central, Tesouro Nacional etc). Assim, há uma tendência a se saber muito pouco sobre como esses dados são produzidos na prática e, sem entender quais suas limitações e quais seus pontos fortes, se esquece de tratá-los devidamente como estimativas.
Neste sentido, gostei muito de ver que outros blogs tem compartilhado desta mesma preocupação.
Dave Giles, por exemplo, resume algumas verdades importantes sobre dados oficiais, que são comumente esquecidas:
- Dados são revisados o tempo inteiro: o número que saiu ontem do PIB pode mudar drasticamente amanhã.
- Dados somem: eu já enfrentei isso com uma série de horas de trabalho que estava disponível no IPEA Data e que, alguns meses depois, simplesmente foi descontinuada e excluída.
- As definições e metodologia mudam: por exemplo, a metodologia do Censo de Capitais Estrangeiros no País mudou recentemente. O usuário tem que ter isto em mente e não pode simplesmente comparar um dado com outro sem ajustes.
- Os dados oficiais são estimativas: sobre isso tratamos no post anterior!
Dave Giles também recomendou alguns papers sobre o assunto e tratou de um interessante relatório sobre a qualidade dos dados chineses, aspecto fundamental para quem analisa aquela economia.
Já Mark Thoma começou a se dar conta do problema ao ler a notícia de que o IBGE americano está incorporando novos aspectos às contas nacionais que, simplesmente, podem “reescrever a história econômica”. Você já parou para se perguntar quantos “fatos estilizados” que conhecemos, como, por exemplo, a semi-estagnação de algumas economias desenvolvidas, podem (ou não) ser fruto da adoção de uma ou outra metodologia? Em posts futuros trarei exemplos interessantes de dados oficiais que são estimativas, mas agora queria tratar sobre aspectos que norteiam a discussão sobre a qualidade dos dados.
Sobre este quesito, o FMI tem um site inteiramente dedicado ao assunto: o Data Quality Reference Site. Trata-se de um louvável esforço para promover a agenda de pesquisa sobre a qualidade dos dados (macro)econômicos. O Fundo criou um interessante marco para a avaliação da qualidade – em um aspecto ainda qualitativo e não quantitativo – dividido em 6 dimensões:
0 – Condições Prévias: busca verificar alguns aspectos institucionais para a produção do dado, como o entorno jurídico e a quantidade de recursos disponível;
1 – Garantias de Integridade: avalia aspectos como o profissionalismo, a transparência e as normas éticas da produção;
2 – Rigor Metodológico: inspeciona se os conceitos e definições adotados estão conformes ao padrão internacional, se o alcance da pesquisa é suficiente, se as categorizações são adequadas;
3 – Acurácia e Confiança: verificam a adequação das fontes de dados utilizadas, se há um processo de avaliação, validação e revisão dos dados, se as técnicas estatísticas são sólidas;
4 – Utilidade para o Usuário: trata de questões de periodicidade, pontualidade, consistência e revisão;
5 – Acesso: aborda questões de acesso aos dado, acesso aos metadados (isso é, aos dados sobre como os dados foram produzidos) e assistência aos usuários.
O ideal seria termos, também, uma noção quantitativa do erro, mas este esforço já é um grande passo. Você pode encontrar o detalhamento destes pontos para contas nacionais, contas externas, finanças públicas, índices de preço, entre outros, em seu respectivo Data Quality Assessment Framework.
Você, que já trabalhou ou pretende trabalhar com dados em painel, comparando diversos países, já teve a curiosidade de se perguntar sobre a diferente qualidade dos dados que está misturando?
Para alguns países, é possível fazer isso analisando o seu Report on the Observance of Standards and Codes (mais conhecido como ROSC) sobre dados. Tomando o caso do Chile como exemplo, que possui um ROSC para dados no ano de 2007, seria possível descobrir que havia sérios problemas no escopo da pesquisa de índices de preços, e que havia propostas para solucionar a questão em dezembro de 2008. Perceba que, para quem trabalha com dados de preços chilenos antes de 2007, esta é uma informação fundamental!
Sobre a acurácia das variáveis econômicas
Segundo as contas nacionais trimestrais do IBGE, o PIB brasileiro no terceiro trimestre de 2012, a preços constantes de 1995, foi de R$ 292.011.667.484,06. Isto resultou em uma variação real de 0,8652892558907% em relação ao mesmo período do ano anterior.
Qual a acurácia destes números? Ninguém em sã consciência acreditaria que os últimos seis centavos são exatos ou precisos. Poucos também apostariam grande soma com relação à exatidão dos quatrocentos e oitenta e quatro reais. É bem possível que existam erros na ordem dos milhões; e, quem sabe, dos bilhões. Mas não sabemos quanto.
Diferentemente de pesquisas eminentemente amostrais (como a PME, por exemplo), dados como o PIB, que envolvem a agregação de diversos valores, com metodologias bastante diferentes, não costumam ser acompanhados de uma medida quantitativa de erro. Isto ocorre porque são consultadas várias fontes de informação para se gerar a estimativa do PIB: governamentais, pesquisas de campo amostrais, pesquisas quase-censitárias, formulários administrativos, extrapolações, interpolações, entre outros instrumentos. Cada uma dessas fontes está sujeita a diversos vieses, erros amostrais e não-amostrais, sendo bastante difícil chegar a uma medida quantitativa da incerteza em relação ao número.
Antes que me entendam mal, vale ressaltar: não estou criticando o IBGE, que atualmente é respeitado nacionalmente e internacionalmente por seus dados, principalmente se compararmos com os dados da Argentina os dados de outros países.
A questão é que o erro existe e isso é natural. A mensuração é uma atividade fundamental na ciência*, mas junto de toda mensuração há incerteza, bem como um trade-off entre custo e acurácia. Definir o grau de exatidão e precisão (e que tipo de exatidão e precisão**) a se alcançar depende de saber tanto para quê o dado será utilizado, quanto o custo de torná-lo mais acurado. Além disso, uma vez coletado o dado, saber a incerteza presente no número é, às vezes, quase tão importante quanto saber o próprio número, posto que exercício fundamental para – como diria Morgenstern – podermos distinguir “entre o que achamos que sabemos e o que de fato sabemos ou o que de fato podemos saber” com esses dados .
Entretanto, ao se observar a mídia e, inclusive, trabalhos acadêmicos, a impressão que se tem é a de que muitos dos números econômicos divulgados não são vistos como estimativas, mas como valores reais, absolutos. Muitas vezes se toma o número pelo seu valor de face. E, para a ciência econômica, isso pode ser um grande problema.
Para não ficar em uma discussão etérea, vejamos alguns exemplos.
Primeiro – a Pesquisa Mensal de Emprego (PME), que divulga uma medida de erro. Este caso ilustra como esta medida pode ser importante para se interpretar o número. No boxe do relatório de inflação de dezembro de 2012, há uma discussão sobre a aparente contradição entre os cenários sugeridos pelos dados da PME e pelos dados do Caged para o mercado de trabalho. Um dos pontos relacionados no texto, para conciliar os cenários das duas pesquisas, é o erro amostral, que evidencia o cuidado que tem de ser tomado ao interpretar as variações mês a mês da PME. Por exemplo, em outubro de 2012, o coeficiente de variação da pesquisa foi de 0,7%; assim, uma variação nos dados, suponha, de 0,6%, é consistente tanto com um crescimento robusto do emprego (uma taxa anualizada de 7,8%), quanto com uma variação natural na amostra.
Segundo, um exemplo anedótico – o caso dos livros que pesam 0Kg. Este é um exemplo propositalmente absurdo e que, por isso mesmo, torna o problema da falta de informação sobre o erro auto-evidente. Suponha que, além dos livros em que a balança acusou o peso de 0Kg, tenhamos uma terceira medida com peso de 2Kg. Tomando os dados por seu valor de face, o peso total dos livros seria, aritmeticamente, 0Kg + 0Kg + 2Kg= 2Kg. O número final é manifestamente errado, pois não sabemos a ordem de grandeza que o instrumento de mensuração (a balança) consegue identificar. A partir do momento em que se sabe que a balança é errática para pesos menores do que 2Kg, você percebe que este dado não serve para distinguir entre um peso total de 2Kg e um peso total de 6Kg. Entretanto serviria caso você quisesse saber se os livros pesam menos do que 20Kg. Veja, estamos distinguindo “entre o que achamos que sabemos e o que de fato sabemos ou o que de fato podemos saber” com esses dados.
Terceiro, talvez um caso de erro proposital – os dados do Indec sugerem que o crescimento argentino, desde 2002, apresenta taxa de cerca de 7,7% ao ano. Este dado, entretanto, pode servir para julgar a eficácia das políticas econômicas dos hermanos? Alexandre Schwartsman sugere que não, mostrando inconsistência considerável entre os dados do PIB e os dados de geração de energia da Argentina. Inclusive, dados de preços coletados on-line sugerem que também os índices de preços oficiais parecem ter erro muito grande para qualquer inferência.
Os exemplos acima ilustram como os dados são matéria prima importante para a economia, e também mostram que ter uma medida do erro inerente a esses dados nos ajuda a entender o que eles podem e o que eles não podem responder. Com esta preocupação em mente, comecei a procurar trabalhos sobre o assunto, e tive contato com o livro de Morgenstern “On the accuracy of economics observations”. Este trabalho, cuja segunda e última revisão é de 1963, foi o único que encontrei que discute extensivamente os problemas inerentes a muitas variáveis (macro)econômicas (caso alguém tenha conhecimento de algo com este fôlego e mais recente, favor indicar).
O trabalho passa por discutir a natureza dos dados econômicos não experimentais, os diversos tipos de erro naturalmente esperados, e ainda trata de vários exemplos nas mais diversas áreas (comércio exterior, índices de preços, emprego, PIB). Como este post já esta enorme, vou apenas mencionar um exemplo de contas nacionais, trazido por Morgenstern.
Como dissemos no início do post, os valores publicados nas contas nacionais são daquele tipo de estatística em que uma medida de erro não tem uma fórmula pronta, sendo difícil quantificar a incerteza. Entretanto, Kuznets, à época, reuniu especialistas envolvidos no cálculo do PIB para tentar chegar a uma medida. Resultado: cerca de 10%. Qual a implicação disso? Veja o gráfico abaixo (p.269):
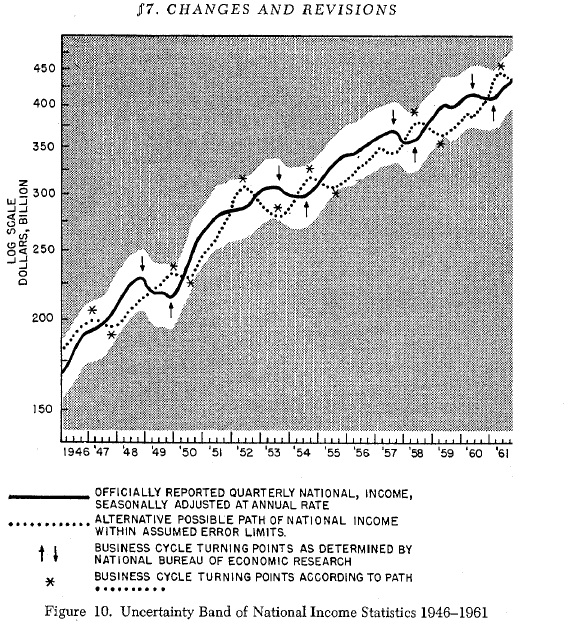
Morgenstern mostra os dados de renda nacional bruta dos EUA, de 1946 a 1961, com o intervalo de 10% de erro. Neste caso, nota-se que os dados servem para analisar o crescimento econômico de longo prazo, mas são bastante duvidosos quanto sua utilidade para se confrontar teorias de ciclos econômicos, pois além dos ciclos divulgados oficialmente (reta contínua do gráfico) outra trajetória, com ciclos opostos, também é consistente com o erro (reta tracejada do gráfico).
Com o avanço da tecnologia, é provável que os dados de hoje não sejam tão incertos quanto os da época. Mas não sabemos em que medida, e isso é fundamental para distinguirmos o que podemos extrair dos dados. Estamos em uma época em que o reconhecimento do erro, da aleatoriedade, e da incerteza está se tornando cada vez mais comum e, talvez, seja hora de tentar resgatar a linha de pesquisa de Morgenstern.
* pelo menos para aqueles que descem do pedestal criado para si em sua própria mente e buscam confrontar ideias, sempre sujeitas a erro, com o que se observa.
** por exemplo, suponha que você tenha dois métodos para medir uma variável, em um deles você sabe que há alta probabilidade de subestimar a medida e, com o outro, alta probabilidade de superestimá-la: qual é melhor?
