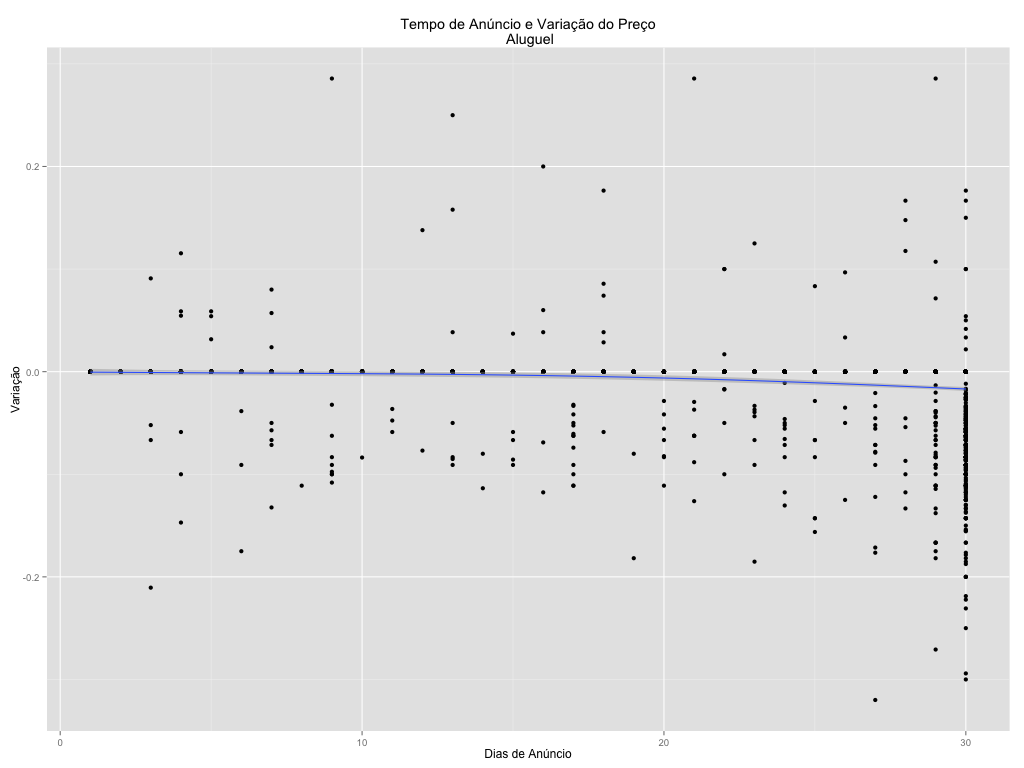
Recentemente conheci um site com uma iniciativa bem bacana chamado Onde Fui Roubado. Lá qualquer pessoa pode reportar um crime especificando local, hora, objetos roubados e inclusive fornecer um relato. Há mais de 16 mil registros para várias cidades do país, e resolvi fazer um webscraping para ver como são estes dados.
Especificamente para Brasília, infelizmente, existem apenas cerca de 200 registros. A maioria na Asa Sul, Asa Norte e Sudoeste, com mais de 100. A ideia aqui será montar um mapa de calor, ou de densidade, dos roubos no Plano Piloto.
Temos, entretanto, dois problemas que valem ser ressaltados: (i) a amostra é pequena; e, (ii) possivelmente viesada. Isto é, como o site ainda não parece ser muito conhecido, não necessariamente o público que está informando é representativo da população do local. Ainda assim, tendo em mente essas ressalvas, vamos brincar um pouco com a visualização dos dados!
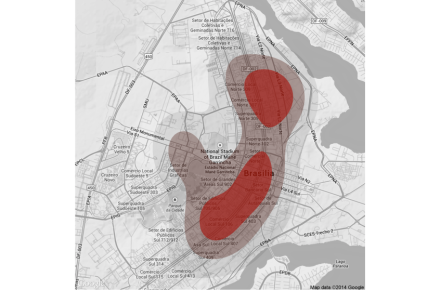
Primeiro, vejamos um mapa com todos os casos – note que, quanto mais vermelho, maior a concentração de roubos reportados na região. A maior parte dos registros foram na Asa Sul e Asa Norte. Na Asa Norte, em especial, a região próxima à UnB tem destaque. Lembre que talvez isto seja decorrência, por exemplo, de pessoas mais jovens conhecerem o site e reportarem mais casos.
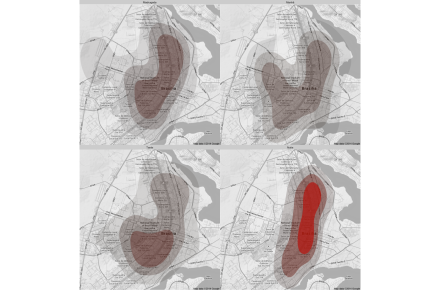
Vamos dividir agora o mapa por horário do roubo, entre manhã, tarde, noite e madrugada. A maior parte dos roubos registrados ocorreu durante a noite, com focos na Asa Norte e início da Asa Sul.
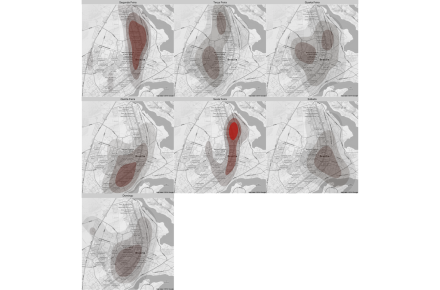
Vejamos, ainda, uma divisão por dias da semana. De maneira consistente com os mapas anteriores, aparece um foco nas sextas, na região próxima à UnB.
Poderíamos fazer um mapa cruzando dias da semana e hora, mas temos poucos dados para isso. A ideia aqui é mostrar como podem ser poderosas essas visualizações! Se a Secretaria de Segurança Pública liberar os microdados dos BO’s (se alguém tiver estes dados, por favor, entre em contato), seria possível montar mapas bem acurados. E imagine cruzá-los com as informações de imóveis – poderíamos medir o impacto da criminalidade nos preços imobiliários.
Por fim, reforço a divulgação do Onde Fui Roubado, é uma iniciativa louvável!
***
A quem interessar, seguem os códigos para a construção dos mapas. Os dados podem ser baixados aqui.
library(ggmap)
library(dplyr)
### carrega dados
dados <- readRDS("roubo2.rds")
### Pega mapa de Brasília
q<-qmap("estadio mane garrincha, Brasilia", zoom=13, color="bw")
### transformando data em POSIXlt e extraindo hora
dados$hora <- as.POSIXlt(dados$data)$hour
### selecionando a base de dados do plano piloto, criando semanas e horários
bsb <- filter(na.omit(dados), cidade=="Brasília/DF",
lon > -47.95218, lon < -47.84232,
lat > -15.83679, lat < -15.73107)%.%
mutate(semana = weekdays(data),
hora = cut(hora,
breaks=c(-1,6,12,18,25),
labels=c("Madrugada", "Manhã", "Tarde", "Noite")))
### reordenando os dias da semana
bsb$semana <- factor(bsb$semana, levels = c("segunda-feira", "terça-feira",
"quarta-feira", "quinta-feira",
"sexta-feira", "sábado", "domingo"))
### estrutura básica do gráfico
map <- q + stat_density2d(
aes(x = lon, y = lat, fill = ..level.., alpha = ..level..),
size = 2, bins = 4, data = bsb,
geom = "polygon")
### mapa geral
map + scale_fill_gradient(low = "black", high = "red", guide=FALSE)+
scale_alpha(guide=FALSE)
### mapa por dia da semana
map+scale_fill_gradient(low = "black", high = "red", guide=FALSE)+
facet_wrap(~ semana)+scale_alpha(guide=FALSE)
### mapa por horário
map+scale_fill_gradient(low = "black", high = "red", guide=FALSE)+
facet_wrap(~ hora) + scale_alpha(guide=FALSE)