Compartilharam, recentemente, uma análise das eleições presidenciais utilizando a lei de Benford. Para quem não conhece, a lei de Benford é bastante utilizada na detecção de fraudes em uma gama de circunstâncias, como demonstrações contábeis e, inclusive, eleições. Para entender um pouco mais sobre o assunto, leia aqui (Lei de Benford), aqui (Lei de Benford – por que ela surge?) ou aqui (benford.analysis 0.1).
A análise tomou os votos da Dilma por município e extraiu os primeiros dígitos das observações. Por exemplo, se em um dado município foram contabilizados 1.529 votos para a candidata, o primeiro dígito é 1. Já se o número tivesse sido 987, o primeiro dígito é 9. Segundo a lei de Benford, deveríamos observar cerca de 30,1% dos municípios começando com o dígito 1; em seguida, 17,6% dos municípios com a totalização dos votos iniciada pelo número 2. E assim sucessivamente, como no gráfico a seguir:

Se os números observados diferirem substancialmente do que é previsto pela lei, isso poderia ser um indício de manipulação dos dados ou de algum outro fato atípico. Mas, seria pertinente utilizar este instrumento para analisar fraudes em votos municipais? Para responder a essa pergunta, devemos responder, na verdade, outra: estes dados tenderiam a ter uma distribuição de Benford?
Em uma primeira aproximação, a resposta é sim. Dados de população municipal tendem a seguir a lei de Benford. Veja, por exemplo, a distribuição dos primeiros dígitos dos dados de população por município, no Brasil (estou utilizando o pacote de R benford.analysis; o gráfico em que você tem que prestar mais atenção é o primeiro, em que a linha pontilhada vermelha é o valor previsto e a barra azul é o valor observado):
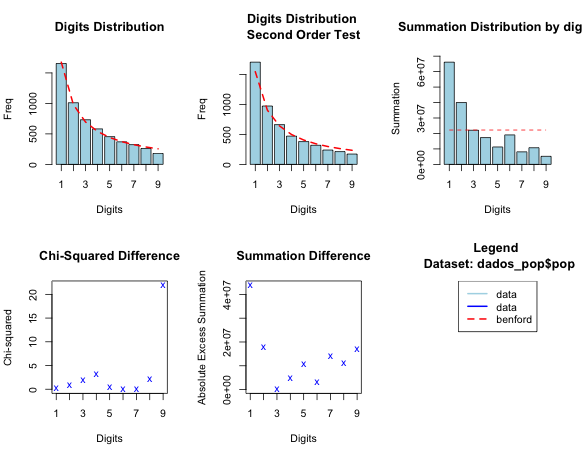
Ora, e como a população define o eleitorado, também é de se esperar que a lei tenda a aparecer nos números de eleitores. E, de fato, aparece:

E, por fim, como o eleitorado define o número de votos dos candidatos, também é natural se esperar que a distribuição apareça nesta situação. Em todos os casos vale lembrar que a lei de Benford nunca valerá exatamente, será apenas uma aproximação – testes estatísticos formais tem que ser interpretados com cautela e não são muito úteis, a principal função da lei é identificar possíveis focos de observações que mereçam análise/auditoria mais aprofundada.
Voltando, portanto, à análise mencionada anteriormente, foram calculados os desvios dos valores observados em relação aos valores esperados e, com isso, a estatística de chi-quadrado. Mas isso foi feito para cada estado da federação:
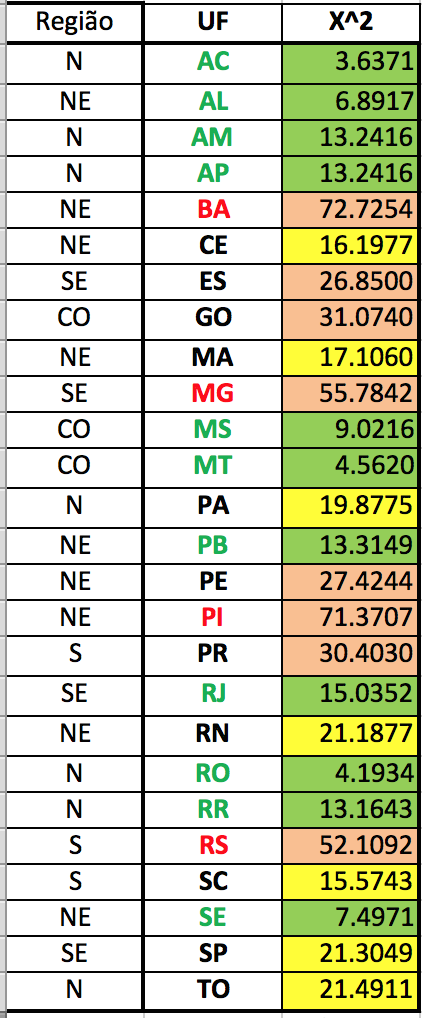
Note que alguns estados em que Dilma ganhou com bastante diferença como BA, PE ou PI tem grande discrepância em relação ao esperado pela lei, e isso causou certa estranheza. Por que logo estes estados?
Contudo, ocorre que, apesar de a distribuição do número de eleitores (ou da população) por municípios ter um bom ajuste quando usamos os dados do Brasil inteiro, isso não precisa valer para cada estado separadamente. E de fato não vale. Para deixar mais claro, vejamos, abaixo, o grau de ajuste do número de eleitores e da população para cada estado separadamente, e comparemos isso com o ajuste do número de votos:
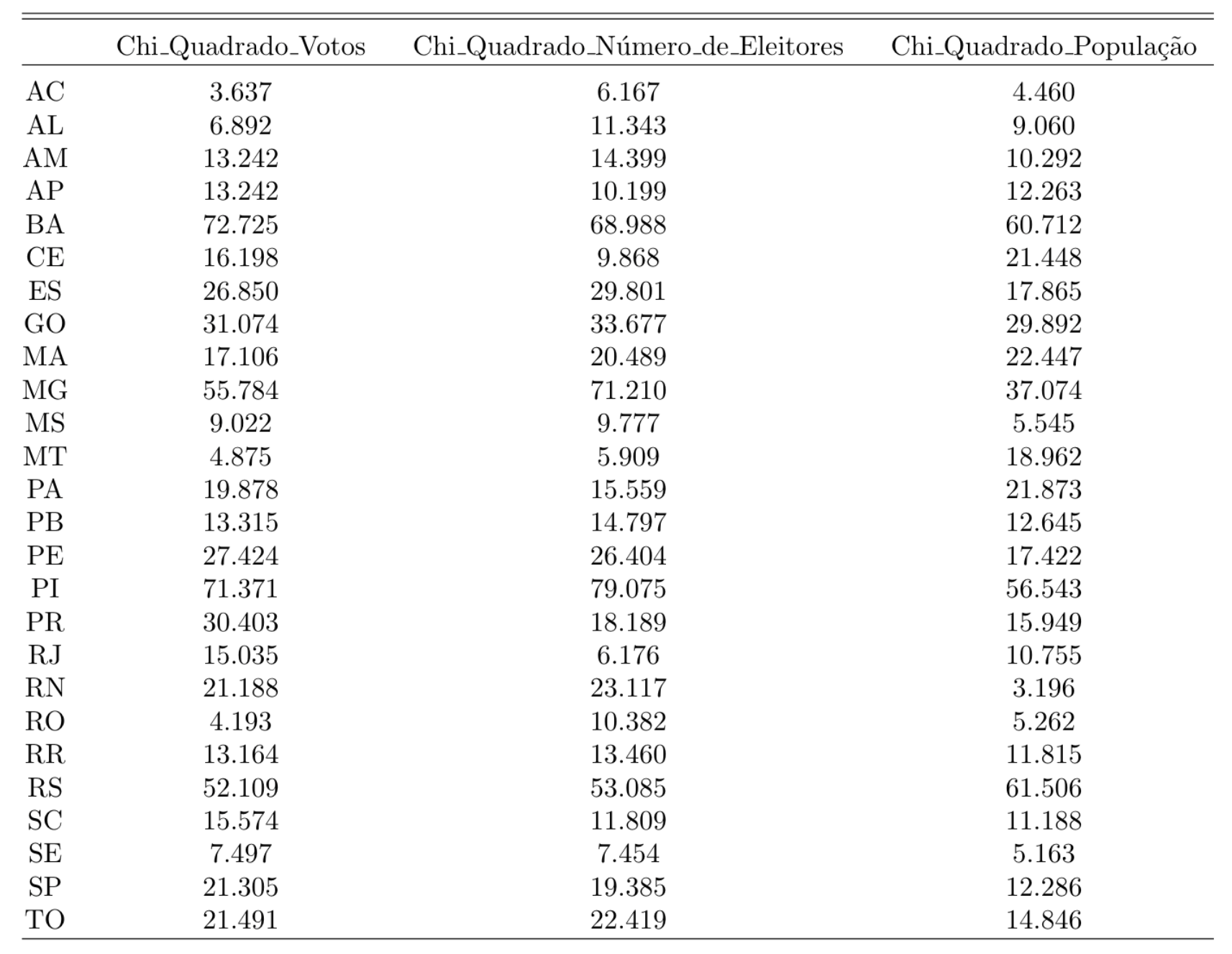
Note que a Bahia tem um chi-quadrado alto para o número de votos (72.725), mas também já tinha esse valor alto para o número de eleitores (68.988) e população (60.712). Observa-se a mesma coisa com MG, PE, PI e RS, por exemplo. Na verdade, a correlação dessas três séries é bem alta. A correlação entre o Qui-Quadrado do número de votos e o Qui-Quadrado do Número de Eleitores é de 0.968.

Deste modo, para o caso em questão, as grandes discrepâncias entre a lei de Benford e o número de votos em alguns estados parecem decorrer, em grande medida, do próprio desvio já presente nas distribuições da população e do eleitorado.
Há mais coisas que podem ser investigadas nos dados, e acho que esse é um bom exemplo para explorar a lei de Benford na prática. Por exemplo, a lei de Benford não estipula somente uma distribuição para o primeiro dígito, mas sim para todos os dígitos significativos, então você poderia analisar os dois primeiros dígitos (dada a quantidade de observações, não acredito que dê para analisar os três primeiros). Ou, ainda, verificar se a divisão por regiões mais amplas do país tenderiam a seguir a lei para o eleitorado (e para o número de votos).
Para replicar os cálculos acima, você pode utilizar estes dados aqui (link) e o script de R a seguir:
# instale o pacote e carregue os dados
install.packages("benford.analysis")
library(benford.analysis)
load("benford_eleicoes.rda")
#### Geral ####
bfd_votos <- benford(votos_dilma$votos, number.of.digits=1)
plot(bfd_votos)
bfd_pop <- benford(dados_pop$pop, number.of.digits=1)
plot(bfd_pop)
bfd_eleitorado <- benford(eleitorado$eleitores, number.of.digits=1)
plot(bfd_eleitorado)
#### Por Estado ####
# separando os dados
split_votos_uf <- split(votos_dilma, votos_dilma$uf)
split_pop_uf <- split(dados_pop, dados_pop$uf)
split_eleitorado_uf <- split(eleitorado, eleitorado$uf)
# benford dos votos
bfd_votos_uf <- lapply(split_votos_uf, function(x) benford(x$votos, number.of.digits=1))
chi_votos_uf <- sapply(bfd_votos_uf, function(x) chisq(x)$stat)
chi_votos_uf
# plote um estado de exemplo
plot(bfd_votos_uf[["BA"]])
# benford da população
bfd_pop_uf <- lapply(split_pop_uf, function(x) benford(x$pop, number.of.digits=1))
chi_pop_uf <- sapply(bfd_pop_uf, function(x) chisq(x)$stat)
chi_pop_uf
# plote um estado de exemplo
plot(bfd_pop_uf[["BA"]])
# benford do eleitorado
bfd_eleitorado_uf <- lapply(split_eleitorado_uf, function(x) benford(x$eleitores, number.of.digits=1))
chi_eleitorado_uf <- sapply(bfd_eleitorado_uf, function(x) chisq(x)$stat)
chi_eleitorado_uf
# plote um estado de exemplo
plot(bfd_eleitorado_uf[["BA"]])
# comparando as estatísticas chi-quadrado
compara <- data.frame( Chi_Quadrado_Votos = chi_votos_uf,
Chi_Quadrado_Número_de_Eleitores = chi_eleitorado_uf,
Chi_Quadrado_População = chi_pop_uf)
row.names(compara) <- gsub("([A-Z]{2}).*", "\\1", row.names(compara))
compara
# correlações
cor(compara)

E tem que ver ainda que ao fazer 27 testes separados, temos o problema de multiple testing, e sendo assim, a chance de um numero ficar acima do “valor critico standard” puramente por sorte não é baixa.
Tem que analisar essas evidencias “desagregadas” com muita calma…
CurtirCurtir
Sim, as múltiplas comparações também podem ser um problema.
CurtirCurtir
Interessante! Alguma hipótese do porque a lei de Benford não valeria para a distribuição da população, número de votos e eleitores em alguns estados?
CurtirCurtir
Raphael, não sei, teria que olhar mais a fundo. Se considerarmos a Lei de Benford como uma distribuição limite, às vezes pode ser simplesmente questão de termos poucas observações quando separamos por UF.
CurtirCurtir
Vale a pena ler os artigos de Walter Mebane sobre o assunto. http://www-personal.umich.edu/~wmebane/ A primeira coisa a fazer é analisar os dados por seção eleitoral. Os dados do 2o turno ainda não estão disponíveis no TSE mas os do 1o já.
CurtirCurtir
Eduardo, interessante! Mas, será que a lei valeria por seção eleitoral? Para a lei valer é preciso ter uma distribuição com cauda pesada, variando ordens de magnitude entre as observações. Por exemplo, cidades desde centenas até milhões de habitantes. Se o TSE divide as seções eleitorais em tamanhos mais ou menos homogêneos (não sei qual é a regra de divisão), aí a distribuição não vai seguir Benford.
CurtirCurtir
Eu pensei a mesma coisa que o Eduardo. O TSE já disponibilizou os dados por seção eleitoral para o 2o turno. Rodei a mesma análise por seção, mas o Carlos tem razão: as seções têm no máximo um pouco mais que 1000 eleitores, então elas acabam não seguindo a lei de Benford.
Eu não tenho nenhum conhecimento dessa literatura de fraude em eleições, mas eu estava imaginando: se eu fosse fraudar a eleição, eu faria de forma que não fosse grosseiramente perceptível. Uma forma seria alterar só alguns poucos votos em cada zona ou seção eleitoral. Supondo que isso seja possível (não sei se é), essa análise usando a lei de Benford não detectaria a fraude, detectaria?
CurtirCurtir
Por isso (em parte) é que o foco está no segundo digito. http://www-personal.umich.edu/~wmebane/fraud06.pdf
CurtirCurtir
De fato, ontem, depois de ter feito essa análise, eu conversei com a minha namorada que teve aula com o Walter Mebane em Fraude Eleitoral aqui em Michigan e ela disse que ele faz o teste com o segundo digito mesmo. Eu testei aqui e com os votos por município a lei de Benford ainda se aplica, mas por os votos seção continua não seguindo a lei.
CurtirCurtir
Raphael – tem tempo que eu li os trabalhos de Mebane. Mas tem algo lá sobre a lei se aplicar aos “precincts” (menores que nossas zonas eleitorais) mas não às máquinas individuais. (essencialmente nossas seções). Assunto complexo …
CurtirCurtir
Gostei muito da explicação deste post. Parabéns pela iniciativa em divulgar e explicar esta nobre Arte !
Analisando os dados dos dois candidatos apenas para o primeiro dígito os estados BA,PI, MG e RS voltam a se destacar, entretanto desta vez pela diferença entre os quiquadrados apresentados pelos dois candidatos.
Inclusive se procurarmos os três maiores quiquadrados apresentados teremos os estados BA, PI e RS. Outra coisa que me chamou atenção foi que ao somarmos os saldos de BA e PI para a candidata e subtrairmos o saldo do candidato no RS teremos um valor de 3.451.188 a favor da candidata, um número que é muito próximo do saldo final da candidata em todo território nacional (diferença de 8.775 votos). Mas isso deve ser apenas coincidência.
CurtirCurtir
Desculpe a minha ignorância estatística, mas tal indício funcionaria para o 1o turno das eleições presidenciais? Neste caso quem seriam as candidatas a avançar ao 2o turno???
CurtirCurtir
Outras comparações possíveis que ajudariam a contextualizar melhor a possibilidade de usar a LdB ou não neste caso seriam: (a) utilizar dados de outras eleições, e (b) verificar se os votos obtidos pelos candidatos a deputado federal, por exemplo, também segue LdB.
CurtirCurtir
Pingback: Retrospectiva: posts mais lidos de 2014 | Análise Real
Bom, fiz um teste com o primeiro e o segundo dígito envolvendo a quantidade de eleitores por município, ao invés de estado. Foi bem interessante, já que temo mais de 5700 números pra fazer a escolha.
Falta agora as estatísticas do TSE para eu fazer o mesmo com a quantidade de votos que cada candidato recebeu por município.
CurtirCurtir
Como assim, estou no ano de 2025 e o TSE e o STF ainda não censuraram este blog? Milagre!
CurtirCurtir
Os dados não estão mais disponíveis para realizar a replicação do código. Poderia enviar para o e-mail que informei?
CurtirCurtir
Caros amigos estatísticos, vocês estão planejando fazer este tipo de análise para as eleições de 2018 também?
Pergunto pois fiquei sabendo desse tema que muito me interessou através desse post: http://bit.ly/2E7IU0G
Seria muito interessante fazê-lo e dar ampla divulgação.
CurtirCurtir
Acho que vale a pena dar uma lida:
CurtirCurtir
Acho que vale pena dar uma lida:
https://g1.globo.com/fato-ou-fake/noticia/2018/10/06/mensagens-com-conteudo-fake-sobre-fraude-em-urnas-eletronicas-se-espalham-nas-redes.ghtml
CurtirCurtir