Com o fim da primeira fase da copa, chegou a hora de começar a comparar os diferentes modelos de previsão. Temos uma amostra que não é grande, mas é, de certa forma, razoável – foram 48 jogos!
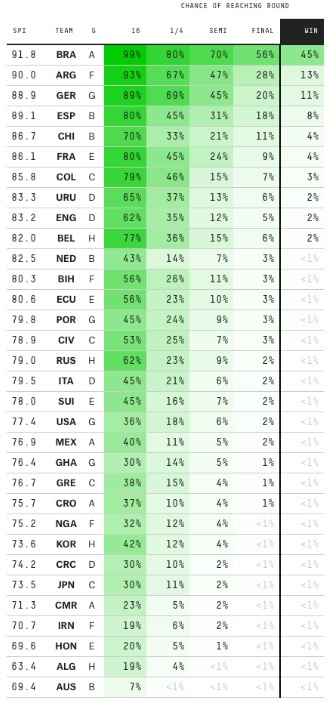
Como comparar previsões? Em post anterior discutimos brevemente como fazer isso, e lá ilustramos com os modelos de Nate Silver e do Grupo de Modelagem Estatística no Esporte (GMEE), da USP/USFCAR.
Entretanto, além desses dois modelos, temos agora mais algumas novidades: como o Nate Silver atualiza suas previsões jogo a jogo, pegamos também aquelas que valiam antes de cada partida. Dessa forma podemos verificar se essas mudanças foram benéficas ou não.
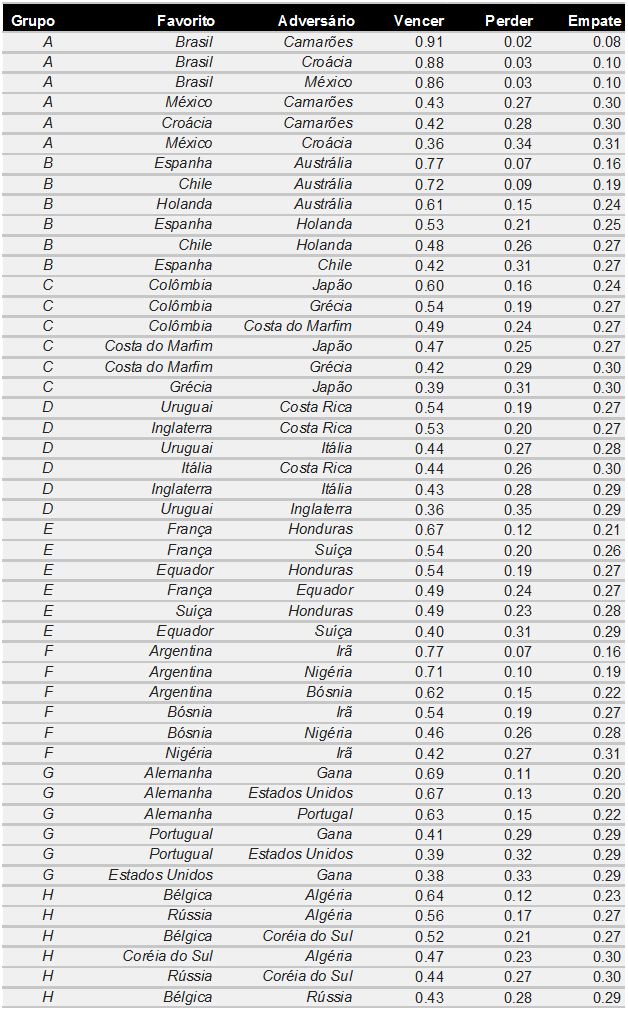
Além disso, com a dica do Pedro Sant’Anna, coletamos as probabilidades implícitas pelo mercado de apostas do Betfair, tanto aquelas que estavam valendo bem antes de todas as partidas, como aquelas que constavam no início do dia de cada jogo.
Temos, portanto, dois benchmarks para nossos previsores. O primeiro é o cético, que acredita que o futebol é muito imprevisível e que qualquer resultado (vitória, derrota ou empate) é equiprovável. Entretanto, se o cético parece um oponente muito fácil, temos também as previsões do Betfair, que podem ser vistas como uma média do senso comum em relação a cada partida, e parecem trazer uma competição mais acirrada.
O gráfico com a evolução do erro médio dia após dia segue abaixo. Note que, quanto menor o erro, melhor. A linha tracejada verde marca o erro médio do cético, nosso benchmark mínimo (0.222). A linha sólida vermelha e a linha tracejada amarela representam o mercado, antes e após atualizar as probabilidades, nosso benchmark mais rigoroso.

Como no primeiro dia só houve um jogo (o do Brasil) que era relativamente mais fácil de acertar, todo mundo começou com um erro muito baixo, e isso deixa a escala do gráfico muito grande para enxergar as diferenças dos dias posteriores. Então vamos dar um zoom na imagem, considerando os valores a partir do dia 14, quando o erro médio dos modelos começa a se estabilizar:

A primeira coisa a se notar é que tanto o Nate Silver quanto o GMEE foram, de maneira consistente, melhores do que o cético e do que mercado. Vale fazer uma pequena ressalva para o GMEE que, hoje, no último dia da primeira fase, se aproximou bastante do Betfair. Nate Silver, contudo, ainda mantém uma distância razoável.
Outra coisa interessante é que o modelo atualizado de Nate Silver realmente terminou com erro menor do que suas previsões no início da competição! É importante ter em mente que isso não é um resultado óbvio: saber como incorporar informações novas na medida que surgem não é algo trivial. Como contra-exemplo temos o mercado, que, surpreendentemente, conseguiu fazer com que suas previsões atualizadas ficassem piores!
Por agora ficamos aqui. Mais para frente veremos alguns gráficos com a calibração dos modelos: será que, quando eles previam 40% de chances de um resultado acontecer, eles aconteceram mais ou menos 40% das vezes?