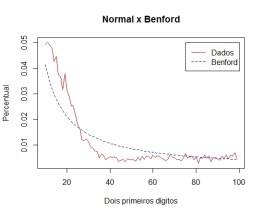
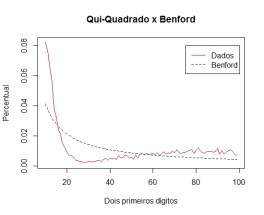
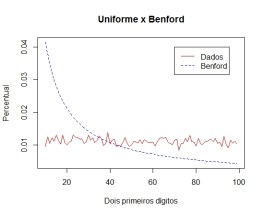
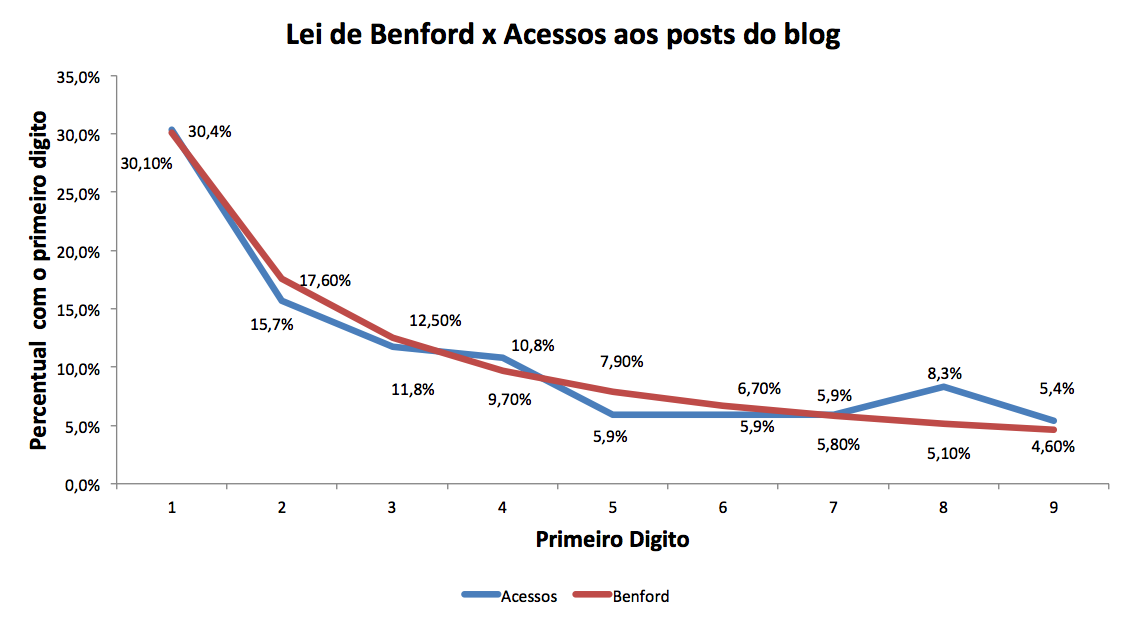
Entrevista com Larry Cahoon, estatístico do Censo norte-americano. Destaco a passagem abaixo, em que ele ressalta a importância de se saber sobre a variabilidade de uma estimativa, algo tão ou mais crítico do que saber a própria estimativa. Isto está em linha com o que discutimos acerca da acurácia das variáveis econômicas, aqui, aqui e aqui.
To do good statistics, knowledge of the subject matter it is being applied to is critical. I also learned early on that issues of variance and bias in any estimate are actually more important than the estimate itself. If I don’t know things like the variability inherent in an estimate and the bias issues in that estimate, then I really don’t know very much.
A favorite saying among the statisticians at the Census Bureau where I worked is that the biases are almost always greater than the sampling error. So my first goal is always to understand the data source, the data quality and what it actually measures.
But, I also still have to make decisions based on the data I have. The real question then becomes given the estimate on hand, what I know about the variance of that estimate, and the biases in that estimate, what decision am I going to make.
Se você não tinha seguido a recomendação de acompanhar o blog do Damodaran, seguem alguns posts interessantes que você perdeu:
– Chill, dude: Debt Default Drama Queens
– When the pieces add-up too much: Micro Dreams and Macro Delusions;
– Twitter announces the IPO: Pricing Games Begins, The Valuation, Why a good trade be a bad investment (or vice-versa).
Sobre o prêmio Nobel, saiu tanta coisa na internet que inclusive descobri muitos detalhes interessantes dos trabalhos dos três ganhadores que sequer imaginava. Deixo aqui, para quem ainda não leu, os materiais do Marginal Revolution e do Cochrane.