Enquanto Breaking Bad não volta, comecei a assistir ao seriado Numb3rs, cujo enredo trata do uso da matemática e da estatística na solução de crimes. Confesso que, a princípio, estava receoso. Na maior parte das vezes, filmes e seriados que tratam desses temas costumam, ou mistificar a matemática, ou conter erros crassos.
Todavia, o primeiro episódio da série abordou uma equação para tentar identificar a provável residência de um criminoso, sendo que: (i) os diálogos dos personagens e as explicações faziam sentido; e, algo mais surpreendente, (ii) as equações de background, apesar de não explicadas, pareciam fazer sentido. Desconfiei. Será que era baseado em um caso real?
E era. Bastou pesquisar um pouco no Google para encontrar a história do policial que virou criminologista, Kim Rossmo, em que o episódio foi baseado. E inclusive, encontrar também um livro para leigos, de leitura agradável, que aborda alguns dos temas de matemática por trás do seriado: The Numbers behind Numb3rs.
A primeira equação que Rossmo criou tinha a seguinte cara:
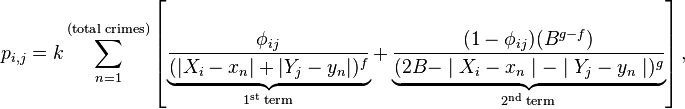
A intuição por trás da equação pode ser resumida desta forma: o criminoso não gosta de cometer crimes perto da própria residência, pois isso tornaria muito fácil sua identificação; assim, dentro de uma certa zona B, a probabilidade de o criminoso residir em um certo local é menor quanto mais próximo este estiver do crime (esse é o segundo termo da equação). Entretanto, a partir de certo ponto, começa a ser custoso ao criminoso ir mais longe para cometer o crime – assim, a partir dali, a situação se inverte, e locais longe do crime passam a ser menos prováveis (esse é o primeiro termo da equação). Em outras palavras, você tenta calcular a probabilidade de um criminoso morar na coordenada (Xi , Xj), com base na distância desta com as demais coordenadas dos crimes (xn, yn), levando em conta o fato de a residência estar ou não em B. Os parâmetros da equação são estimados de modo a otimizar o modelo com base nos dados de casos passados.
Por mais simples que seja, a equação funcionou muito bem e Kim Rossmo prosseguiu com seus estudos em criminologia. Evidentemente que, como em qualquer modelo, há casos em que a equação falha miseravelmente, como em situações em que os criminosos mudam de residência o tempo inteiro – mas isso não é um problema da equação em si, pois o trabalho de quem a utiliza é justamente identificar se a situação é, ou não, adequada para tanto. Acho que este exemplo ilustra muito bem como sacadas simples e bem aplicadas podem ser muito poderosas!
PS: O tema me interessou bastante e o livro de Rossmo, Geographic Profiling, entrou para a (crescente) wishlist da Amazon.





