Uma antiga, mas excelente, do SMBC:
 Para ver outras relacionadas a economia ou estatística, clique aqui.
Para ver outras relacionadas a economia ou estatística, clique aqui.
Uma antiga, mas excelente, do SMBC:
Para ver outras relacionadas a economia ou estatística, clique aqui.
Está no ar o blog do Nate Silver – FiveThirtyEight!
Nate Silver, economista e estatístico, alçou-se à fama prevendo quantitativamente os resultados das eleições norte americanas, em meio a dezenas de pundits que, de maneira arrogante, erraram grosseiramente. Seu segredo? Dados.
Agora, Nate reuniu uma equipe para dedicar-se ao jornalismo fundamentado na análise rigorosa de dados, tratando dos temas mais variados: além de política, o blog tratará de economia, esportes, ciência e outras questões do dia-a-dia.
Três destaques que você deve conferir:
– Geral: O manifesto de Nate Silver, com uma introdução ao blog.
– Esporte: Esta fantástica tabela com previsões do campeonato de basquete da NCAA, acompanhada da explicação do modelo. Imagine uma dessas para a Copa ou para o Brasileirão?
– Economia: Artigo simples, mas interessante, com três recomendações para avaliar dados econômicos (que muitas vezes são tomados as is). Sobre este assunto, neste blog, veja os pots sobre a acurácia das variáveis econômicas.
Este é um blog promissor, certamente vale a pena acompanhar. E, falando em acompanhar blogs, se você ainda não usa, recomendo fortemente baixar um leitor de RSS, o FiveThirtyEight tem feed.
PS: Você pode encontrar outros posts sobre Nate Silver neste blog aqui.
Por que eu uso R, em 30 segundos:
Qual foi a quantidade de homicídios no EUA em 2010? Três medidas diferentes, com 25% de diferença entre a maior e menor.
12,966, FBI, Crime in the United States 2010.
13,164, FBI, Crime in the United States 2011 (2010 figure).
14,720, Bureau of Justice Statistics (Table 1, based on FBI, Supplementary Homicide Statistics).
16,259, CDC (based on death certificates in the National Vital Statistics System).
Veja mais no Marginal Revolution.
Para saber mais sobre o assunto, veja no blog também aqui , aqui ,aqui, aqui, aqui e aqui.
Em post anterior falamos sobre a Lei de Benford e que ela pode ser utilizada para o auxílio na detecção de fraudes contábeis ou dados estranhos. Também explicamos por que ela surge – resumidamente, pode-se dizer que números que tenham crescimento exponencial, ou que sejam derivados da multiplicação de outros números, tenderiam à lei de Benford – e isto abrange muitos dados econômicos.
Além da Lei de Benford, temos falado bastante sobre o R por aqui. Então, que tal unirmos as duas coisas? Bem, em alguns dias, com o pacote benford.analysis, você poderá analisar facilmente e rapidamente (espero!) seus dados contra a lei de Benford para identificar possíveis erros.
A idéia do pacote é tornar a análise algo rápido e simples. Por exemplo, o gráfico abaixo é gerado com apenas dois comandos: bfd <- benford(dados) e plot(bfd).
 Vamos ver se vai ficar bacana.
Vamos ver se vai ficar bacana.
Atualização: a versão 0.1 está no CRAN.
Já falamos que os p-valores não podem ser interpretados como uma medida absoluta de evidência, como comumente costumam ser. Entre algumas interpretações recorrentes, por exemplo, vale mencionar alguns cuidados:
Dentre outras questões.
Mas o que essas coisas querem realmente dizer? Muitas vezes é difícil entender o conceito sem exemplos (e gráficos) e é isso que pretendemos trazer hoje aqui. Vamos tratar do primeiro ponto listado, uma questão que, muitas vezes, pode confundir o usuário do p-valor: o p-valor pode apresentar evidências de que alguém seja obeso e, ao mesmo tempo, evidências de que este alguém não seja gordo, caso você, por descuido, tome o p-valor como uma medida absoluta de evidência e leve suas hipóteses nulas ao pé da letra. O exemplo abaixo foi retirado do artigo do Alexandre Patriota (versão publicada aqui).
Considere duas amostras aleatórias, com 100 observações cada, de distribuição normal com médias desconhecidas e variância igual 1. Suponha que as médias amostrais calculadas nas duas amostras tenham sido x1=0.14 e x2=-0.16 e que você queira testar a hipótese nula de que ambas as médias populacionais sejam iguais a zero.
A estatística para esta hipótese é n*(x1^2+x2^2), e o valor obtido na amostra é 100*(0.14^2+(-0.16)^2)=4.52. A distribuição desta estatística, sob a hipótese nula, é uma qui-quadrado com 2 graus de liberdade, o que te dá um p-valor de 10%. Assim, se você segue o padrão da literatura aplicada, como o p-valor é maior do que 5%, você dirá que aceita (ou que não rejeita) a hipótese nula de que as médias sejam iguais a zero.
Agora suponha que outro pesquisador teste, com os mesmos dados, a hipótese de que as médias populacionas sejam iguais a si. Para esta hipótese, a estatística seria (n/2)*(x1 – x2)^2, e o valor obtido na amostra é (100/2)*(0.14+0.16)^2= 4.5. A distribuição desta estatística sob a hipótese nula é uma qui-quadrado com 1 grau de liberdade, o que te dá um p-valor de 3%. Caso o pesquisador siga o padrão da literatura aplicada, como o p-valor é menor do que 5% (o tão esperado *), ele dirá que rejeita a hipótese de que as médias sejam iguais.
Mas, espere um momento. Ao concluir que as médias não são iguais, logicamente também se deve concluir que ambas não sejam iguais a zero! Com os mesmos dados, se forem testadas hipóteses diferentes, e se os resultados forem interpretados conforme faz a maior parte da literatura aplicada (que é uma interpretação bastante frágil), você chegará a conclusões aparentemente contraditórias!
Como o p-valor traz “mais evidência” contra a hipótese de que as médias seja iguais do que contra a hipótese de que ambas sejam iguais a zero, tendo em vista que se rejeitarmos a primeira, logicamente temos que rejeitar a segunda? O que está acontecendo?
Para entender melhor, lembremos o que é o p-valor. O p-valor calcula a probabilidade de a estatística de teste ser tão grande, ou maior, do que a estatística de teste observada. Intuitivamente, o p-valor tenta responder a seguinte pergunta: se eu adotasse esta discrepância observada como evidência suficiente para rejeitar a hipótese nula, quantas vezes este teste me levaria a erroneamente rejeitar esta hipótese quando ela é de fato verdadeira. Isto é, o p-valor leva em consideração em seu cálculo todos aqueles resultados amostrais que gerariam estatísticas tão extremas quanto a observada, que poderiam ter ocorrido mas não ocorreram.
Repare como calculamos a estatística 1 e note o termo (x1^2+x2^2). Percebe-se que a estatística se torna mais extrema cada vez que o ponto (x1, x2) se distancia de (0,0) – em qualquer direção. Isto é, ela cresce com relação à distância euclidiana de (x1,x2) em relação ao ponto (0,0). Talvez isso seja mais fácil de entender com imagens. No gráfico abaixo, quanto mais escura a cor, maior é o valor da estatística de teste.
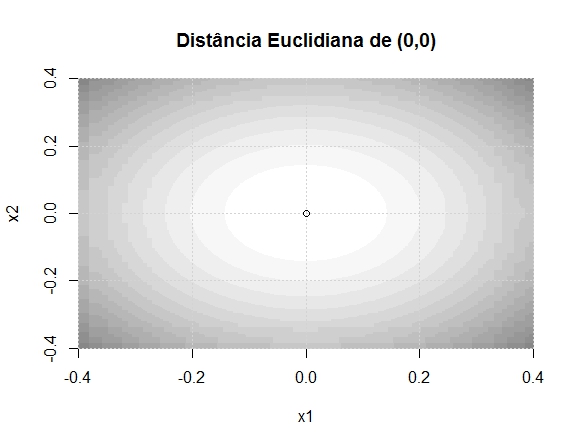
Já na estatística 2, perceba que o termo principal é (x1 – x2)^2, e o que se mede é a distância do ponto em relação à curva x1=x2. Isto é, a distância absoluta de x1 em relação a x2. Vejamos as curvas de nível. Note que ao longo da curva há diversas regiões em branco, mesmo quando distantes do ponto (0,0), pois o que a estatística mede é a distância entre os pontos x1 e x2 entre si.
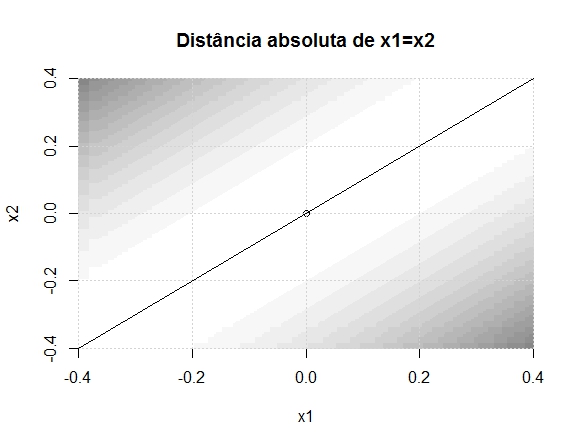
Agora deve ficar mais fácil de entender o que está acontecendo. O p-valor calcula a probabilidade de encontrar uma estatística tão grande ou maior do que a observada. Ao calcular (x1 – x2)^2, todos os pontos que são distantes de (0,0), mas são próximos entre si, não geram estatísticas extremas. Como uma imagem vale mais do que mil palavras, façamos mais uma. No gráfico abaixo, os pontos pretos são todos aqueles cuja estatística de teste supera a estatística observada (0.14, -0.16). Já os pontos azuis e vermelhos são todos os pontos que tem uma estatística de teste maior do que a observada, medidos pela distância euclidiana em relação à reta x1=x2.
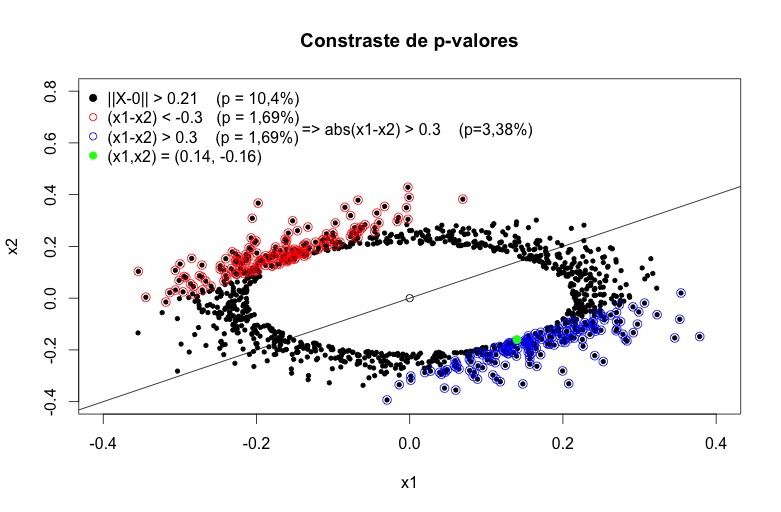 Note que vários pontos pretos que se encontram “longe” de (0,0) não são nem vermelhos nem azuis, pois estão “pertos” da reta x1=x2. Fica claro, portanto, porque o p-valor da segunda estatística é menor. Isso ocorre porque resultados extremos que discordariam bastante de (0,0) – como (0.2, 0.2) ou (0.3, 0.3) – não são considerados em seu cálculo. Note que é possível obter um p-valor ainda menor (1,6%) testanto a hipóse de que média 1 seja menor ou igual à média 2. E se a média 1 não é menor ou igual a média 2, isso implica que elas não são iguais a si, e que também não são ambas iguais a zero. É importante ter claro também que todas as estatísticas são derivadas pelo mesmo método – razão de verossimilhanças – e possuem propriedades ótimas, não são estatísticas geradas ad-hoc para provocar um resultado contra-intutivo.
Note que vários pontos pretos que se encontram “longe” de (0,0) não são nem vermelhos nem azuis, pois estão “pertos” da reta x1=x2. Fica claro, portanto, porque o p-valor da segunda estatística é menor. Isso ocorre porque resultados extremos que discordariam bastante de (0,0) – como (0.2, 0.2) ou (0.3, 0.3) – não são considerados em seu cálculo. Note que é possível obter um p-valor ainda menor (1,6%) testanto a hipóse de que média 1 seja menor ou igual à média 2. E se a média 1 não é menor ou igual a média 2, isso implica que elas não são iguais a si, e que também não são ambas iguais a zero. É importante ter claro também que todas as estatísticas são derivadas pelo mesmo método – razão de verossimilhanças – e possuem propriedades ótimas, não são estatísticas geradas ad-hoc para provocar um resultado contra-intutivo.
Para não alongar muito este post, frise-se que o que deve ser tirado como lição principal é que o p-valor não é uma medida absoluta de suporte à hipótese que está sendo testada. Mas como interpretar melhor os resultados acima? Caso você queira continuar no âmbito frequentista, algumas medidas seriam, por exemplo, não considerar literalmente as hipóteses nulas (isto é, não rejeitar ou aceitar uma hipótese precisa como x1=x2 ou x1=x2=0), avaliar que discrepâncias em relação à hipótese nula são ou não relevantes (do ponto de vista científico, e não estatístico) e conferir a função poder e intervalos de confiança para algumas alternativas de interesse. Trataremos disso mais a frente (caso vocês ainda não tenham enjoado do assunto!).
Entrevista com Larry Cahoon, estatístico do Censo norte-americano. Destaco a passagem abaixo, em que ele ressalta a importância de se saber sobre a variabilidade de uma estimativa, algo tão ou mais crítico do que saber a própria estimativa. Isto está em linha com o que discutimos acerca da acurácia das variáveis econômicas, aqui, aqui e aqui.
To do good statistics, knowledge of the subject matter it is being applied to is critical. I also learned early on that issues of variance and bias in any estimate are actually more important than the estimate itself. If I don’t know things like the variability inherent in an estimate and the bias issues in that estimate, then I really don’t know very much.
A favorite saying among the statisticians at the Census Bureau where I worked is that the biases are almost always greater than the sampling error. So my first goal is always to understand the data source, the data quality and what it actually measures.
But, I also still have to make decisions based on the data I have. The real question then becomes given the estimate on hand, what I know about the variance of that estimate, and the biases in that estimate, what decision am I going to make.
Se você não tinha seguido a recomendação de acompanhar o blog do Damodaran, seguem alguns posts interessantes que você perdeu:
– Chill, dude: Debt Default Drama Queens
– When the pieces add-up too much: Micro Dreams and Macro Delusions;
– Twitter announces the IPO: Pricing Games Begins, The Valuation, Why a good trade be a bad investment (or vice-versa).
Sobre o prêmio Nobel, saiu tanta coisa na internet que inclusive descobri muitos detalhes interessantes dos trabalhos dos três ganhadores que sequer imaginava. Deixo aqui, para quem ainda não leu, os materiais do Marginal Revolution e do Cochrane.
No post anterior falamos da Lei de Benford e que ela surge naturalmente em diversos fenômenos do mundo real, inclusive em dados contábeis e econômicos. Mas não explicamos o porquê. Aqui traremos duas explicações. A primeira, bastante intuitiva, é pensar que estes dados tem crescimento exponencial. Por exemplo, na economia (brasileira), variáveis como o PIB real e os preços crescem entre 2% e 6% ao ano, respectivamente. E como o crescimento exponencial levaria à Lei de Benford?
Suponha que o valor inicial de uma variável seja 10 e que ela tenha uma taxa de crescimento de 10% por período. Veja que, ao crescer exponencialmente, a variável vai demorar 7 períodos para chegar na casa dos 20’s. Todavia, após chegar no 20, ela cresce mais rapidamente, e leva apenas 4 períodos para chegar na casa dos 30’s. Note que esta variável irá ficar apenas um período na casa dos 90’s, para logo em seguida passar mais 7 períodos nos 100’s (e com primeiro digito 1). Parece condizer com a Lei.
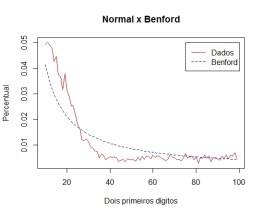
Para verificar, façamos uma simulação, com uma variável que cresça 3% por período. Após 2000 períodos, a distribuição dos dígitos da série segue muito aproximadamente a Lei de Benford (como a amostra é grande, no gráfico utilizamos a distribuição dos dois primeiros dígitos, que tem maior capacidade de discriminação do que apenas a distribuição do primeiro dígito).
 Além do crescimento exponencial, existe, ainda, uma razão mais convincente. Dados contábeis e econômicos também são, em geral, fruto da multiplicação de diversos números. Para saber o valor da produção,por exemplo, multiplicam-se quantidades e preços. E ocorre que a multiplicação de distribuições contínuas tem como distribuição limite um conjunto de Benford. Façamos uma simulação com distribuições normal – N(10,10) – qui-quadrado – Q(3) e uniforme – U(0,1).
Além do crescimento exponencial, existe, ainda, uma razão mais convincente. Dados contábeis e econômicos também são, em geral, fruto da multiplicação de diversos números. Para saber o valor da produção,por exemplo, multiplicam-se quantidades e preços. E ocorre que a multiplicação de distribuições contínuas tem como distribuição limite um conjunto de Benford. Façamos uma simulação com distribuições normal – N(10,10) – qui-quadrado – Q(3) e uniforme – U(0,1).
Perceba que elas, separadamente, não seguem a Lei. Primeiro, a normal:
Agora a Qui-Quadrado:
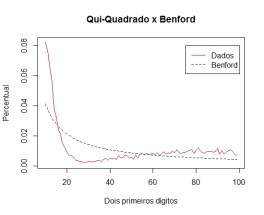
E a Uniforme:
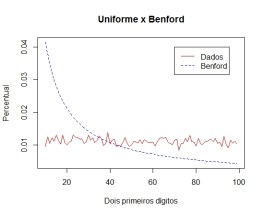
Entretanto, ao multiplicarmos as 3, eis que surge a distribuição dos dígitos!

Chute um valor: quanto seria o percentual de posts deste blog cujo número de acessos se inicia com o número 1?
Sendo mais claro, se o post X tem 10.251 acessos e, o post Y, 152 acessos, o primeiro digito de ambos seria o número 1. Quantos semelhantes a estes, com primeiro digito 1, teríamos em relação ao total? Se extraíssemos todos os primeiros dígitos, haveria algum padrão nesta distribuição? Uma resposta “intuitiva” (mas geralmente errada) é a de que provavelmente haveria tantos posts com números iniciais 1, quanto com números 2 ou 9. Mas quem já ouviu falar da Lei de Benford saberia que, muito provavelmente, não seria isso o observado. Haveria mais ou menos 30% de números 1, seguidos de 17% de números 2 e, após, 12% de números 3, decaindo até mais ou menos 5% de números 9.
Passemos aos dados para verificar se esta tendência realmente se confirma:
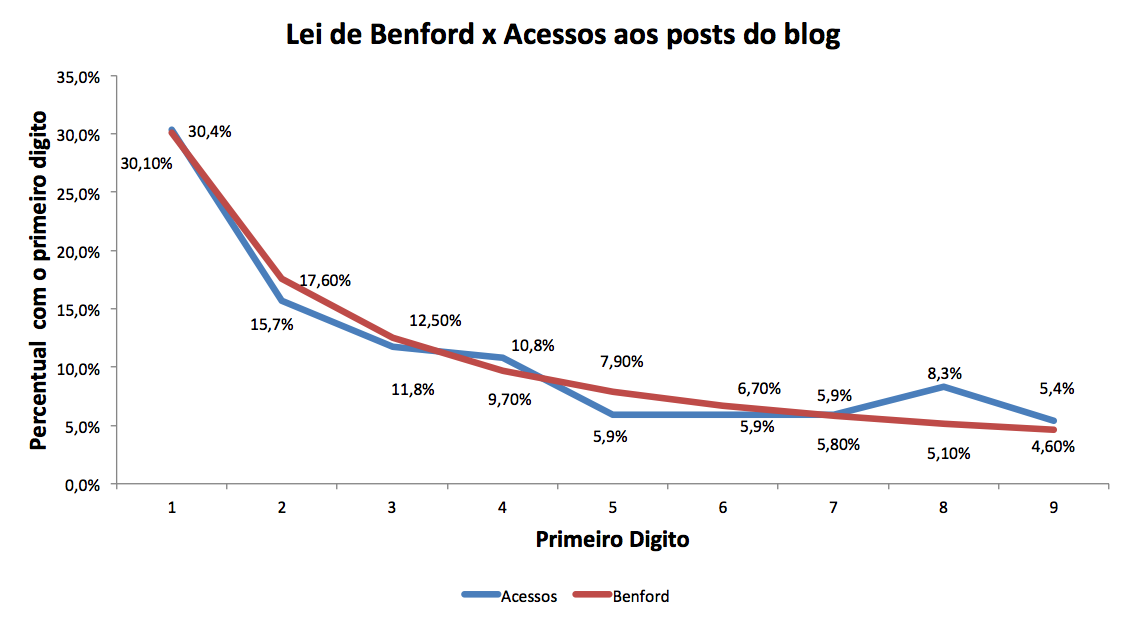
Funciona. E o interessante é que isto ocorre não somente neste blog, mas nas mais diversas estatísticas do mundo real.
A Lei de Benford é assim chamada por conta do – cada vez mais famoso – artigo de Frank Benford, The Law of Anomalous Numbers. Segundo Benford, o insight para investigar este resultado é curioso. Aparentemente, nas tabelas de logaritmos, as páginas mais desgastadas eram aquelas cujos números tinham primeiro digito 1 (em 1930, estas tabelas eram bastante utilizadas para facilitar operações de multiplicação). Com uma base de dados de 20.000 observações dos mais diversos fatos da natureza (tamanhos de rio, população de cidades, constantes da física, taxa de mortalidade etc), Benford verificou que, em cada uma delas, a distribuição dos dígitos seguia este mesmo padrão.
O resultado investigado por Benford não define apenas uma distribuição para os primeiros dígitos, conforme ilustrado no gráfico acima, mas uma distribuição para todos os dígitos significativos de um número. Mais formalmente, um conjunto de números que siga a Lei de Benford teria a mantissa de seus logaritmos uniformemente distribuída. Para o economista isto importaria pelo seguinte motivo – como grande parte dos dados econômicos e contábeis seguem (aproximadamente) esta distribuição, dados errados, inventados ou fraudados poderiam ser identificados por desvios dos valores esperados pela Lei de Benford. Interessante, não? Espero que sim, pois trataremos mais disto em posts futuros.
Vai ocorrer na Universidade de Brasília, entre 05 a 08 de novembro de 2013.
As submissões de trabalho já se encontram abertas, até o dia 02/09 e as inscrições, até o dia 01/11.

