Para quem tiver curiosidade, segue vídeo com breve explicação do Diretor de Fiscalização Anthero Meirelles sobre como o Banco Central do Brasil mapeia exposições e riscos de contágio da Operação Lava Jato:
Estatística
Economia e Análise de Redes
Para quem estava na dúvida sobre como começar, segue uma lista bacana com um livro, um curso no Coursera e 4 apresentações. Além disso, para não ficar só na teoria, lembre de aprender a usar o igraph no R (livro aqui e slides aqui).
- O livro do Matthew O. Jackson de Stanford: Social and Economic Networks;
- O curso do Jacskon no Coursera: Redes Sociais e Econômicas: Modelos e Análises;
- As apresentações do Jackson e do Acemoglu no NBER Summer Institute (vídeos e pdfs abaixo, link do NBER aqui).
Matthew O. Jackson, Stanford University
Social and Economic Networks: Backgound
***
Daron Acemoglu, MIT
Networks: Games over Networks and Peer Effects
***
Matthew O. Jackson, Stanford University
Diffusion, Identification, Network Formation
Uma introdução visual ao aprendizado de máquinas (Machine Learning)

Alguns slides do useR! 2015 já estão disponíveis online
Peixes, meias e simulações: uma introdução intuitiva (e divertida) à estatística bayesiana
Como tinha dito anteriormente, gostei muito do tutorial do Rasmus no useR! 2105 e estava apenas esperando ele publicar online para divulgar por aqui.
Rasmus resolveu introduzir estatística Bayesiana com simulações, de uma forma bem intuitiva, e acho que funcionou muito bem – pretendo descaradamente roubar adotar essa estratégia para cursos introdutórios. Você pode baixar o material aqui.
Além do tutorial, outra apresentação divertida do Rasmus foi o uso de estatística bayesiana para resolver um problema, de certo modo, trivial, mas também bastante didático: se todas as 11 primeiras meias que você tirou de um cesto de roupas não fazem par, qual o provável total de meias no cesto? Ficou curioso, dê uma conferida no material (acompanhe escrevendo os códigos)!

Statistical Analysis of Network Data and Testing R Code
Alguns materiais dos tutoriais de ontem no useR!2015:
- Gábor Csardi sobre análise de redes com o igraph: slides aqui;
- Richard Cotton sobre testes de código no R: material aqui.
O Rasmus também fez um tutorial bem didático de introdução à estatística bayesiana, mas o material ainda não está disponível. Assim que estiver publico aqui.
Data Colada!
Fazia algum tempo que não descobria um blog tão bom quanto o Data Colada!
Em especial destaco esse post que discute a falha na replicação de um estudo famoso sobre posições corporais e níveis de testosterona e cortisol (o vídeo do TED sobre o estudo tem mais de 26 milhões de exibições):

Detalhe que ao final do post há comentários dos autores tanto do artigo original, quanto da réplica. E o post também discute o uso de curvas de p-valor para esse caso (há um web-app para construir as curvas de p-valor). Muito bacana.
useR! 2015
Neste ano, o useR! será na Dinamarca, na cidade de Aalborg e estarei lá. A lista de tutoriais está muito boa e aparentemente já temos mais de 400 participantes registrados! 
Prêmios para pesquisas abertas, transparentes e reproduzíveis!
A Berkeley Initiative for Transparency in the Social Sciences (BITSS) anunciou ontem a criação dos prêmios Leamer-Rosenthal por uma ciência social aberta (The Leamer-Rosenthal Prizes for Open Social Science).
Os prêmios tomam os nomes de Edward Leamer – de quem já falamos aqui no blog – e Robert Rosenthal. Ambos trataram de problemas sérios na pesquisa acadêmica como a tendência de publicar/buscar “resultados significantes” – muitas vezes genuinamente confundindo sua função – ou a tendência de ignorar a sensibilidade das próprias estimativas. Edward Leamer, em particular, trata extensivamente de uma prática bastante comum entre pesquisadores: a de experimentar vários modelos diferentes, até encontrar um que “pareça publicável”, para depois apresentar apenas aquele resultado como se fosse o único modelo testado.
Serão distribuídos de 6 a 8 prêmios de 10.000 a 15.000 dólares para pesquisadores em ciências sociais (como Economia, Psicologia e Ciências Políticas) que tenham feito trabalhos de transparência exemplar, ferramentas para melhorar o rigor das ciências sociais, ou para professores que tenham causado impacto no ensino e difusão de boas práticas de pesquisa.
Mais especificamente sobre as pesquisas, serão premiadas aquelas que busquem, entre outro pontos: (i) apresentar pré-registro, cálculo de poder do teste e do tamanho amostral (ainda é raro); (iii) ter os dados e o código para replicação disponíveis e bem documentados (lembrem do caso Reinhart-Rogoff); (iv) disponibilizar os materiais originais – como os questionários de pesquisa – para escrutínio público (lembrem do caso Stapel); (v) apresentação adequada e detalhada dos métodos e resultados.
Ou seja, esta é uma iniciativa que busca premiar bons processos! Acredito que tenha vindo em boa hora, juntando-se a diversas outras críticas sistemáticas que têm sido feitas ao atual estado dos métodos quantitativos nas ciências sociais aplicadas.
O prazo para inscrição é até 13 de setembro. Para você que está fazendo uma pesquisa aberta, reproduzível e cuidadosa, eis uma boa chance de ser reconhecido sem ter que se submeter à busca por temas de manchete de jornal.
Quando confiar nas suas previsões?
Quando você deve confiar em suas previsões? Como um amigo meu já disse, a resposta para essa questão é fácil: nunca (ou quase nunca).
Mas, brincadeiras à parte, para este post fazer sentido, vou reformular a pergunta: quando você deve desconfiar ainda mais das previsões do seu modelo?
Há várias situações em que isso ocorre, ilustremos aqui uma delas.
***
Imagine que você tenha as seguintes observações de x e y.
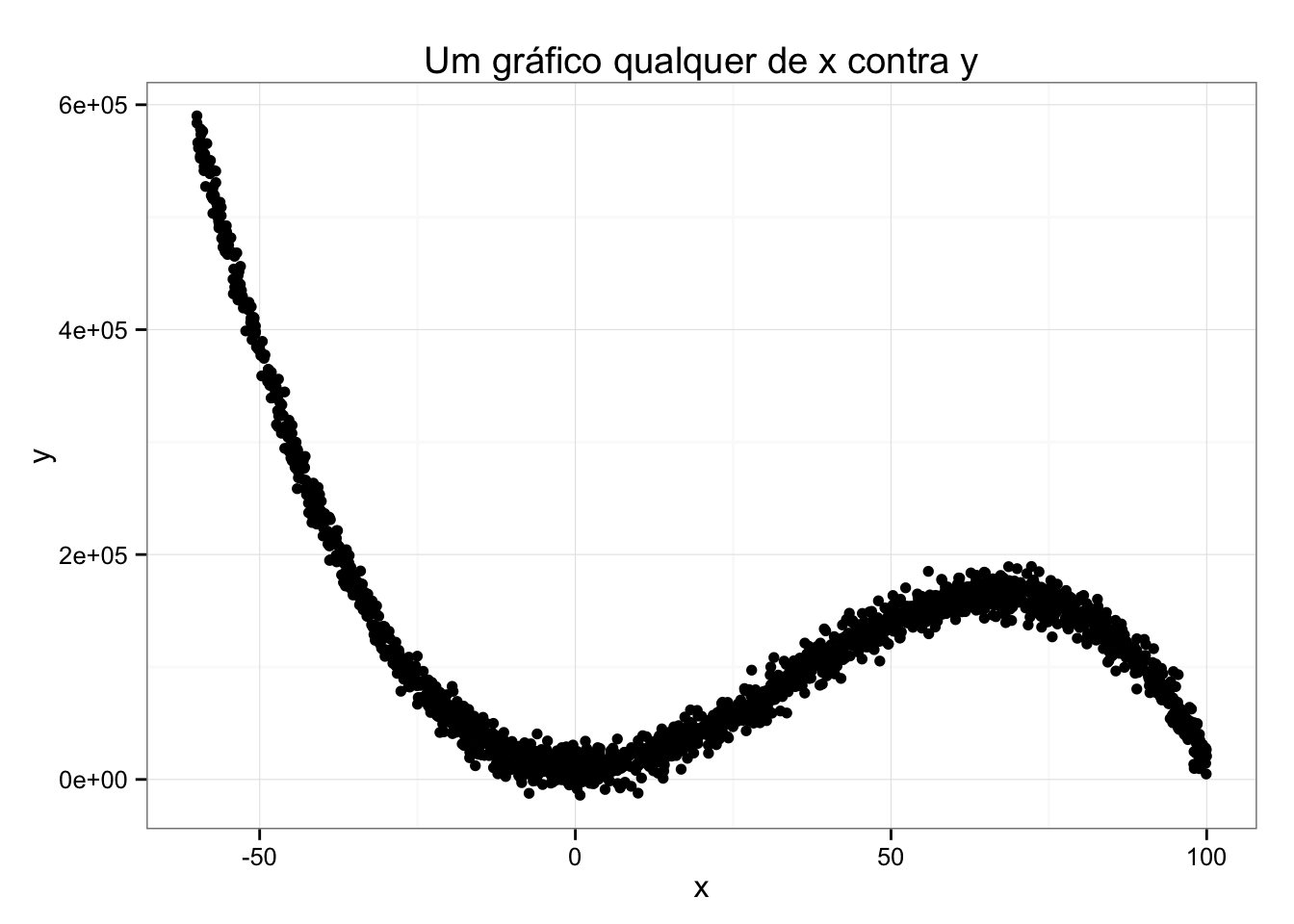
Para modelar os dados acima, vamos usar uma técnica de machine learning chamada Suport Vector Machine com um núcleo radial. Se você nunca ouviu falar disso, você pode pensar na técnica, basicamente, como uma forma genérica de aproximar funções.
Será que nosso modelo vai fazer um bom trabalho?
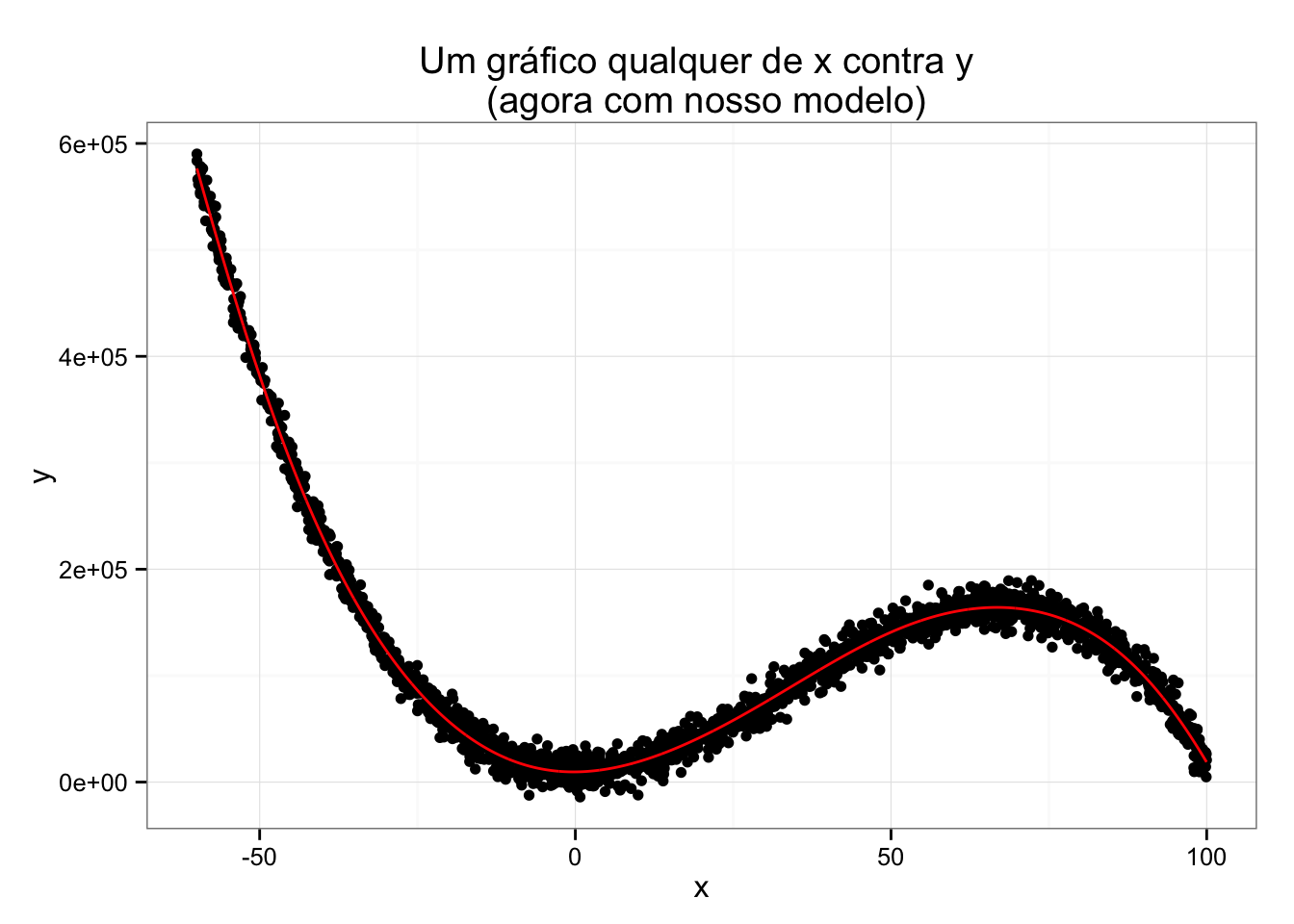
Pelo gráfico, é fácil ver que nossa aproximação ficou bem ajustada! Para ser mais exato, temos um R2 de 0.992 estimado por cross validation (que é uma estimativa do ajuste fora da amostra – e é isso o que importa, você não quer saber o quão bem você fez overfitting dos dados!).
Agora suponha que tenhamos algumas observações novas, isto é, observações nunca vistas antes. Só que essas observações novas serão de dois “tipos”, que aqui criativamente chamaremos de tipo 1 e tipo 2. Enquanto a primeira está dentro de um intervalo de x que observamos ao “treinar” nosso modelo, a segunda está em intervalos muito diferentes.
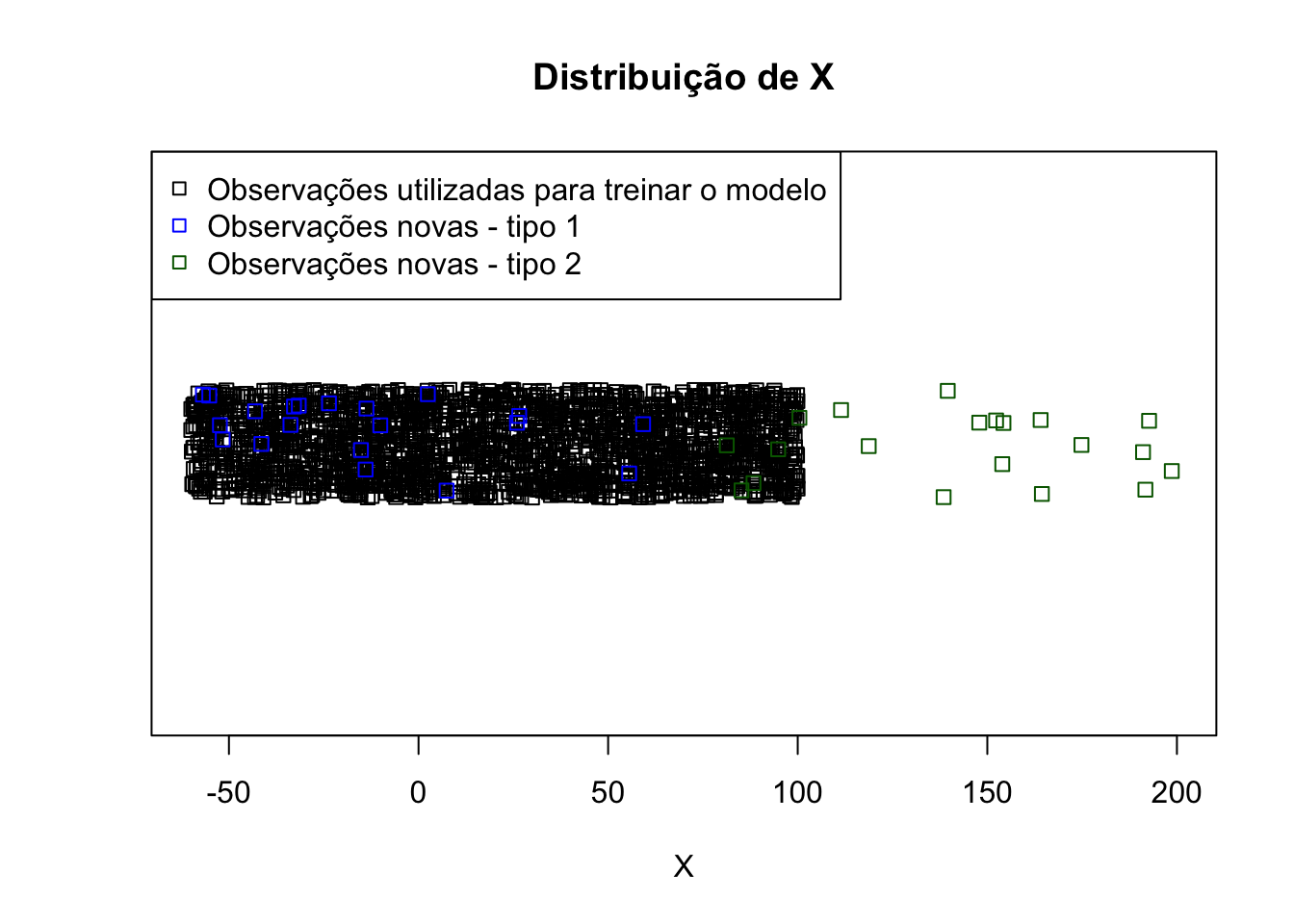
Qual tipo de observação você acha que teremos mais dificuldades de prever, a de tipo 1 ou tipo 2? Você já deve ter percebido onde queremos chegar.
Vejamos, portanto, como nosso modelo se sai agora:
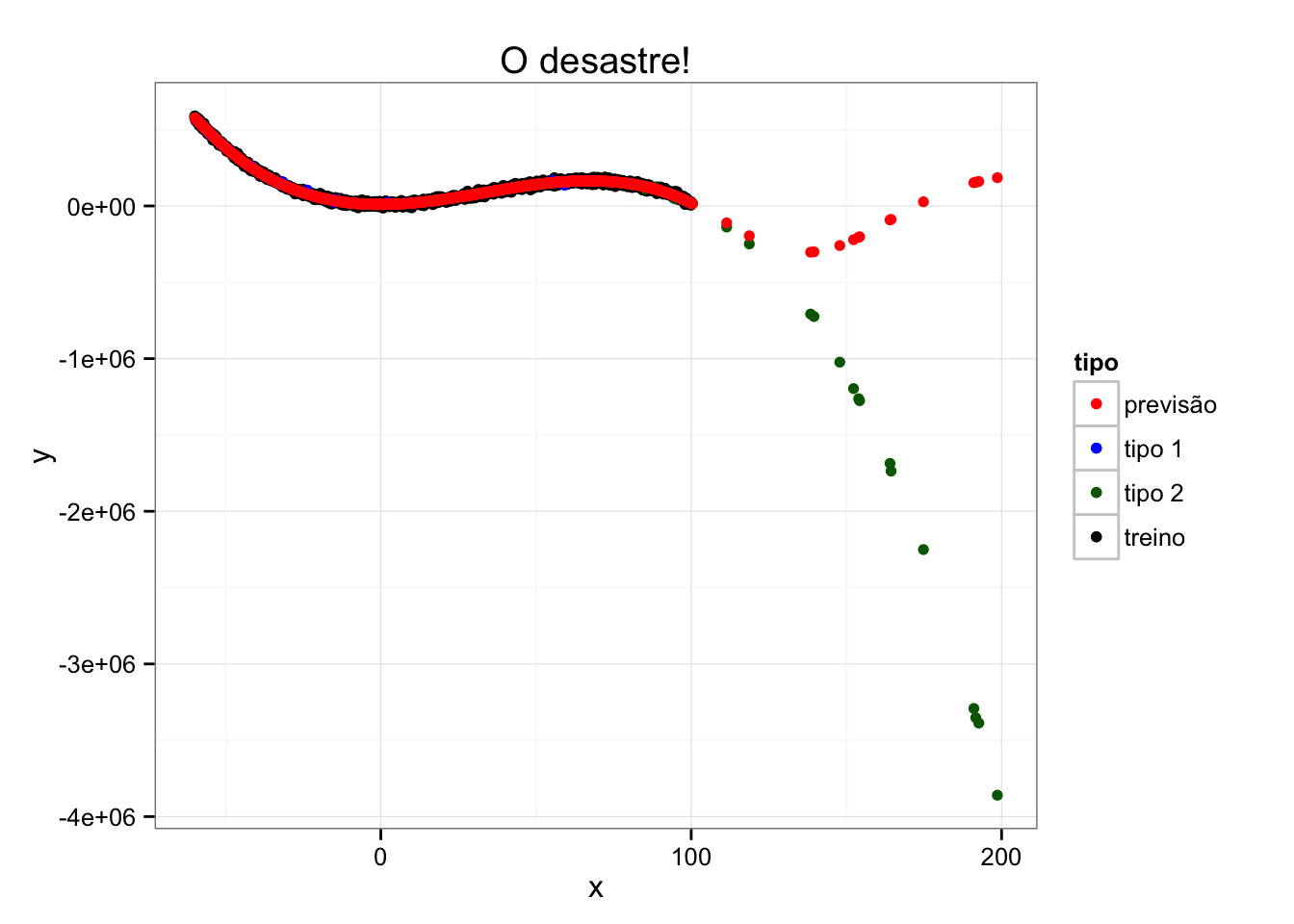
Note que nas observações “similares” (tipo 1) o modelo foi excelente, mas nas observações “diferentes” (tipo 2) nós erramos – e erramos muito. Este é um problema de extrapolação.
Neste caso, unidimensional, foi fácil perceber que uma parte dos dados que gostaríamos de prever era bastante diferente dos dados que usamos para modelar. Mas, na vida real, essa distinção pode se tornar bastante difícil. Uma complicação simples é termos mais variáveis. Imagine um caso com mais de 20 variáveis explicativas – note que já não seria trivial determinar se novas observações são similares ou não às observadas!
Quer aprofundar mais um pouco no assunto? Há uma discussão legal no livro do Max Kuhn, que já mencionamos aqui no blog.
