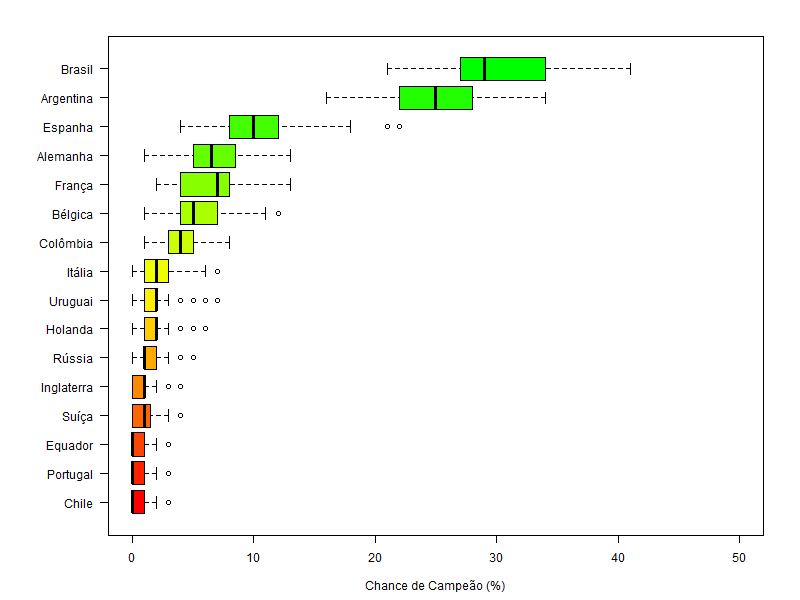
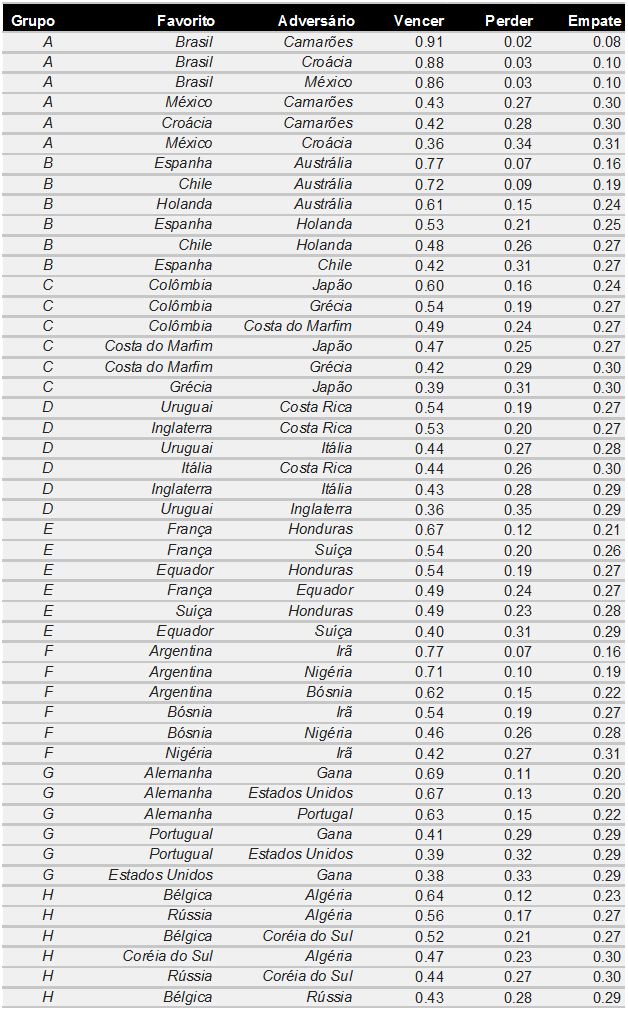
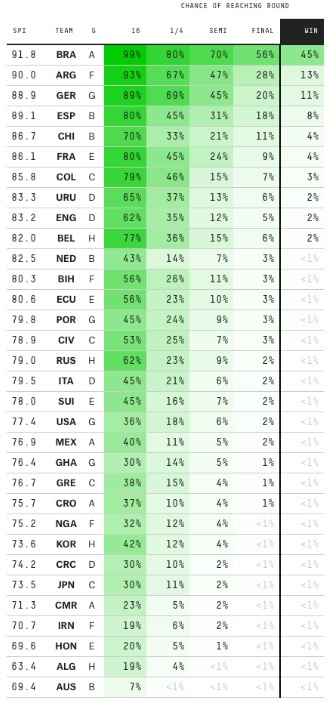
Depois do 7 x 1 da Alemanha contra o Brasil, houve algum rebuliço na mídia. Nate Silver se explicou: não é que a derrota do Brasil fosse algo imprevisível, afinal, estimou-se em 35% as chances de a Alemanha vencer a partida. Mais de uma em cada três vezes. Entretanto, o placar de 7 a 1 foi, de fato, estimado como muito improvável segundo o modelo – apenas 0.025%. Mas será que isso por si só é suficiente para rejeitarmos seus resultados? Não necessariamente. Lembre que modelos são falsos. Você não quer saber se eles representam fielmente a realidade, mas sim se são úteis. A dificuldade está em, justamente, saber onde esses modelos podem ser úteis, e onde podem ser enganosos.
Modelar resultados raros e extremos é muito complicado. Isso ilustra um ponto importante: não se exponha negativamente a Black Swans, pois a dificuldade (ou impossibilidade) de identificar tais eventos pode te expor a riscos muito maiores do que o que você imagina. Nassim Taleb é alguém que bate há algum tempo nesta tecla.
Todavia, o interessante neste caso é que os modelos para a copa, por preverem vitória ou derrota, não estavam negativamente expostos a eventos extremos deste tipo (o diferencial de gols). Suponha que a probabilidade estimada para o resultado de 7 a 1 para a alemanha fosse de 0.25% ao invés de 0.025%, ou seja, 10 vezes maior. Isso em quase nada alteraria a probabilidade de um time ou outro vencer. Em outras palavras, se você estiver apostando no resultado binário (vitória ou derrota), você não está exposto a um Black Swan deste tipo (poderia estar exposto a outros tipos, mas isso não vem ao caso agora).
Para ilustrar, comparemos uma distribuição normal (cauda bem comportada) com uma distribuição t de student com 2 graus de liberdade (cauda pesada). No gráfico abaixo temos a Normal em vermelho e a t de student em azul. Note que a probabilidade de X ser maior do que zero é praticamente 50% nas duas distribuições. Entretanto, a probabilidade de X ser maior do que 3.3 é mais de 80 vezes maior na distribuição t do que na Normal. Na verdade, a simulação da t resulta em pontos bastante extremos, como -100 ou 50 (resultados “impossíveis” numa normal(0,1)), e por isso o eixo X ficou tão grande. Isto é, para prever o resultado binário X>0 ou X<0, não há muita diferença nos dois modelos, a despeito de haver enormes diferenças em eventos mais extremos.

Dito isto, não é de se surpreender que, apesar de Nate Silver ter colocado o Brasil como favorito – e ter errado de maneira acachapante o resultado contra a Alemanha – ainda assim suas previsões (atualizadas) terminaram a copa com o menor erro quadrático médio. Ou, também, com o menor erro logarítmico. Essas são medidas próprias de escore para previsões probabilísticas.
O gráfico final do erro quadrático ficou da seguinte forma. Não coloco o logarítmico por ser praticamente igual:

E segue também o gráfico final comparando as probabilidade observadas com as previstas: