Segundo as contas nacionais trimestrais do IBGE, o PIB brasileiro no terceiro trimestre de 2012, a preços constantes de 1995, foi de R$ 292.011.667.484,06. Isto resultou em uma variação real de 0,8652892558907% em relação ao mesmo período do ano anterior.
Qual a acurácia destes números? Ninguém em sã consciência acreditaria que os últimos seis centavos são exatos ou precisos. Poucos também apostariam grande soma com relação à exatidão dos quatrocentos e oitenta e quatro reais. É bem possível que existam erros na ordem dos milhões; e, quem sabe, dos bilhões. Mas não sabemos quanto.
Diferentemente de pesquisas eminentemente amostrais (como a PME, por exemplo), dados como o PIB, que envolvem a agregação de diversos valores, com metodologias bastante diferentes, não costumam ser acompanhados de uma medida quantitativa de erro. Isto ocorre porque são consultadas várias fontes de informação para se gerar a estimativa do PIB: governamentais, pesquisas de campo amostrais, pesquisas quase-censitárias, formulários administrativos, extrapolações, interpolações, entre outros instrumentos. Cada uma dessas fontes está sujeita a diversos vieses, erros amostrais e não-amostrais, sendo bastante difícil chegar a uma medida quantitativa da incerteza em relação ao número.
Antes que me entendam mal, vale ressaltar: não estou criticando o IBGE, que atualmente é respeitado nacionalmente e internacionalmente por seus dados, principalmente se compararmos com os dados da Argentina os dados de outros países.
A questão é que o erro existe e isso é natural. A mensuração é uma atividade fundamental na ciência*, mas junto de toda mensuração há incerteza, bem como um trade-off entre custo e acurácia. Definir o grau de exatidão e precisão (e que tipo de exatidão e precisão**) a se alcançar depende de saber tanto para quê o dado será utilizado, quanto o custo de torná-lo mais acurado. Além disso, uma vez coletado o dado, saber a incerteza presente no número é, às vezes, quase tão importante quanto saber o próprio número, posto que exercício fundamental para – como diria Morgenstern – podermos distinguir “entre o que achamos que sabemos e o que de fato sabemos ou o que de fato podemos saber” com esses dados .
Entretanto, ao se observar a mídia e, inclusive, trabalhos acadêmicos, a impressão que se tem é a de que muitos dos números econômicos divulgados não são vistos como estimativas, mas como valores reais, absolutos. Muitas vezes se toma o número pelo seu valor de face. E, para a ciência econômica, isso pode ser um grande problema.
Para não ficar em uma discussão etérea, vejamos alguns exemplos.
Primeiro – a Pesquisa Mensal de Emprego (PME), que divulga uma medida de erro. Este caso ilustra como esta medida pode ser importante para se interpretar o número. No boxe do relatório de inflação de dezembro de 2012, há uma discussão sobre a aparente contradição entre os cenários sugeridos pelos dados da PME e pelos dados do Caged para o mercado de trabalho. Um dos pontos relacionados no texto, para conciliar os cenários das duas pesquisas, é o erro amostral, que evidencia o cuidado que tem de ser tomado ao interpretar as variações mês a mês da PME. Por exemplo, em outubro de 2012, o coeficiente de variação da pesquisa foi de 0,7%; assim, uma variação nos dados, suponha, de 0,6%, é consistente tanto com um crescimento robusto do emprego (uma taxa anualizada de 7,8%), quanto com uma variação natural na amostra.
Segundo, um exemplo anedótico – o caso dos livros que pesam 0Kg. Este é um exemplo propositalmente absurdo e que, por isso mesmo, torna o problema da falta de informação sobre o erro auto-evidente. Suponha que, além dos livros em que a balança acusou o peso de 0Kg, tenhamos uma terceira medida com peso de 2Kg. Tomando os dados por seu valor de face, o peso total dos livros seria, aritmeticamente, 0Kg + 0Kg + 2Kg= 2Kg. O número final é manifestamente errado, pois não sabemos a ordem de grandeza que o instrumento de mensuração (a balança) consegue identificar. A partir do momento em que se sabe que a balança é errática para pesos menores do que 2Kg, você percebe que este dado não serve para distinguir entre um peso total de 2Kg e um peso total de 6Kg. Entretanto serviria caso você quisesse saber se os livros pesam menos do que 20Kg. Veja, estamos distinguindo “entre o que achamos que sabemos e o que de fato sabemos ou o que de fato podemos saber” com esses dados.
Terceiro, talvez um caso de erro proposital – os dados do Indec sugerem que o crescimento argentino, desde 2002, apresenta taxa de cerca de 7,7% ao ano. Este dado, entretanto, pode servir para julgar a eficácia das políticas econômicas dos hermanos? Alexandre Schwartsman sugere que não, mostrando inconsistência considerável entre os dados do PIB e os dados de geração de energia da Argentina. Inclusive, dados de preços coletados on-line sugerem que também os índices de preços oficiais parecem ter erro muito grande para qualquer inferência.
Os exemplos acima ilustram como os dados são matéria prima importante para a economia, e também mostram que ter uma medida do erro inerente a esses dados nos ajuda a entender o que eles podem e o que eles não podem responder. Com esta preocupação em mente, comecei a procurar trabalhos sobre o assunto, e tive contato com o livro de Morgenstern “On the accuracy of economics observations”. Este trabalho, cuja segunda e última revisão é de 1963, foi o único que encontrei que discute extensivamente os problemas inerentes a muitas variáveis (macro)econômicas (caso alguém tenha conhecimento de algo com este fôlego e mais recente, favor indicar).
O trabalho passa por discutir a natureza dos dados econômicos não experimentais, os diversos tipos de erro naturalmente esperados, e ainda trata de vários exemplos nas mais diversas áreas (comércio exterior, índices de preços, emprego, PIB). Como este post já esta enorme, vou apenas mencionar um exemplo de contas nacionais, trazido por Morgenstern.
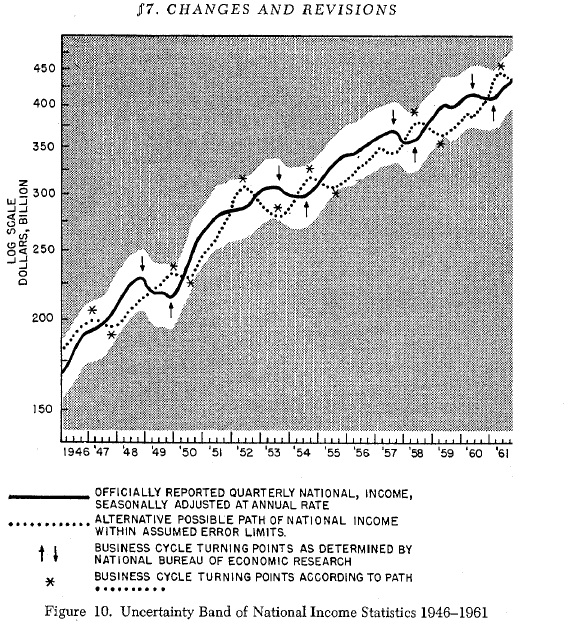
Como dissemos no início do post, os valores publicados nas contas nacionais são daquele tipo de estatística em que uma medida de erro não tem uma fórmula pronta, sendo difícil quantificar a incerteza. Entretanto, Kuznets, à época, reuniu especialistas envolvidos no cálculo do PIB para tentar chegar a uma medida. Resultado: cerca de 10%. Qual a implicação disso? Veja o gráfico abaixo (p.269):

Morgenstern mostra os dados de renda nacional bruta dos EUA, de 1946 a 1961, com o intervalo de 10% de erro. Neste caso, nota-se que os dados servem para analisar o crescimento econômico de longo prazo, mas são bastante duvidosos quanto sua utilidade para se confrontar teorias de ciclos econômicos, pois além dos ciclos divulgados oficialmente (reta contínua do gráfico) outra trajetória, com ciclos opostos, também é consistente com o erro (reta tracejada do gráfico).
Com o avanço da tecnologia, é provável que os dados de hoje não sejam tão incertos quanto os da época. Mas não sabemos em que medida, e isso é fundamental para distinguirmos o que podemos extrair dos dados. Estamos em uma época em que o reconhecimento do erro, da aleatoriedade, e da incerteza está se tornando cada vez mais comum e, talvez, seja hora de tentar resgatar a linha de pesquisa de Morgenstern.
* pelo menos para aqueles que descem do pedestal criado para si em sua própria mente e buscam confrontar ideias, sempre sujeitas a erro, com o que se observa.
** por exemplo, suponha que você tenha dois métodos para medir uma variável, em um deles você sabe que há alta probabilidade de subestimar a medida e, com o outro, alta probabilidade de superestimá-la: qual é melhor?