Machine Learning
Detectando reviews falsos na Amazon
Agora que comecei a usar mais a Amazon no dia-a-dia (usava basicamente para livros e eletrônicos) percebi a quantidade assustadora de reviews falsos que existem por lá. Isso naturalmente levou a outra pergunta: que tal usar análise de dados para filtrar os reviews falsos dos verdadeiros?
Pois bem, como quase toda a idéia que temos, alguém já a implementou. Então se você ainda não conhece, vai aqui a dica do fakespot. Usando técnicas de processamento de linguagem natural e machine learning, o site tenta identificar quais e quantos reviews são realmente autênticos. O serviço poderia ser melhor executado, mas tem funcionado bem nos casos que testei.
Seminário – Ciência de Dados e Sociedade, dia 15 de Junho às 19h, no Auditório do Instituto de Ciência Política da UnB
Inscrições e mais informações aqui. Estaremos no seminário eu, Daniel Marcelino e Rommel Carvalho.
Previsões para o Impeachment
Agora que o processo foi aberto, acho que muitos vão querer brincar com diferentes cenários. Por enquanto conheço apenas duas ferramentas que possam satisfazer um pouco sua curiosidade:

(se o site não funcionar agora, tente novamente mais tarde, o Polling Data está passando por problemas técnicos)
2. O “Vai Passar” do Estadão Dados (mas que não tem a opção de simular com 2/3 dos votos).
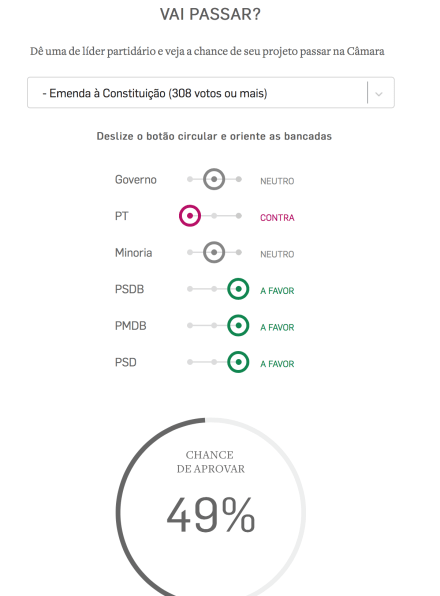
PS: o que mais gostaria de ver agora seria uma análise com teoria dos jogos explicitando bem todos os jogadores, as jogadas permitidas e respectivos payoffs .
Let the simulations begin!
Inferência causal e Big Data: Sackler Big Data Colloquium
Uma série de palestras interessantes do Sackler Big Data Colloquium:
Hal Varian: Causal Inference, Econometrics, and Big Data
***
Leo Bottou: Causal Reasoning and Learning Systems
***
David Madigan: Honest Inference From Observational Database Studies
***
Susan Athey: Estimating Heterogeneous Treatment Effects Using Machine Learning in Observational Studies
Foda-se a nuance, entrevista com Alvin Roth, erro de medida no desemprego e Machine Learning no Airbnb.
Algumas leituras e vídeos interessantes
– Kieran Healy mandando um fuck nuance. (Abstract: Seriously, fuck it).
– Entrevista de Alvin Roth no Google:
– Sobre a acurácia das variáveis econômicas: quanto é o desemprego da China? Nessa linha, qual é a medida adequada para “desemprego”? Veja uma discussão interessante para o caso dos EUA no Econbrowser.
– Como o Airbnb usa Machine Learning?
Uma introdução visual ao aprendizado de máquinas (Machine Learning)

Quando confiar nas suas previsões?
Quando você deve confiar em suas previsões? Como um amigo meu já disse, a resposta para essa questão é fácil: nunca (ou quase nunca).
Mas, brincadeiras à parte, para este post fazer sentido, vou reformular a pergunta: quando você deve desconfiar ainda mais das previsões do seu modelo?
Há várias situações em que isso ocorre, ilustremos aqui uma delas.
***
Imagine que você tenha as seguintes observações de x e y.
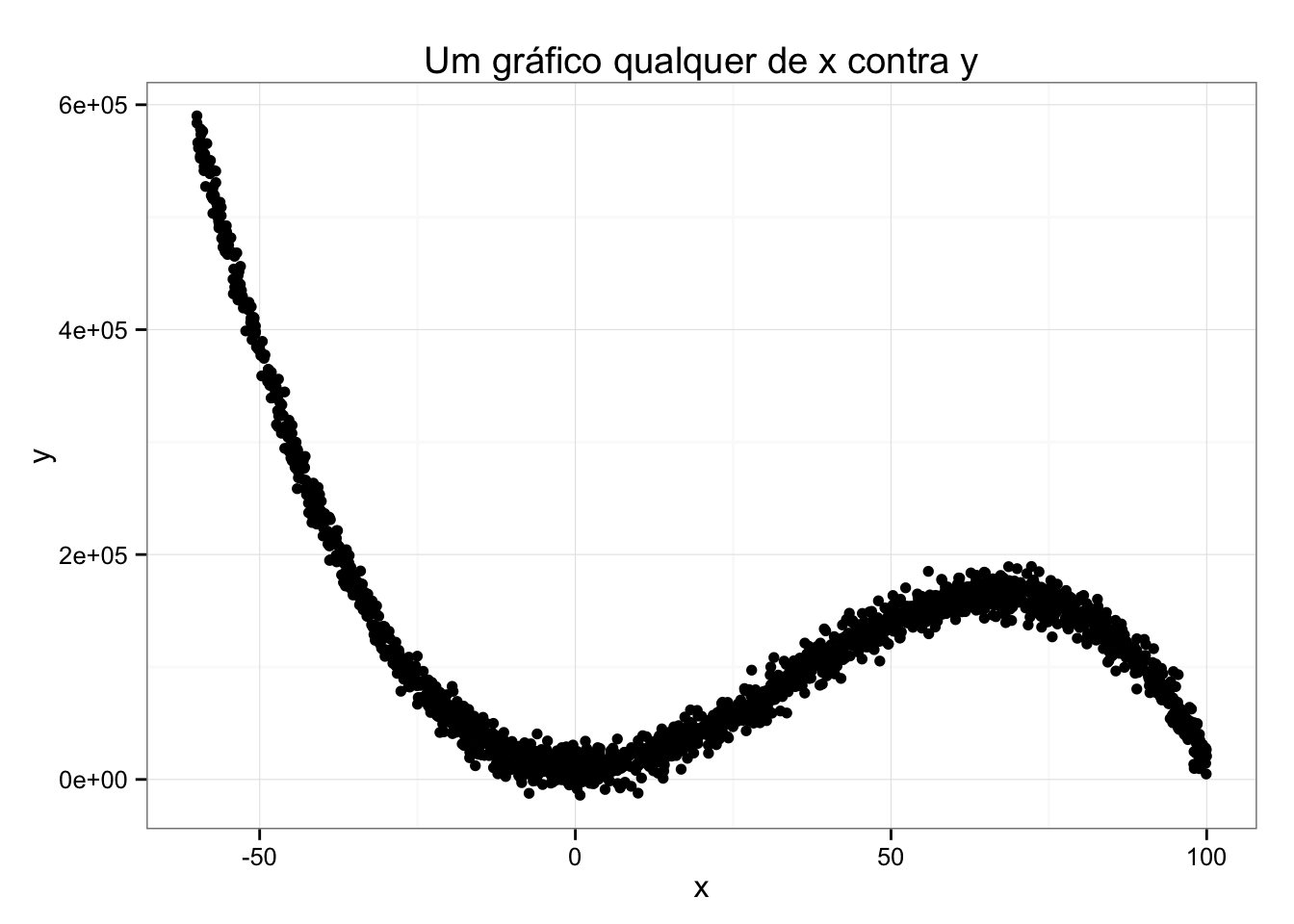
Para modelar os dados acima, vamos usar uma técnica de machine learning chamada Suport Vector Machine com um núcleo radial. Se você nunca ouviu falar disso, você pode pensar na técnica, basicamente, como uma forma genérica de aproximar funções.
Será que nosso modelo vai fazer um bom trabalho?
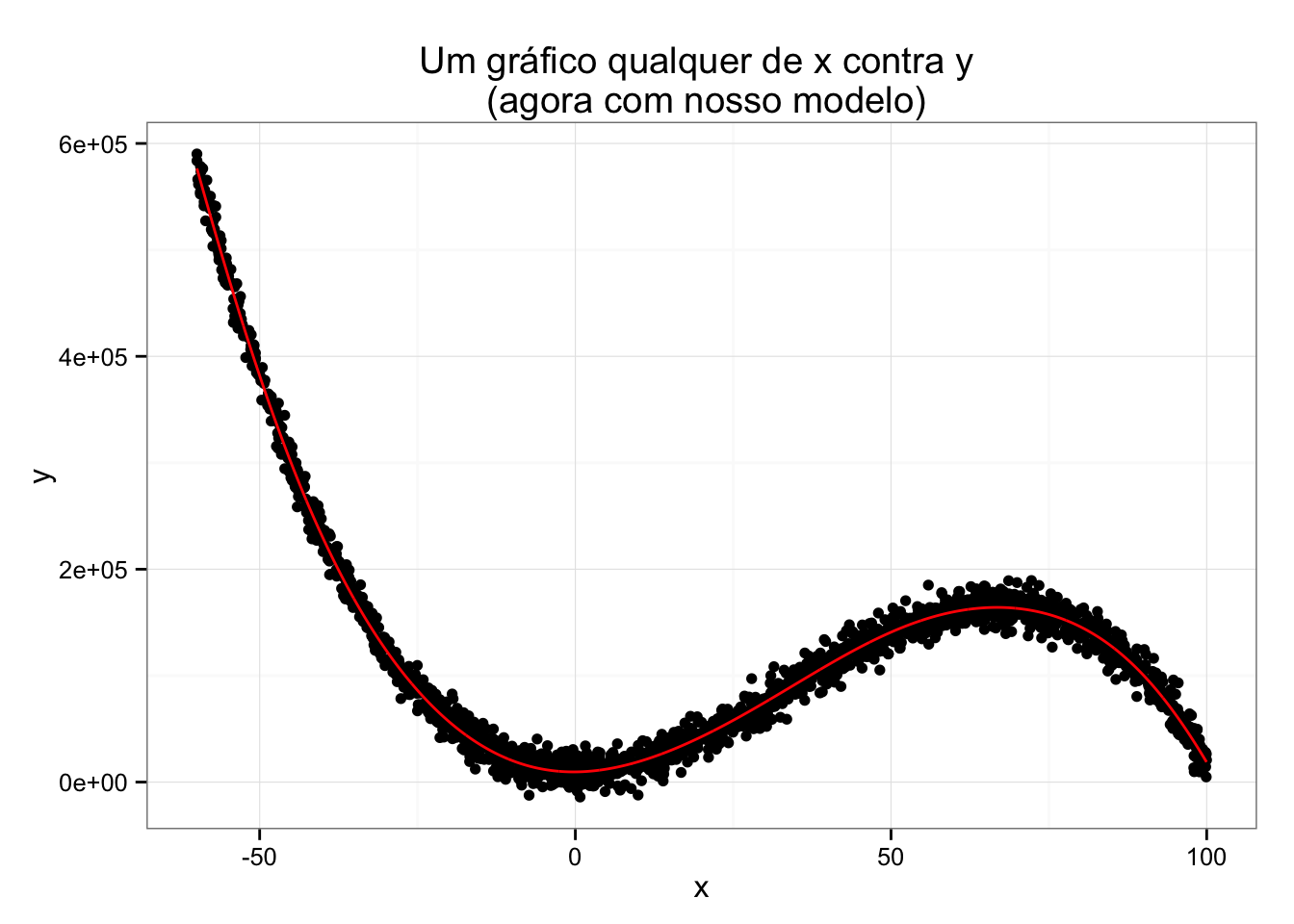
Pelo gráfico, é fácil ver que nossa aproximação ficou bem ajustada! Para ser mais exato, temos um R2 de 0.992 estimado por cross validation (que é uma estimativa do ajuste fora da amostra – e é isso o que importa, você não quer saber o quão bem você fez overfitting dos dados!).
Agora suponha que tenhamos algumas observações novas, isto é, observações nunca vistas antes. Só que essas observações novas serão de dois “tipos”, que aqui criativamente chamaremos de tipo 1 e tipo 2. Enquanto a primeira está dentro de um intervalo de x que observamos ao “treinar” nosso modelo, a segunda está em intervalos muito diferentes.
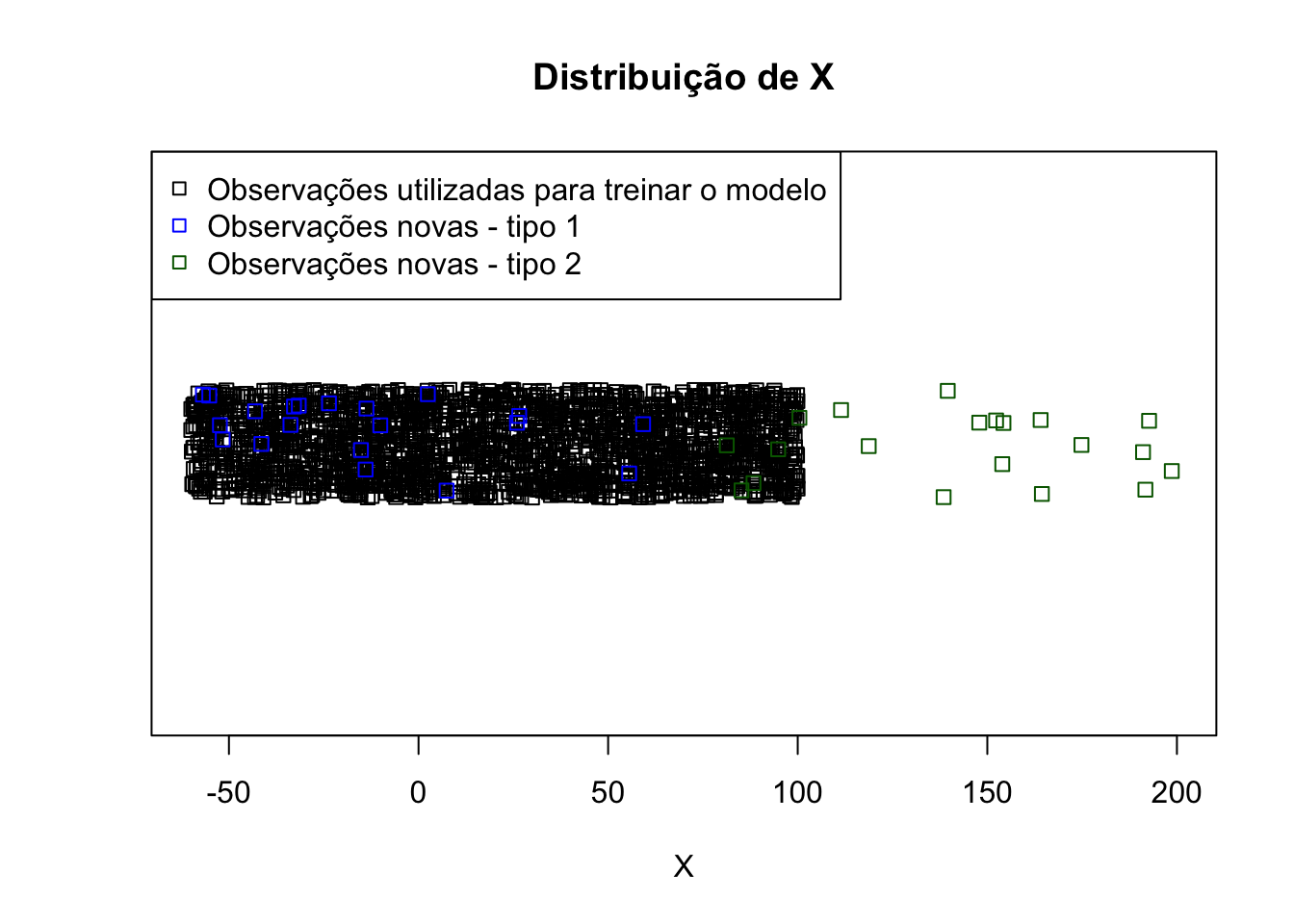
Qual tipo de observação você acha que teremos mais dificuldades de prever, a de tipo 1 ou tipo 2? Você já deve ter percebido onde queremos chegar.
Vejamos, portanto, como nosso modelo se sai agora:
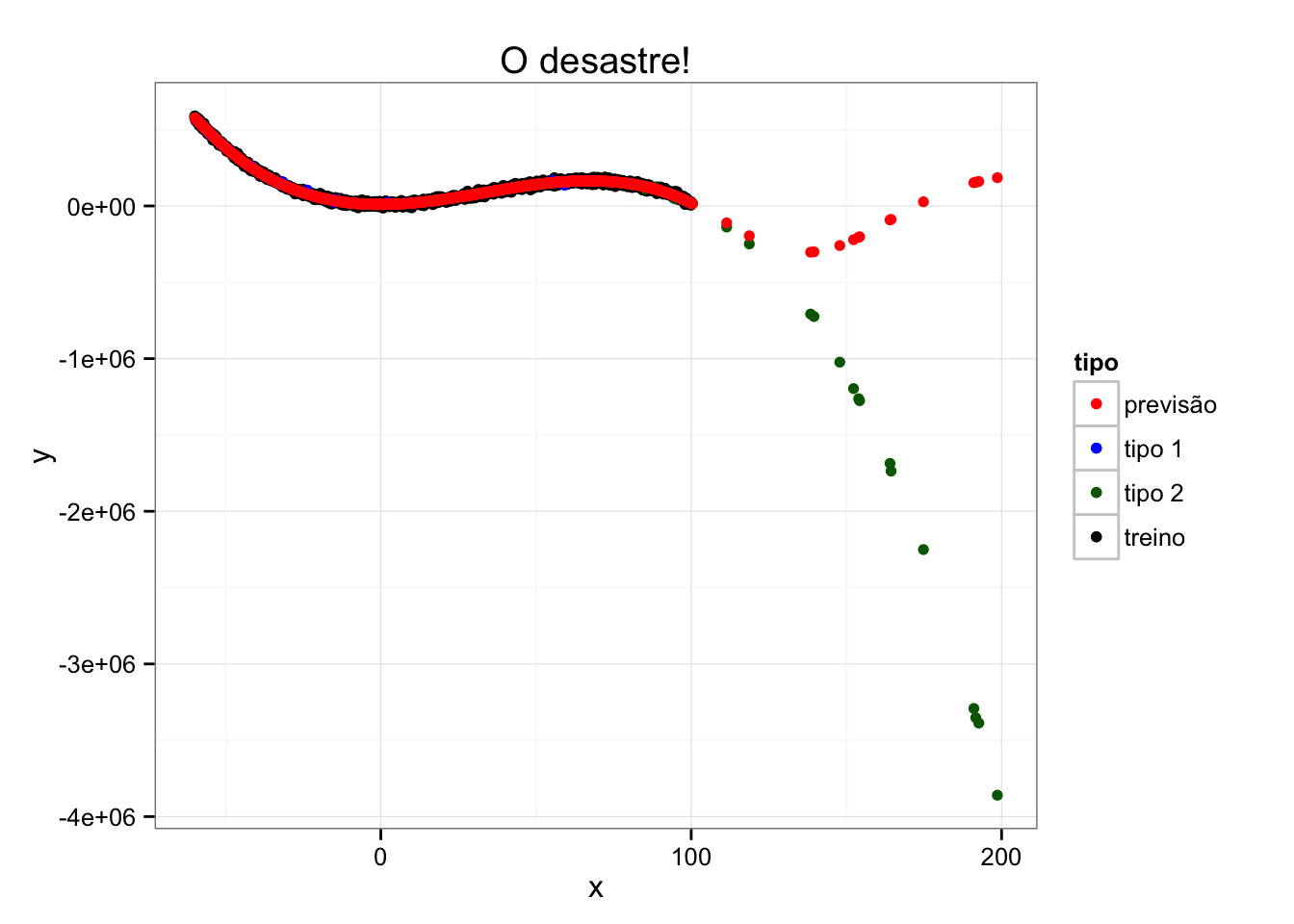
Note que nas observações “similares” (tipo 1) o modelo foi excelente, mas nas observações “diferentes” (tipo 2) nós erramos – e erramos muito. Este é um problema de extrapolação.
Neste caso, unidimensional, foi fácil perceber que uma parte dos dados que gostaríamos de prever era bastante diferente dos dados que usamos para modelar. Mas, na vida real, essa distinção pode se tornar bastante difícil. Uma complicação simples é termos mais variáveis. Imagine um caso com mais de 20 variáveis explicativas – note que já não seria trivial determinar se novas observações são similares ou não às observadas!
Quer aprofundar mais um pouco no assunto? Há uma discussão legal no livro do Max Kuhn, que já mencionamos aqui no blog.
Competições de análise de dados: BoE e Kaggle
Quer mostrar suas habilidades de visualização de dados ou previsão? Seguem dois links:
– Uma competição de visualização do Bank of England. Na verdade, a primeira competição deste tipo que o BoE lança. O prazo final é primeiro de maio. A final da competição ocorrerá em Londres e o BoE não pagará passagens para os finalistas (mas, se eu fosse você, tentaria chegar na final antes de decidir se isso será um problema). O prêmio é de 5.000 libras (mais de R$ 20.0000).
– Um site sobre o qual sempre quis falar mais detalhadamente por aqui, mas ainda não tive tempo, é o Kaggle. Resumidamente, o Kaggle é um site de competições de modelagem preditiva em que as empresas colocam os problemas que gostariam de solucionar (juntamente com um prêmio) e analistas de todo o mundo competem para produzir os melhores modelos. Atualmente há dois grandes prêmios sendo disputados:
- US$ 100.000,00 para quem criar o melhor modelo preditivo para sinais de retinopatia diabética com imagens do olho.
- US$ 30.000,00 para quem criar o melhor modelo preditivo para faturamento de restaurantes.
Além de outros prêmios de menor montante. Não somente isso, participantes do Kaggle que conseguem boas classificações também conseguem, em geral, bons empregos na área.
useR! 2014 – Palestra do John Chambers e entrevista com Hadley Wickham
Eduardo Arino de la Rubia acabou de me informar que, hoje, entrou no ar o site datascience.la, e já com dois vídeos interessantes decorrentes do useR! 2014: uma palestra do John Chambers e uma entrevista com Hadley Wickham.
Após o primeiro dia de tutoriais, o segundo dia da conferência se iniciou com uma apresentação de John Chambers (slides aqui e vídeo abaixo). Para quem não conhece, John Chambers é o criador da linguagem S (pela qual ganhou o prêmio ACM Software System) que se tornou o “pai” do R e atualmente é um dos membros do core team do R. O foco da palestra foi o de ressaltar o papel do R não como uma solução geral que tenta resolver todos os problemas, mas principalmente como uma interface geral que converse com outros instrumentos e ferramentas quando necessário (como, por exemplo, quando a base de dados é muito grande para caber na memória). Para ilustrar iniciativas com esta filosofia, ele citou três frentes em especial:
- Interface com C++ e C++11, como já havíamos mencionado no post anterior. Os pacotes que têm recebido destaque nesta área são o Rcpp e Rcpp11;
- LLVM, com o pacote RLLVM do Duncan Temple Lang.
- Machine Learning em grandes bases de dados e o exemplo foi o H2O e seu pacote homônimo, mas em caixa baixa, para o R.
Confira a apresentação na íntegra abaixo:
Além disso, o Eduardo fez várias entrevistas interessantes no decorrer do encontro e agora começou postar os vídeos. O primeiro deles é com o Hadley Wickham e as perguntas estão excelentes. Vale conferir!
