O pacote benford.analysis (versão 0.1) está disponível no CRAN e você já pode instalar no R com o comando:
install.packages("benford.analysis")
O objetivo do pacote é prover algumas funções que facilitem a validação de dados utilizando a Lei de Benford (para saber mais sobre a lei, veja aqui e aqui).
Validar como e para quê?
Um dos objetivos pode ser o auxilío na detecção de manipulações contábeis. Dados financeiros (como pagamentos) tendem a seguir a Lei de Benford e tentativas de manipulação podem acabar sendo identificadas.
Por exemplo, a lei 8.666/93 estabelece que o limite para se fazer uma licitação na modalidade convite é de R$80.000,00. Será que os valores de licitações seguiriam a Lei de Benford? Pode ser que sim. E, caso haja a tendência, uma tentativa de manipular artificialmente valores licitados para algo pouco abaixo de R$80 mil geraria um “excesso” de dígitos iniciais 7. Restaria verificar uma amostra desses registros para confirmar a existência ou não de manipulação indevida.
Outro objetivo pode ser acadêmico: a validação de dados de pesquisas e censos. Por exemplo, dados de população de municípios, ou dados de renda dos indivíduos tendem a ter distribuição conforme a lei de Benford. Assim, desvios dos valores observados em relação aos valores esperados podem ajudar a identificar e corrigir dados anômalos, melhorando a qualidade da estatística.
Vejamos rapidamente alguns exemplos das funções básicas do pacote.
O benford.analysis tem 6 bases de dados reais, retiradas do livro do Mark Nigrini , para ilustrar as análises. Aqui vamos utilizar 189.470 registros de pagamentos de uma empresa no ano de 2010. Os valores vão desde lançamentos negativos (estornos) até valores na ordem de milhões de dólares.
, para ilustrar as análises. Aqui vamos utilizar 189.470 registros de pagamentos de uma empresa no ano de 2010. Os valores vão desde lançamentos negativos (estornos) até valores na ordem de milhões de dólares.
Primeiramente, precisamos carregar o pacote (se você já o tiver instalado) e em seguida carregar os dados de exemplo:
library(benford.analysis) #carrega pacote
data(corporate.payment) #carrega dados
Para analisar os dados contra a lei de benford, basta aplicar a função benford nos valores que, no nosso caso, estão na coluna ‘Amount’.
bfd.cp <- benford(corporate.payment$Amount)
Com o comando acima criamos um objeto chamado “bfd.cp” contendo os resultados da análise para os dois primeiros dígitos dos lançamentos positivos, que é o padrão. Caso queira, você também pode mudar quantos digitos deseja analisar, ou se quer analisar os dados negativos e positivos juntos, entre outras opções. Para mais detalhes, veja a ajuda da função:
?benford
Com a análise feita, vejamos os principais gráficos com o comando:
plot(bfd.cp)
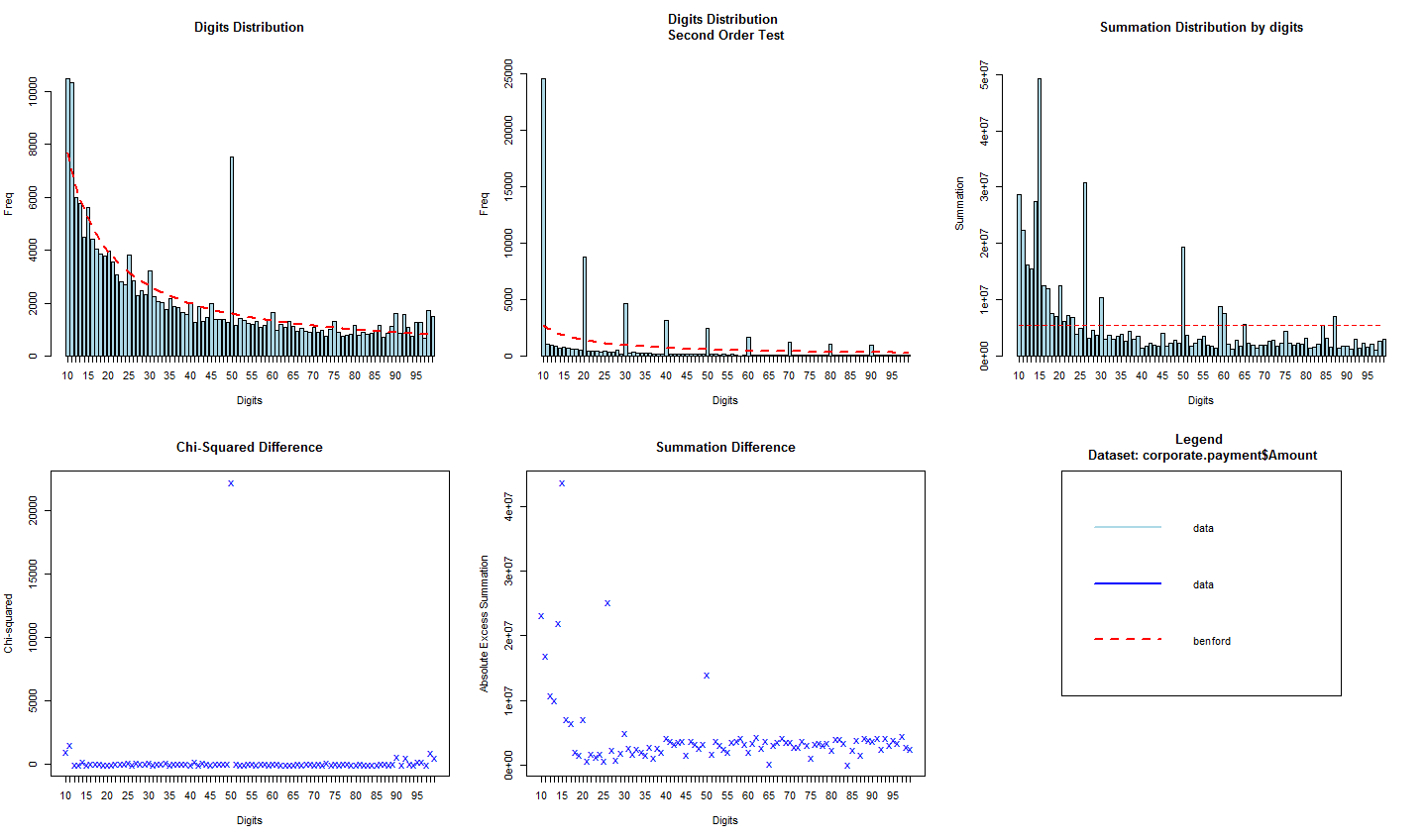
Os gráficos resultantes se encontram abaixo. Os dados da empresa estão em azul e os valores esperados pela lei de benford em vermelho.
O primeiro gráfico diz respeito à contagem de observações com relação aos seus dois primeiros dígitos, comparando-a com o valor esperado pela Lei de Benford. Percebe-se que os dados da empresa se ajustam à Lei, mas, também, que há um salto claro no dígito 50!
O segundo gráfico é análogo ao primeiro, mas faz esta contagem para a diferença dos dados ordenados. Como nossos dados são discretos, este saltos em 10, 20, 30, são naturais e não devem ser encarados como algo suspeito. Por fim, o terceiro gráfico tem um objetivo diferente e, em geral, você também não deve esperar encontrar um bom ajuste dos dados à reta vermelha, principalmente com dados de cauda pesada. Ali se encontra a soma dos valores das observações agrupadas por primeiros dígitos e a intenção é identificar grupos de valores influentes (que, se estiverem errados, podem afetar bastante uma estatística).
Vejamos agora os principais resultados da análise com o comando
print(bfd.cp)
ou somente
bfd.cp
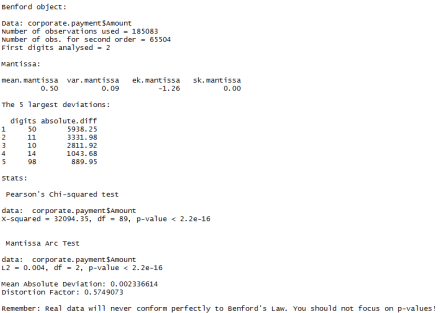
Primeiramente são mostrados dados gerais da análise, como o nome da base de dados, o número de observações e a quantidade de primeiros dígitos analisados.
Logo em seguida têm-se as principais estatísticas da mantissa do log das observações. Se um conjunto de dados segue a lei de benford esses valores deveriam ser próximos de:
- média: 0.5;
- variância: 1/12 (0.08333…);
- curtose: 1.2;
- assimetria: 0.
Que são, de fato, similares aos dados de pagamento da empresa, confirmando a tendência.
Após isso, temos um ranking com os 5 maiores desvios, que é o que mais nos interessa aqui. Veja que o primeiro grupo é o dos números que começam com o dígito 50, como estava claro no gráfico, e o segundo grupo é o dos números que começam com 11. Esses registros são bons candidatos para uma análise mais minuciosa.
Por fim, temos um conjunto de estatísticas de grau de ajuste – que não irei detalhar agora para não prolongar muito este post. Tomemos como exemplo o teste de Pearson, que é bem conhecido. Veja que o p-valor do qui-quadrado é praticamente zero, sinalizando um desvio em relação ao esperado. Mas, como já dissemos várias vezes neste blog, o mais importante não é saber se os dados seguem ou não a lei de benford exatamente. Para isso você não precisaria sequer testá-los. O mais importante é verificar qual o tamanho do desvio e a sua importância prática. Assim, há um pequeno aviso ao final: Real data will never conform perfectly to Benford’s Law. You should not focus on p-values!
Voltando, portanto, à identificação dos desvios, você pode pegar os conjuntos dos dados “suspeitos” para análise com a função getSuspects.
suspeitos <- getSuspects(bfd.cp, corporate.payment)
Isto irá gerar uma tabela com os dados dos 2 grupos de dígitos com maior discrepância (pela diferença absoluta), conforme ilustrado abaixo. Veja que são exatamente os dados que começam com 50 ou 11. Você pode personalizar qual a métrica de discrepância utilizar e também quantos grupos analisar. Para mais detalhes veja a ajuda da função:
?getSuspects
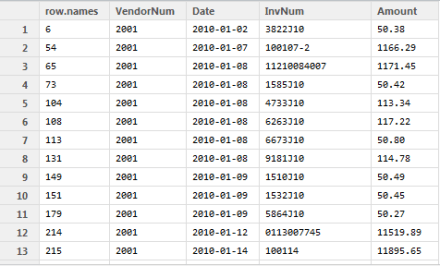
Note que nossa base de dados é de mais de 189 mil observações. Verificar todos os dados seria infactível. Poderíamos analisar uma amostra aleatória desses dados. Mas, não necessariamente isso seria eficiente. Veja, assim, que a análise de benford, com apenas os dois primeiros dígitos, nos deu um grupo de dados suspeitos com menos de 10% das observações, permitindo um foco mais restrito e talvez mais efetivo para análise.
Há outras funcionalidades no pacote e na ajuda há exemplos com dados reais. O pacote é bem simples, o intuito é fornecer um mínimo de funções que automatize os procedimentos, facilite a vida e minimize a quantidade de caracteres digitados de quem queira fazer a análise. Algumas funcionalidades que serão adicionadas no futuro são: melhoria na parte gráfica com o Lattice, inclusão de comparação dos dados com a lognormal e inclusão de mais dados de exemplo.
Se encotrar algum bug, tiver alguma dúvida ou se quiser deixar alguma sugestão, comente aqui!
PS: com relação às sugestões, tanto o R quanto este pacote são livres e com código aberto. Então, sinta-se à vontade não somente para sugerir, mas principalmente para escrever novas funções e funcionalidades!