Uma antiga, mas excelente, do SMBC:
 Para ver outras relacionadas a economia ou estatística, clique aqui.
Para ver outras relacionadas a economia ou estatística, clique aqui.
Uma antiga, mas excelente, do SMBC:
Para ver outras relacionadas a economia ou estatística, clique aqui.
Está no ar o blog do Nate Silver – FiveThirtyEight!
Nate Silver, economista e estatístico, alçou-se à fama prevendo quantitativamente os resultados das eleições norte americanas, em meio a dezenas de pundits que, de maneira arrogante, erraram grosseiramente. Seu segredo? Dados.
Agora, Nate reuniu uma equipe para dedicar-se ao jornalismo fundamentado na análise rigorosa de dados, tratando dos temas mais variados: além de política, o blog tratará de economia, esportes, ciência e outras questões do dia-a-dia.
Três destaques que você deve conferir:
– Geral: O manifesto de Nate Silver, com uma introdução ao blog.
– Esporte: Esta fantástica tabela com previsões do campeonato de basquete da NCAA, acompanhada da explicação do modelo. Imagine uma dessas para a Copa ou para o Brasileirão?
– Economia: Artigo simples, mas interessante, com três recomendações para avaliar dados econômicos (que muitas vezes são tomados as is). Sobre este assunto, neste blog, veja os pots sobre a acurácia das variáveis econômicas.
Este é um blog promissor, certamente vale a pena acompanhar. E, falando em acompanhar blogs, se você ainda não usa, recomendo fortemente baixar um leitor de RSS, o FiveThirtyEight tem feed.
PS: Você pode encontrar outros posts sobre Nate Silver neste blog aqui.
Faz mais ou menos 1 mês que o pacote benford.analysis 0.1 foi disponibilizado no CRAN.
Achei que valeria o esforço adicional de criar o pacote por alguns motivos e, entre eles, dois se destacam: (i) pacotes deixam os arquivos fontes mais estruturados, facilitam o uso das funções, forçam a criar uma documentação e passam por uma bateria de sanity tests que ajudam a criar boas práticas de programação; (ii) pacotes tornam o compartilhamento do código extremamente simples, ainda mais se o pacote estiver no CRAN, pois, basta rodar
install.packages("benford.analysis")
e qualquer pessoa de qualquer lugar do mundo terá o pacote instalado em sua máquina.
Sobre este último ponto, infelizmente, não é possível ter dados de download do CRAN de uma maneira consolidada, pois há diversos espelhos do site ao redor do mundo e nem todos guardam informações de acesso. Entretanto, o CRAN do RStudio faz esse registro. Assim resolvi baixar os dados de lá e ver se alguma outra alma além de mim baixou o benford.analysis.
Sinceramente, eu achei que encontraria uns 10 ou 11 downloads registrados – no máximo -, pois estamos com dados de apenas um espelho do CRAN e estamos falando de um pacote simples e relativamente desconhecido. Ocorre que neste 1 mês de existência o benford.analysis foi baixado 190 vezes em mais de 40 países diferentes considerando apenas o espelho do RStudio. Um número pequeno quando comparado com pacotes como ggplot2 (que deve estar em virtualmente quase toda máquina de usuário do R), mas, ainda assim, grande o suficiente para me surpreender!
E também para me preocupar. Nesse meio tempo encontrei dois pequenos bugs no pacote. E se antes achava que não deveria ter pressa para corrigi-los, agora esperem uma atualização em breve (mas, claro, depois do carnaval)!
Em post anterior fizemos uma breve análise dos dados de aluguel no plano piloto.
Agora, que tal navegar por todos imóveis em um mapa da cidade, vendo a localização, tamanho, número de quartos e valor do aluguel? Clique aqui ou na mapa abaixo para navegar.
Atenção, ainda é um protótipo!
Se o mapa não aparecer na sua tela, provavelmente o seu navegador bloqueou a execução do javaScript. Procure por um cadeado no navegador (canto superior direito ou esquerdo, geralmente) e autorize o carregamento do site.
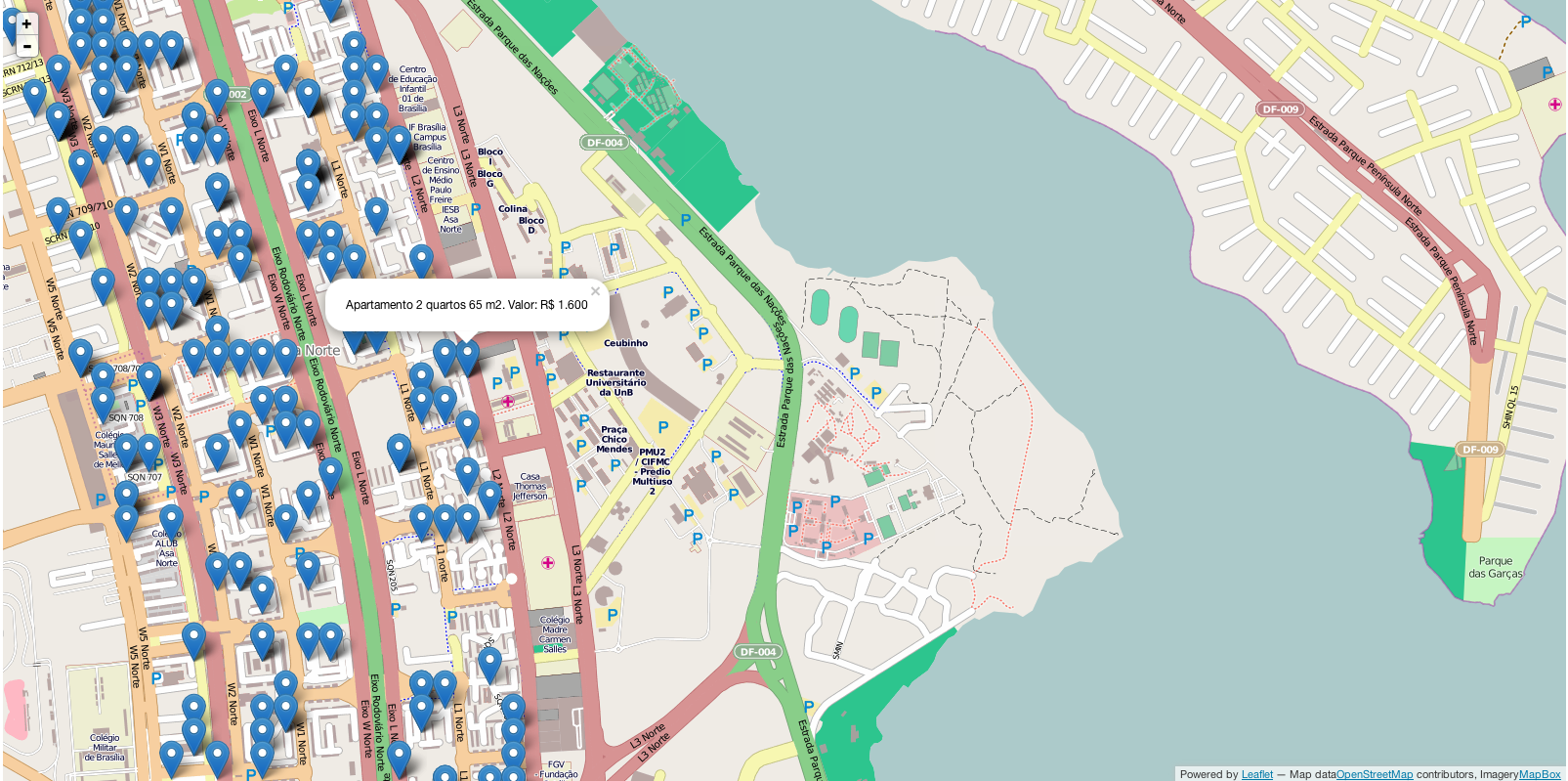
PS: agora já estamos coletando diariamente e automaticamente preços online de imóveis dos principais sites e das principais capitais do país. Ainda estamos testando métodos de análise e visualização.
Por que eu uso R, em 30 segundos:
O time de análise de dados do Facebook fez uma série de 6 posts sobre o valentine’s day (dia dos namorados) nos Estados Unidos.
Recomendo fortemente a leitura de todos. O posts tratam dos seguintes temas:

Os dados confirmam aquilo que você já percebia: casais recém formados postam sobre unicórnios vomitando arco-iris e o efeito pode durar muito, muito tempo (destaque para o gráfico feito com ggplot2).
O Facebook é, muito provavelmente, a organização com a maior base de dados sobre informações pessoais do mundo. O potencial disso é inimaginável. No final do ano passado, eles contrataram o professor da NYU Yann LeCun para liderar o departamento de inteligência articial da empresa – parece que ainda há muita coisa interessante por esperar.
Mais sobre análise de dados do Facebook neste blog, aqui (analise seus próprios dados) e aqui (descubra características da pessoa – como a orientação sexual – com base no que ela curte).
Mais um post no excelente analyze survey data for free, agora com a PME.
Parabéns ao Anthony Damico e ao Djalma Pessoa pela iniciativa!
Está pesquisando apartamento para alugar em Brasília? Um pouco de web scraping, manipulação e visualização de dados com os valores (de oferta) dos aluguéis de 1.030 imóveis (Asa Sul, Asa Norte e Sudoeste) do site wimoveis pode ajudar a responder algumas perguntas interessantes.
A primeira delas: qual o bairro mais caro para se alugar, hoje, no plano piloto? Esta é uma pergunta que, veremos, depende do ponto de vista. Veja a tabela abaixo (versão ampliada aqui). M2 quer dizer metro quadrado e pm2 preço por metro quadrado.

Na média e mediana – em conformidade com a impressão pessoal de muitos – a Asa Sul é o bairro mais caro para se alugar dos três. Entretanto, note que isso ocorre porque há mais apartamentos maiores para aluguel na Asa Sul, e não porque o valor por metro quadrado é mais caro. Na verdade, o valor por metro quadrado, na média, é maior na Asa Norte e, na mediana, maior no Sudoeste.
Podemos agora decompor a tabela acima não somente por bairro, mas por bairro e número de quartos (versão ampliada aqui) . Na média, o bairro mais barato/caro para morar não é o mesmo a depender de quantos cômodos você quer no apartamento. E, uma curiosidade: na amostra, a média do tamanho dos apartamentos da Asa Norte, em todos os grupos de números de quartos, é menor do que a média do tamanho da Asa Sul.

Uma última forma de visualizar as diferenças de preços pode ser com um gráfico de densidade (versão ampliada aqui):

Veja que o pico do Sudoeste (em verde) é em valores mais altos do que na Asa Norte e na Asa Sul. Entretanto, a Asa Sul tem a “cauda” mais pesada em valores próximos a R$ 5.000.
Uma outra pergunta que podemos tentar responder é a seguinte: dos anúncios que temos hoje, na média, os preços daqueles atualizados em 2014 são maiores do que aqueles cuja última atualização foi feita em dezembro de 2013? Pelo quadro abaixo (versão ampliada aqui), infelizmente, sim, e por mais ou menos RS$100,00.

E como é a concentração da oferta dos anúncios por corretora? A distribuição de anúncios por imobiliária é homogênea?
Aparentemente, não. Veja o gráfico abaixo (versão ampliada aqui).
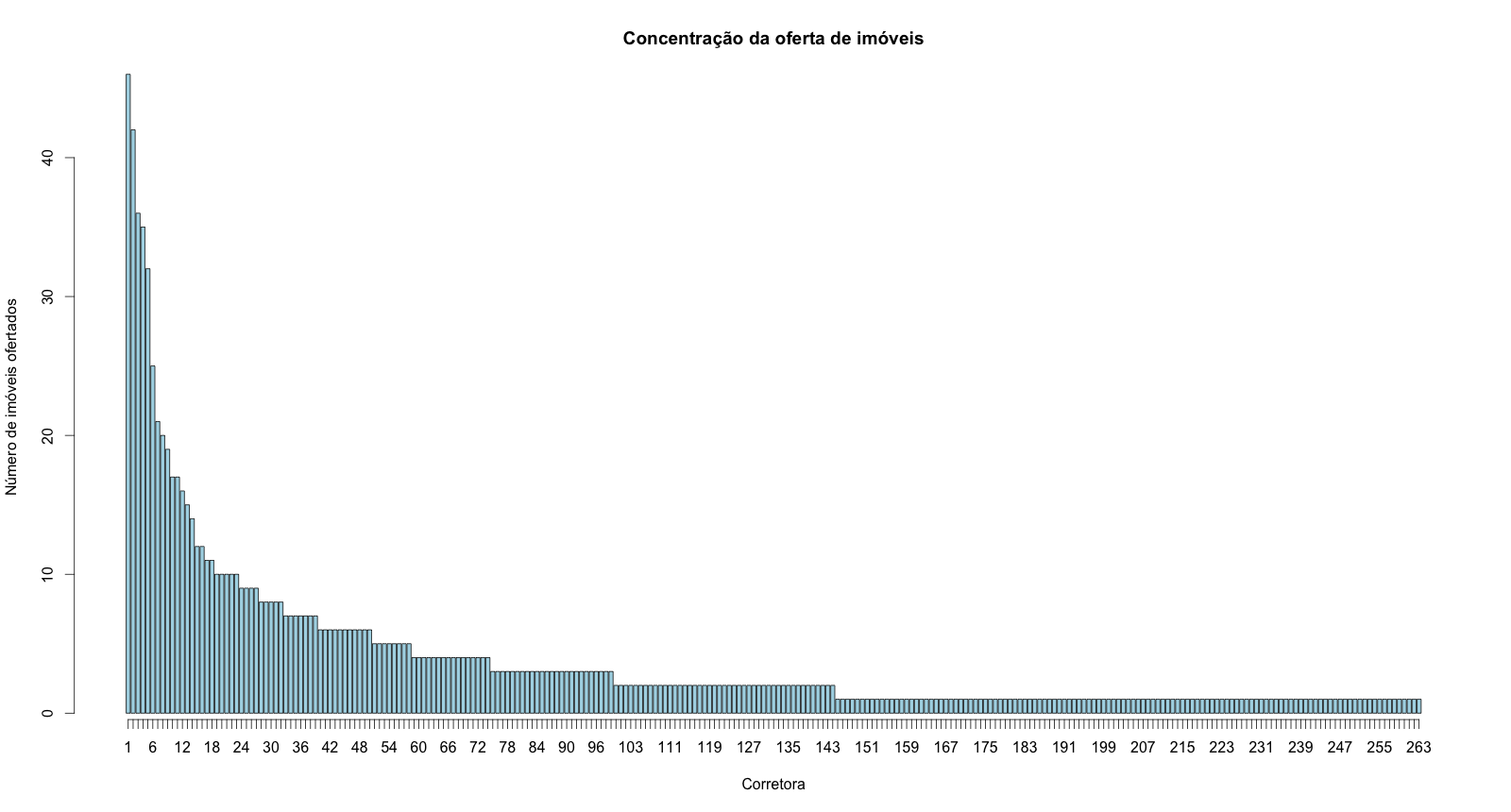
Enquanto algumas imobiliárias têm 30 a 40 apartamentos listados, muitas outras têm apenas 1 ou 5.
Isso quer dizer que os anúncios são concentrados? Não necessariamente. Note que apesar de a distribuição de anúncios não ser homogênea, a concorrência é bem grande, e usando como exemplo o índice de Herfindahl–Hirschman chegamos a um valor de 0.013, comumente considerado indicador de alta competitividade.
Há mais que poderíamos ver sobre aluguel. Mas deixemos para depois. No próximo (em algum próximo) post veremos os dados de valor de venda!
PS: iremos acompanhar regularmente esses preços. E não somente para Brasília. Uma área específica do blog será criada para isso.
Os autoritários: E os libertários (em inglês):
E os libertários (em inglês):

Via information liberation, lefty cartoons e Economistas X (versão em português).
O pacote benford.analysis (versão 0.1) está disponível no CRAN e você já pode instalar no R com o comando:
install.packages("benford.analysis")
O objetivo do pacote é prover algumas funções que facilitem a validação de dados utilizando a Lei de Benford (para saber mais sobre a lei, veja aqui e aqui).
Validar como e para quê?
Um dos objetivos pode ser o auxilío na detecção de manipulações contábeis. Dados financeiros (como pagamentos) tendem a seguir a Lei de Benford e tentativas de manipulação podem acabar sendo identificadas.
Por exemplo, a lei 8.666/93 estabelece que o limite para se fazer uma licitação na modalidade convite é de R$80.000,00. Será que os valores de licitações seguiriam a Lei de Benford? Pode ser que sim. E, caso haja a tendência, uma tentativa de manipular artificialmente valores licitados para algo pouco abaixo de R$80 mil geraria um “excesso” de dígitos iniciais 7. Restaria verificar uma amostra desses registros para confirmar a existência ou não de manipulação indevida.
Outro objetivo pode ser acadêmico: a validação de dados de pesquisas e censos. Por exemplo, dados de população de municípios, ou dados de renda dos indivíduos tendem a ter distribuição conforme a lei de Benford. Assim, desvios dos valores observados em relação aos valores esperados podem ajudar a identificar e corrigir dados anômalos, melhorando a qualidade da estatística.
Vejamos rapidamente alguns exemplos das funções básicas do pacote.
O benford.analysis tem 6 bases de dados reais, retiradas do livro do Mark Nigrini, para ilustrar as análises. Aqui vamos utilizar 189.470 registros de pagamentos de uma empresa no ano de 2010. Os valores vão desde lançamentos negativos (estornos) até valores na ordem de milhões de dólares.
Primeiramente, precisamos carregar o pacote (se você já o tiver instalado) e em seguida carregar os dados de exemplo:
library(benford.analysis) #carrega pacote data(corporate.payment) #carrega dados
Para analisar os dados contra a lei de benford, basta aplicar a função benford nos valores que, no nosso caso, estão na coluna ‘Amount’.
bfd.cp <- benford(corporate.payment$Amount)
Com o comando acima criamos um objeto chamado “bfd.cp” contendo os resultados da análise para os dois primeiros dígitos dos lançamentos positivos, que é o padrão. Caso queira, você também pode mudar quantos digitos deseja analisar, ou se quer analisar os dados negativos e positivos juntos, entre outras opções. Para mais detalhes, veja a ajuda da função:
?benford
Com a análise feita, vejamos os principais gráficos com o comando:
plot(bfd.cp)
Os gráficos resultantes se encontram abaixo. Os dados da empresa estão em azul e os valores esperados pela lei de benford em vermelho.
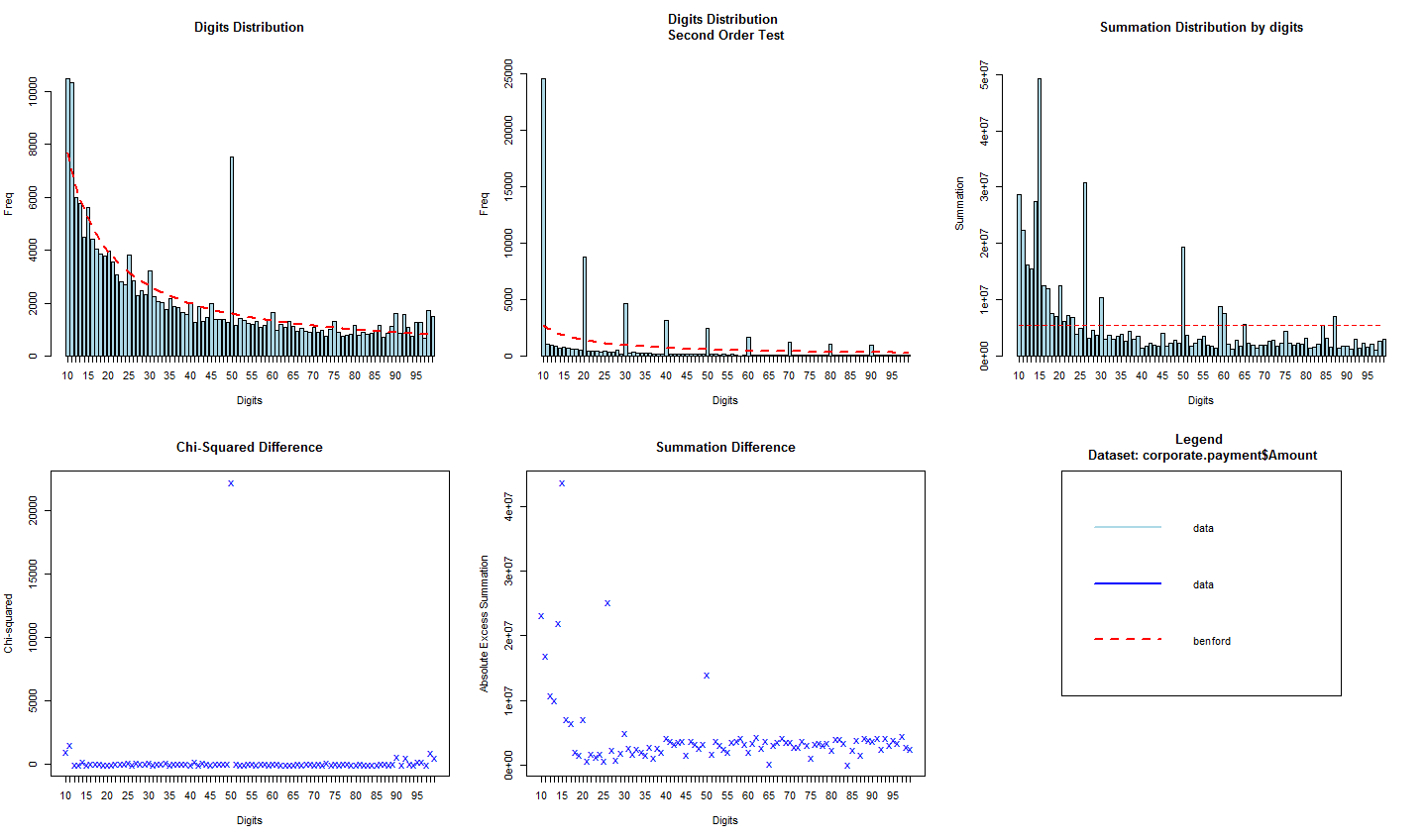
O primeiro gráfico diz respeito à contagem de observações com relação aos seus dois primeiros dígitos, comparando-a com o valor esperado pela Lei de Benford. Percebe-se que os dados da empresa se ajustam à Lei, mas, também, que há um salto claro no dígito 50!
O segundo gráfico é análogo ao primeiro, mas faz esta contagem para a diferença dos dados ordenados. Como nossos dados são discretos, este saltos em 10, 20, 30, são naturais e não devem ser encarados como algo suspeito. Por fim, o terceiro gráfico tem um objetivo diferente e, em geral, você também não deve esperar encontrar um bom ajuste dos dados à reta vermelha, principalmente com dados de cauda pesada. Ali se encontra a soma dos valores das observações agrupadas por primeiros dígitos e a intenção é identificar grupos de valores influentes (que, se estiverem errados, podem afetar bastante uma estatística).
Vejamos agora os principais resultados da análise com o comando
print(bfd.cp)
ou somente
bfd.cp

Primeiramente são mostrados dados gerais da análise, como o nome da base de dados, o número de observações e a quantidade de primeiros dígitos analisados.
Logo em seguida têm-se as principais estatísticas da mantissa do log das observações. Se um conjunto de dados segue a lei de benford esses valores deveriam ser próximos de:
Que são, de fato, similares aos dados de pagamento da empresa, confirmando a tendência.
Após isso, temos um ranking com os 5 maiores desvios, que é o que mais nos interessa aqui. Veja que o primeiro grupo é o dos números que começam com o dígito 50, como estava claro no gráfico, e o segundo grupo é o dos números que começam com 11. Esses registros são bons candidatos para uma análise mais minuciosa.
Por fim, temos um conjunto de estatísticas de grau de ajuste – que não irei detalhar agora para não prolongar muito este post. Tomemos como exemplo o teste de Pearson, que é bem conhecido. Veja que o p-valor do qui-quadrado é praticamente zero, sinalizando um desvio em relação ao esperado. Mas, como já dissemos várias vezes neste blog, o mais importante não é saber se os dados seguem ou não a lei de benford exatamente. Para isso você não precisaria sequer testá-los. O mais importante é verificar qual o tamanho do desvio e a sua importância prática. Assim, há um pequeno aviso ao final: Real data will never conform perfectly to Benford’s Law. You should not focus on p-values!
Voltando, portanto, à identificação dos desvios, você pode pegar os conjuntos dos dados “suspeitos” para análise com a função getSuspects.
suspeitos <- getSuspects(bfd.cp, corporate.payment)
Isto irá gerar uma tabela com os dados dos 2 grupos de dígitos com maior discrepância (pela diferença absoluta), conforme ilustrado abaixo. Veja que são exatamente os dados que começam com 50 ou 11. Você pode personalizar qual a métrica de discrepância utilizar e também quantos grupos analisar. Para mais detalhes veja a ajuda da função:
?getSuspects

Note que nossa base de dados é de mais de 189 mil observações. Verificar todos os dados seria infactível. Poderíamos analisar uma amostra aleatória desses dados. Mas, não necessariamente isso seria eficiente. Veja, assim, que a análise de benford, com apenas os dois primeiros dígitos, nos deu um grupo de dados suspeitos com menos de 10% das observações, permitindo um foco mais restrito e talvez mais efetivo para análise.
Há outras funcionalidades no pacote e na ajuda há exemplos com dados reais. O pacote é bem simples, o intuito é fornecer um mínimo de funções que automatize os procedimentos, facilite a vida e minimize a quantidade de caracteres digitados de quem queira fazer a análise. Algumas funcionalidades que serão adicionadas no futuro são: melhoria na parte gráfica com o Lattice, inclusão de comparação dos dados com a lognormal e inclusão de mais dados de exemplo.
Se encotrar algum bug, tiver alguma dúvida ou se quiser deixar alguma sugestão, comente aqui!
PS: com relação às sugestões, tanto o R quanto este pacote são livres e com código aberto. Então, sinta-se à vontade não somente para sugerir, mas principalmente para escrever novas funções e funcionalidades!
