Compartilharam comigo, agora passo em frente. Seguem dois links com alguns livros em pdf para programação em R e em Python.
Mais sobre Python: o Sargent publicou um livro online de modelagem e economia quantitativa com a linguagem.
Compartilharam comigo, agora passo em frente. Seguem dois links com alguns livros em pdf para programação em R e em Python.
Mais sobre Python: o Sargent publicou um livro online de modelagem e economia quantitativa com a linguagem.
Já que falamos do CBE no post anterior, aproveito para destacar outro dado daquela pesquisa, que muitas vezes passa despercebido: a concentração do Investimento Brasileiro Direto (IBD) no exterior em poucos investidores. Na publicação dos resultados, os declarantes foram separados pelo tamanho de seu investimento, como, por exemplo, investidores que possuem investimentos no exterior de até US$ 1 milhão (a menor categoria) ou investidores que possuem investimentos no exterior maiores do que US$1 bilhão (a maior categoria).
No quadro 2 da publicação, você encontrará a seguinte distribuição, reproduzida no gráfico abaixo (agrupei as duas últimas categorias do quadro). Em vermelho, você tem o percentual de investidores que se encontram naquela faixa de investimento – perceba que quase 70% dos declarantes do CBE têm um investimento menor ou igual a US$ 1 milhão e que apenas 0,3% dos declarantes possuem investimentos maiores do que US$500 milhões. Já em azul, você encontra o quanto cada uma dessas categorias responde pelo valor total declarado. Note que 0,3% dos declarantes respondem por cerca de 70% dos 356 bilhões de dólares que o Brasil possuía investidos no exterior.

Em outras palavras, a distribuição do IBD tem cauda bastante pesada – poucas observações respondem pela quase totalidade do valor. Além de ilustrar o grau de concentração deste tipo de investimento , isto tem uma implicação importante com relação ao (provável) erro de medida, e consequentemente, na incerteza dessas estatísticas.
Para tanto, vejamos o quadro 7, que é análogo ao quadro 2, mas faz a separação apenas para a modalidade de IBD participação no capital. Pelo quadro, 32 declarantes respondem por US$ 158 bilhões do estoque total, isto dá, na média, cerca de US$ 5 bilhões por declarante. Agora veja a distribuição da mesma modalidade por país (quadro 3). Em 2012, o maior estoque de IBD participação no capital, segundo o quadro 3 do CBE, estava na Áustria, com cerca de US$ 57 bilhões. Este valor, então, decresce exponencialmente, sendo a média por país mais ou menos US$ 6 bilhões e a mediana US$ 1 bilhão. Perceba que, caso apenas um dos grandes declarantes esteja classificado de forma errada – e considerando, conservadoramente, o valor médio do grupo – no melhor cenário, se o erro for na Áustria, isso responde por 10% do total estimado para aquele país; se for em um país de IBD médio, isso responde por um erro de 83%; e se for em um país de IBD mediano, o valor do erro é cinco vezes maior do que o valor estimado!
Então se, por um lado, o fato de a distribuição estar concentrada em poucos investidores reduz o número de declarantes que o Banco Central precisa investigar para validar grande parte do valor total declarado, por outro, o impacto de apenas um registro errado pode ser bastante significativo. Note a diferença deste tipo de estatística, para, por exemplo, a estimativa da expectativa de vida média do brasileiro – neste caso, vários registros errados dificilmente alterariam o valor médio de forma substancial.
Para finalizar, uma curiosidade. Veja abaixo os gráficos do logaritmo do valor do investimento (X) contra o logaritmo da probabilidade de o investidor ter investimentos maiores do que X (a linha preta é reta de regressão). Lembra o gráfico de um lei de potência, não?
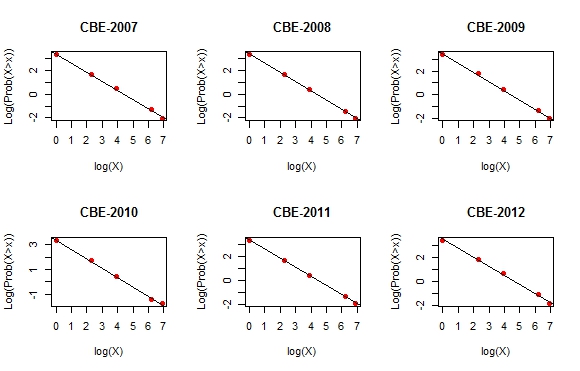 Mais sobre este tipo de assunto neste blog aqui.
Mais sobre este tipo de assunto neste blog aqui.
No post anterior vimos quais países tem investimento direto no Brasil (pelo critério de país de origem imediata).
Agora, que tal visualisarmos em que países os brasileiros investem?
Para tanto, podemos pegar os dados da pesquisa de Capitais Brasileiros no Exterior. Tal qual criança quando ganha um brinquedo novo, vamos lá brincar no R mais uma vez. Abaixo, mapa com a distribuição do Investimento Brasileiro Direto (IBD), participação no capital, conforme país de destino imediato, em 2012.

PS: encontrei o pdf do Applied Spatial Data Analysis with R, então esperem mais posts deste tipo.
Que tal visualizar os dados do Censo de Capitais Estrangeiros de uma maneira diferente?
Abaixo, mapa com a distribuição do Investimento Estrangeiro Direto (IED) no Brasil, critério participação no capital, em 2010, segundo o país de origem imediata. O mapa foi feito no R. Quanto mais escuro, maior o investimento daquele país em empresas brasileiras.

PS: agradeço ao Rogério pelo didático post ensinando o caminho das pedras.
Já falamos que os p-valores não podem ser interpretados como uma medida absoluta de evidência, como comumente costumam ser. Entre algumas interpretações recorrentes, por exemplo, vale mencionar alguns cuidados:
Dentre outras questões.
Mas o que essas coisas querem realmente dizer? Muitas vezes é difícil entender o conceito sem exemplos (e gráficos) e é isso que pretendemos trazer hoje aqui. Vamos tratar do primeiro ponto listado, uma questão que, muitas vezes, pode confundir o usuário do p-valor: o p-valor pode apresentar evidências de que alguém seja obeso e, ao mesmo tempo, evidências de que este alguém não seja gordo, caso você, por descuido, tome o p-valor como uma medida absoluta de evidência e leve suas hipóteses nulas ao pé da letra. O exemplo abaixo foi retirado do artigo do Alexandre Patriota (versão publicada aqui).
Considere duas amostras aleatórias, com 100 observações cada, de distribuição normal com médias desconhecidas e variância igual 1. Suponha que as médias amostrais calculadas nas duas amostras tenham sido x1=0.14 e x2=-0.16 e que você queira testar a hipótese nula de que ambas as médias populacionais sejam iguais a zero.
A estatística para esta hipótese é n*(x1^2+x2^2), e o valor obtido na amostra é 100*(0.14^2+(-0.16)^2)=4.52. A distribuição desta estatística, sob a hipótese nula, é uma qui-quadrado com 2 graus de liberdade, o que te dá um p-valor de 10%. Assim, se você segue o padrão da literatura aplicada, como o p-valor é maior do que 5%, você dirá que aceita (ou que não rejeita) a hipótese nula de que as médias sejam iguais a zero.
Agora suponha que outro pesquisador teste, com os mesmos dados, a hipótese de que as médias populacionas sejam iguais a si. Para esta hipótese, a estatística seria (n/2)*(x1 – x2)^2, e o valor obtido na amostra é (100/2)*(0.14+0.16)^2= 4.5. A distribuição desta estatística sob a hipótese nula é uma qui-quadrado com 1 grau de liberdade, o que te dá um p-valor de 3%. Caso o pesquisador siga o padrão da literatura aplicada, como o p-valor é menor do que 5% (o tão esperado *), ele dirá que rejeita a hipótese de que as médias sejam iguais.
Mas, espere um momento. Ao concluir que as médias não são iguais, logicamente também se deve concluir que ambas não sejam iguais a zero! Com os mesmos dados, se forem testadas hipóteses diferentes, e se os resultados forem interpretados conforme faz a maior parte da literatura aplicada (que é uma interpretação bastante frágil), você chegará a conclusões aparentemente contraditórias!
Como o p-valor traz “mais evidência” contra a hipótese de que as médias seja iguais do que contra a hipótese de que ambas sejam iguais a zero, tendo em vista que se rejeitarmos a primeira, logicamente temos que rejeitar a segunda? O que está acontecendo?
Para entender melhor, lembremos o que é o p-valor. O p-valor calcula a probabilidade de a estatística de teste ser tão grande, ou maior, do que a estatística de teste observada. Intuitivamente, o p-valor tenta responder a seguinte pergunta: se eu adotasse esta discrepância observada como evidência suficiente para rejeitar a hipótese nula, quantas vezes este teste me levaria a erroneamente rejeitar esta hipótese quando ela é de fato verdadeira. Isto é, o p-valor leva em consideração em seu cálculo todos aqueles resultados amostrais que gerariam estatísticas tão extremas quanto a observada, que poderiam ter ocorrido mas não ocorreram.
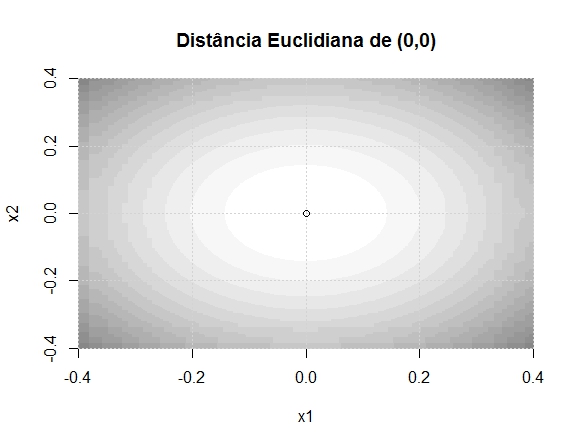
Repare como calculamos a estatística 1 e note o termo (x1^2+x2^2). Percebe-se que a estatística se torna mais extrema cada vez que o ponto (x1, x2) se distancia de (0,0) – em qualquer direção. Isto é, ela cresce com relação à distância euclidiana de (x1,x2) em relação ao ponto (0,0). Talvez isso seja mais fácil de entender com imagens. No gráfico abaixo, quanto mais escura a cor, maior é o valor da estatística de teste.
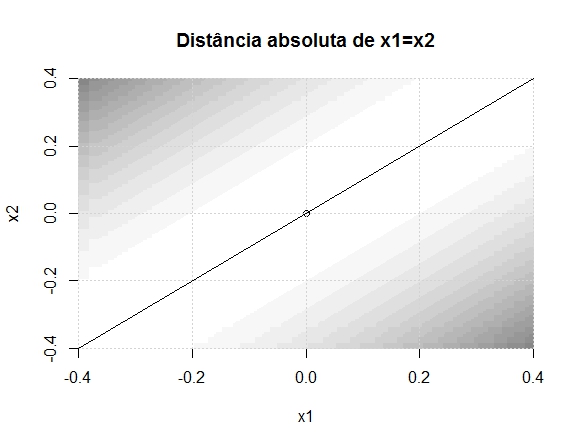
Já na estatística 2, perceba que o termo principal é (x1 – x2)^2, e o que se mede é a distância do ponto em relação à curva x1=x2. Isto é, a distância absoluta de x1 em relação a x2. Vejamos as curvas de nível. Note que ao longo da curva há diversas regiões em branco, mesmo quando distantes do ponto (0,0), pois o que a estatística mede é a distância entre os pontos x1 e x2 entre si.
Agora deve ficar mais fácil de entender o que está acontecendo. O p-valor calcula a probabilidade de encontrar uma estatística tão grande ou maior do que a observada. Ao calcular (x1 – x2)^2, todos os pontos que são distantes de (0,0), mas são próximos entre si, não geram estatísticas extremas. Como uma imagem vale mais do que mil palavras, façamos mais uma. No gráfico abaixo, os pontos pretos são todos aqueles cuja estatística de teste supera a estatística observada (0.14, -0.16). Já os pontos azuis e vermelhos são todos os pontos que tem uma estatística de teste maior do que a observada, medidos pela distância euclidiana em relação à reta x1=x2.
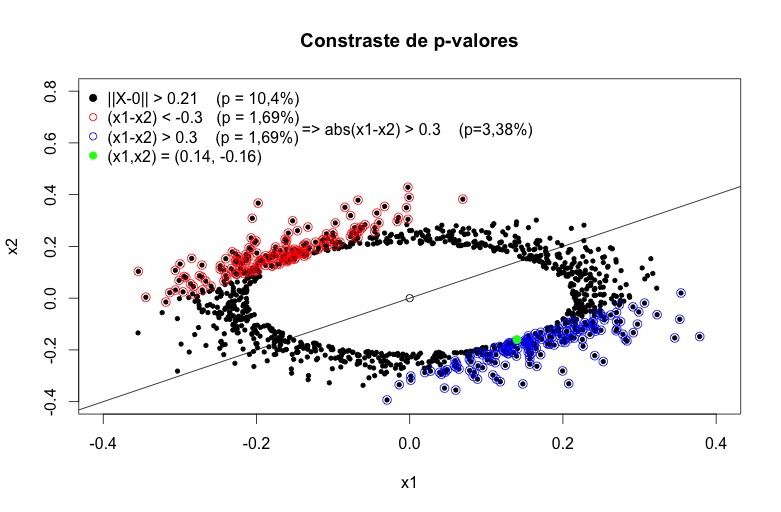 Note que vários pontos pretos que se encontram “longe” de (0,0) não são nem vermelhos nem azuis, pois estão “pertos” da reta x1=x2. Fica claro, portanto, porque o p-valor da segunda estatística é menor. Isso ocorre porque resultados extremos que discordariam bastante de (0,0) – como (0.2, 0.2) ou (0.3, 0.3) – não são considerados em seu cálculo. Note que é possível obter um p-valor ainda menor (1,6%) testanto a hipóse de que média 1 seja menor ou igual à média 2. E se a média 1 não é menor ou igual a média 2, isso implica que elas não são iguais a si, e que também não são ambas iguais a zero. É importante ter claro também que todas as estatísticas são derivadas pelo mesmo método – razão de verossimilhanças – e possuem propriedades ótimas, não são estatísticas geradas ad-hoc para provocar um resultado contra-intutivo.
Note que vários pontos pretos que se encontram “longe” de (0,0) não são nem vermelhos nem azuis, pois estão “pertos” da reta x1=x2. Fica claro, portanto, porque o p-valor da segunda estatística é menor. Isso ocorre porque resultados extremos que discordariam bastante de (0,0) – como (0.2, 0.2) ou (0.3, 0.3) – não são considerados em seu cálculo. Note que é possível obter um p-valor ainda menor (1,6%) testanto a hipóse de que média 1 seja menor ou igual à média 2. E se a média 1 não é menor ou igual a média 2, isso implica que elas não são iguais a si, e que também não são ambas iguais a zero. É importante ter claro também que todas as estatísticas são derivadas pelo mesmo método – razão de verossimilhanças – e possuem propriedades ótimas, não são estatísticas geradas ad-hoc para provocar um resultado contra-intutivo.
Para não alongar muito este post, frise-se que o que deve ser tirado como lição principal é que o p-valor não é uma medida absoluta de suporte à hipótese que está sendo testada. Mas como interpretar melhor os resultados acima? Caso você queira continuar no âmbito frequentista, algumas medidas seriam, por exemplo, não considerar literalmente as hipóteses nulas (isto é, não rejeitar ou aceitar uma hipótese precisa como x1=x2 ou x1=x2=0), avaliar que discrepâncias em relação à hipótese nula são ou não relevantes (do ponto de vista científico, e não estatístico) e conferir a função poder e intervalos de confiança para algumas alternativas de interesse. Trataremos disso mais a frente (caso vocês ainda não tenham enjoado do assunto!).
